[TOC]
1. 什么是多版本并发控制( MVCC )
MySQL 的大多数事务型存储引擎基于提升并发性能的考虑,一般都实现了多版本并发控制( MVCC )。MVCC 是行级锁的一个变种,但实际上实现机制有所不同,避免了加锁的操作,因此有了更低的开销和更高的性能。
MVCC 的实现,是通过保持数据在某个时间点的快照来实现的,不管事务的执行时间有多久,MVCC 保障了每一个事务内看到的数据是一致的,而根据事务开始时间,不同事务看到同一张表,同一份数据可能是不同的。 MVCC的实现,是通过保存数据在某个时间点的快照来实现的。
需要注意的是,MVCC只在REPEATABLE READ和READ COMMITTED两个隔离级别下工作,其他两个级别都和MVCC“不兼容”。因为READ UNCOMMITTED总是读取最新的数据行,而SERIALIZABLE则会对所有读取的行都加锁。
保存这两个额外的系统版本号,使大多数的读操作都不用加锁,这样的设计使得读数据操作很简单,性能很好,并且只会读取到符合标准的行。不足之处是每行记录都需要额外的存储空间,需要做更多额外的检查工作和维护工作。
不同存储引擎对 MVCC 的实现机制不尽相同,因为 MVCC 并没有一个统一的标准,下面以 InnoDB 为例,简要介绍 MVCC 的实现原理。
注: 多版本并发控制不支持myisam存储引擎。估计是因为myism是锁整个表,做不到版本控制
2. InnoDB 中的 MVCC
InnoDB 中的 MVCC,是通过在每行记录后保存两个隐藏的列来实现的。这两个特殊的列一个保存了行的创建时间,一个保存了行的删除时间。当然这里存储的并不是真实的时间,实际上存储的是版本号( system version number )。每次开启一个新的事务,系统版本号会开始递增并分配给当前的事务,用于与数据的版本号进行比较。简要介绍下 InnoDB 是如何操作的:
- SELECT:在 InnoDB 中,SELECT 操作有两个额外的条件:
- 只查找行的创建版本号小于或等于当前事务版本号的数据。这样可以保证事务读取的数据要么是在事务开始之前就已经存在,要么是事务本身插入或者修改过的。
- 行的删除版本号要么未定义,要么大于当前事务的版本号。这样是为了确保事务读取的数据在事务开始之前未被删除。
- INSERT:InnoDB 为每行新增数据设置了当前事务的版本号作为创建版本号,删除版本号留空。
- DELETE:InnoDB 为每行删除的数据设置了当前事务的版本号作为删除版本号。
- UPDATE:InnoDB 额外插入一条新的记录,将当前事务版本号作为新记录的创建版本号,同时保存当前事务版本号到原来的数据中的删除版本号。
在 InnoDB 中,MVCC 只在 READ COMMITTED 和 REPEATABLE READ 这两个隔离级别下工作。其他的隔离级别和 MVCC 并不兼容,READ UNCOMMITTED 总是读取最新的数据,而 SERIALIZABLE 则会对所有读取的行都进行加锁操作。
来自: https://blog.csdn.net/qq_35499060/article/details/83590723
以上为简版描述, 但不准确
2.1 基本概念
