[toc]
1. 数据结构
索引结构与mysql的一样, 都是使用B+tree
只是oracle这里叫bTree
如果存储结构是索引组织表, 才和mysql一样
Oracle中索引的原理 - 想飞_毛毛虫 - 博客园 (cnblogs.com)
2. 失效场景
与mysql的基本一致
3. 执行计划
获取执行计划的方法
6种方法:
1. explain plan for获取(即PL/SQL中的F5);
2. set autotrace on (跟踪性能统计);
3. statistics_level=all(获取表访问次数);
4. 通过dbms_xplan.display_cursor输入sql_id参数直接获取
5. 10046 trace跟踪
6. awrsqrpt.sql
各自的适用场景:
1.如果某SQL执行非常长时间才会出结果,甚至慢到返回不了结果,这时候看执行计划就只能用方法1,或者方法4调用现成的;
2.跟踪某条SQL最简单的方法是方法1,其次就是方法2;
3.如果想观察到某条SQL有多条执行计划的情况,只能用方法4和方法6;
4.如果SQL中含有多函数,函数中套有SQL等多层递归调用,想准确分析,只能使用方法5;
5.要想确保看到真实的执行计划,不能用方法1和方法2;
6.要想获取表被访问的次数,只能使用方法3;
重点讲一下第一种
EXPLAIN PLAN FOR命令不会运行 SQL 语句,因此创建的执行计划不一定与执行该语句时的实际计划相同。
该命令会将生成的执行计划保存到全局的临时表 PLAN_TABLE 中,然后使用系统包 DBMS_XPLAN 中的存储过程格式化显示该表中的执行计划。
使用步骤
步骤1:explain plan for “你的SQL”
步骤2:select * from table(dbms_xplan.display());
案例介绍

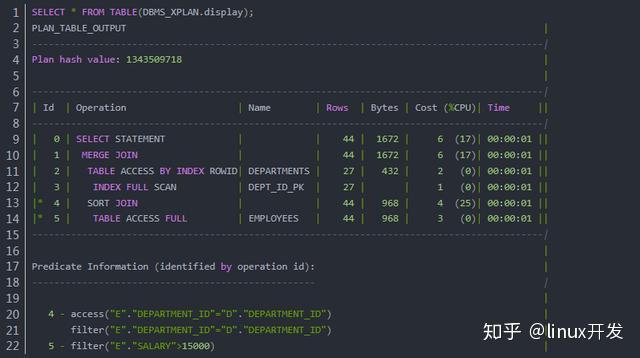
接下来,我们同样需要理解执行计划中各种信息的含义:
Plan hash value 是该语句的哈希值。SQL 语句和执行计划会存储在库缓存中,哈希值相同的语句可以重用已有的执行计划,也就是软解析;
Id 是一个序号,但不代表执行的顺序。执行的顺序按照缩进来判断,缩进越多的越先执行,同样缩进的从上至下执行。Id 前面的星号表示使用了谓词判断,参考下面的 Predicate Information;
Operation 表示当前的操作,也就是如何访问表的数据、如何实现表的连接、如何进行排序操作等;
Name 显示了访问的表名、索引名或者子查询等,前提是当前操作涉及到了这些对象;
Rows 是 Oracle 估计的当前操作返回的行数,也叫基数(Cardinality);
Bytes 是 Oracle 估计的当前操作涉及的数据量
Cost (%CPU) 是 Oracle 计算执行该操作所需的代价;
Time 是 Oracle 估计执行该操作所需的时间;
Predicate Information 显示与 Id 相关的谓词信息。access 是访问条件,影响到数据的访问方式(扫描表还是通过索引);filter 是过滤条件,获取数据后根据该条件进行过滤。
在上面的示例中,Id 的执行顺序依次为 3 -> 2 -> 5 -> 4- >1。首先,Id = 3 扫描主键索引 DEPT_ID_PK,Id = 2 按主键 ROWID 访问表 DEPARTMENTS,结果已经排序;其次,Id = 5 全表扫描访问 EMPLOYEES 并且利用 filter 过滤数据,Id = 4 基于部门编号进行排序和过滤;最后 Id = 1 执行合并连接。显然,此处 Oracle 选择了排序合并连接的方式实现两个表的连接。