MVCC实现原理主要是依赖记录中的 3个隐式字段,undo日志 , Read View 来实现的。
隐式字段
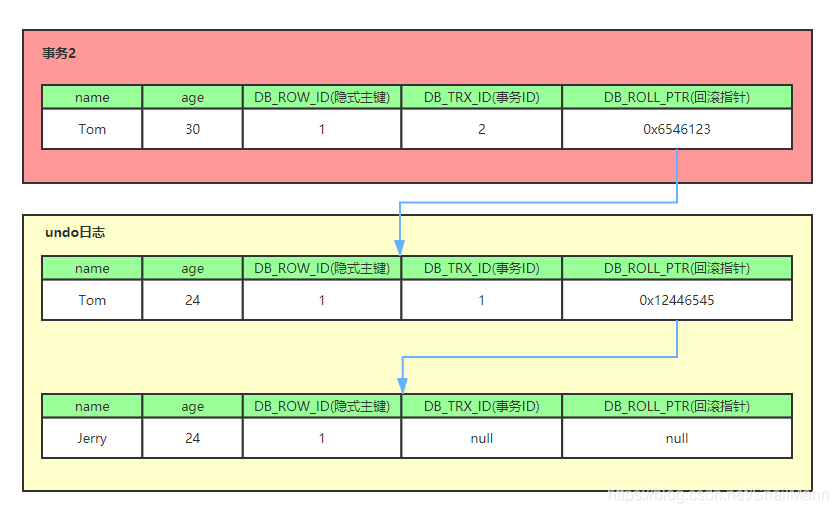
每行记录除了我们自定义的字段外,还有数据库隐式定义的 DB_TRX_ID, DB_ROLL_PTR, DB_ROW_ID 等字段
DB_TRX_ID6 byte,最近修改(修改/插入)事务 ID:记录创建这条记录/最后一次修改该记录的事务 IDDB_ROLL_PTR7 byte,回滚指针,指向这条记录的上一个版本地址(存储于 rollback segment 里)DB_ROW_ID6 byte,隐含的自增 ID(隐藏主键),如果数据表没有主键,InnoDB 会自动以DB_ROW_ID产生一个聚簇索引
实际还有一个删除 flag 隐藏字段, 既记录被更新或删除并不代表真的删除,而是删除 flag 变了
 如上图,
如上图,DB_ROW_ID 是数据库默认为该行记录生成的唯一隐式主键,DB_TRX_ID 是当前操作该记录的事务 ID ,而 DB_ROLL_PTR 是一个回滚指针,用于配合 undo日志,指向上一个旧版本
undo日志
undo log 主要分为两种:
insert undo log
代表事务在 insert 新记录时产生的 undo log, 只在事务回滚时需要,并且在事务提交后可以被立即丢弃
update undo log
事务在进行 update 或 delete 时产生的 undo log ; 不仅在事务回滚时需要,在快照读时也需要;所以不能随便删除,只有在快照读或事务回滚 不涉及该日志时,对应的日志才会被 purge 线程统一清除
purge
从前面的分析可以看出,为了实现 InnoDB 的 MVCC 机制,更新或者删除操作都只是设置一下老记录的 deleted_bit ,并不真正将过时的记录删除。
为了节省磁盘空间,InnoDB 有专门的 purge 线程来清理 deleted_bit 为 true 的记录。为了不影响 MVCC 的正常工作,purge 线程自己也维护了一个read view(这个 read view 相当于系统中最老活跃事务的 read view );如果某个记录的 deleted_bit 为 true ,并且 DB_TRX_ID 相对于 purge 线程的 read view 可见,那么这条记录一定是可以被安全清除的。
因此衍生一个面试题, undo log有什么用途呢?
- 事务回滚时使用,保证原子性和一致性。
- 用于MVCC快照读。
版本链
多个事务并行操作某一行数据时,不同事务对该行数据的修改会产生多个版本,然后通过回滚指针(roll_pointer),连成一个链表,这个链表就称为版本链
快照读和当前读
快照读: 读取的是记录数据的可见版本(有旧的版本)。不加锁,普通的select语句都是快照读,如:
select * from core_user where id > 2;
当前读:读取的是记录数据的最新版本,显式加锁的都是当前读
select * from core_user where id > 2 for update;
select * from account where id > 2 lock in share mode;
Read View 和可见性规则判断
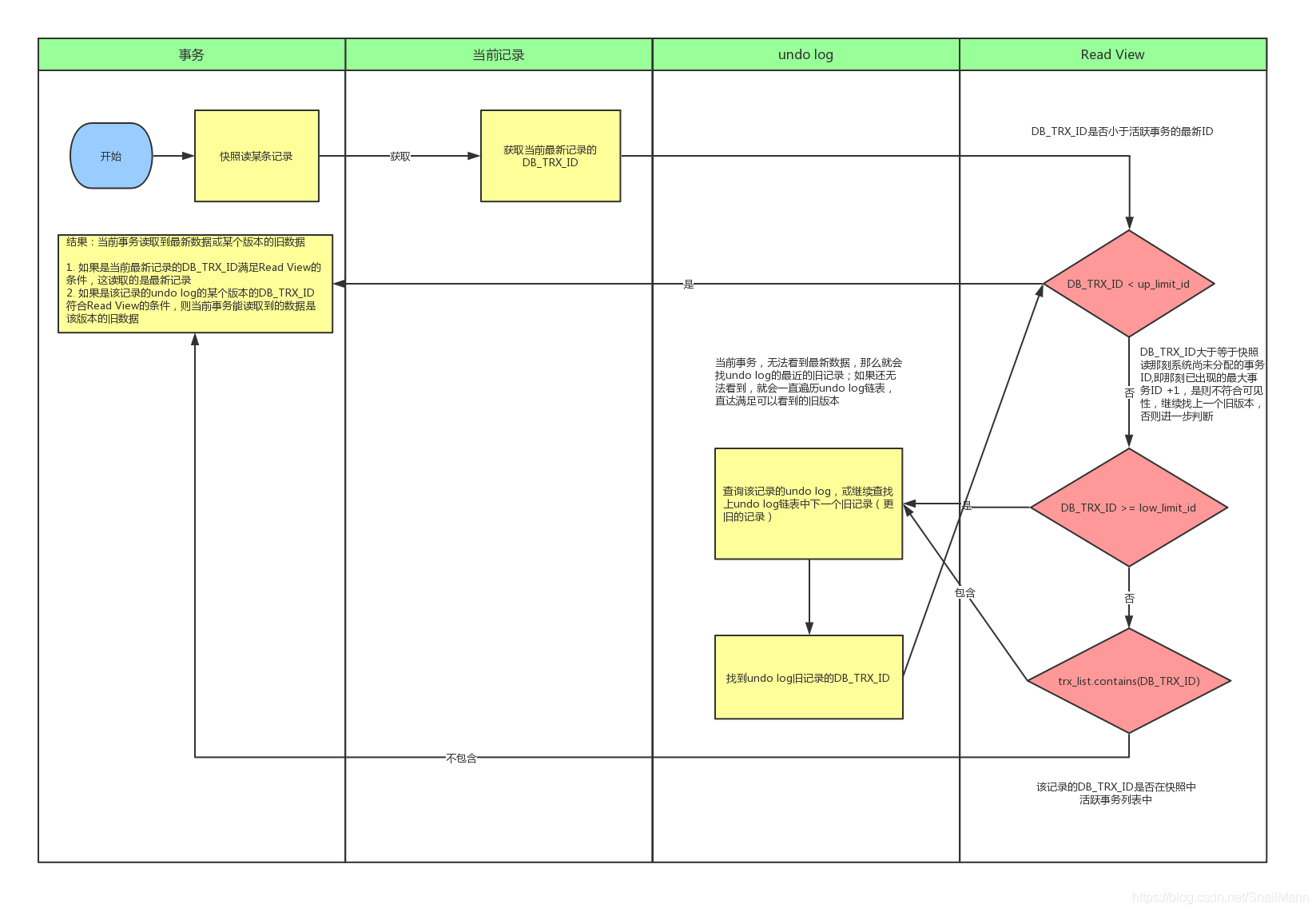
什么是 Read View,说白了 Read View 就是事务进行快照读操作的时候生产的读视图 (Read View),在该事务执行的快照读的那一刻,会生成数据库系统当前的一个快照,记录并维护系统当前活跃事务的 ID (当每个事务开启时,都会被分配一个 ID , 这个 ID 是递增的,所以最新的事务,ID 值越大)
所以我们知道 Read View 主要是用来做可见性判断的, 即当我们某个事务执行快照读的时候,对该记录创建一个 Read View 读视图,把它比作条件用来判断当前事务能够看到哪个版本的数据,既可能是当前最新的数据,也有可能是该行记录的undo log里面的某个版本的数据。
Read View遵循一个可见性算法,主要是将要被修改的数据的最新记录中的 DB_TRX_ID(即当前事务 ID )取出来,与系统当前其他活跃事务的 ID 去对比(由 Read View 维护),如果 DB_TRX_ID 跟 Read View 的属性做了某些比较,不符合可见性,那就通过 DB_ROLL_PTR 回滚指针去取出 Undo Log 中的 DB_TRX_ID 再比较,即遍历链表的 DB_TRX_ID(从链首到链尾,即从最近的一次修改查起),直到找到满足特定条件的 DB_TRX_ID , 那么这个 DB_TRX_ID 所在的旧记录就是当前事务能看见的最新老版本
Read View是如何保证可见性判断的呢?它也是一种数据结构, 有如下几个重要属性
m_ids:当前系统中那些活跃(未提交)的读写事务ID, 它数据结构为一个List。
min_limit_id:表示在生成ReadView时,当前系统中活跃的读写事务中最小的事务id,即m_ids中的最小值。
max_limit_id:表示生成ReadView时,系统中应该分配给下一个事务的id值。(所以系统中目前最大的事务id = max_limit_id - 1)
creator_trx_id: 创建当前read view的事务ID
Read view 匹配条件规则如下:
- 如果数据事务ID
trx_id < min_limit_id,表明生成该版本的事务在生成Read View前,已经提交(因为事务ID是递增的),所以该版本可以被当前事务访问。(在当前事务开始前, 数据就已修改并提交了, 所以当前事务能访问) - 如果
trx_id>= max_limit_id,表明生成该版本的事务在生成ReadView后才生成,所以该版本不可以被当前事务访问。 - 如果
min_limit_id =<trx_id< max_limit_id,需要分3种情况讨论
(1).如果
m_ids包含trx_id,则代表Read View生成时刻,这个事务还未提交,但是如果数据的trx_id等于creator_trx_id的话,表明数据是自己生成的,因此是可见的。(2)如果
m_ids包含trx_id,并且trx_id不等于creator_trx_id,则Read View生成时,事务未提交,并且不是自己生产的,所以当前事务也是看不见的;(3).如果
m_ids不包含trx_id,则说明你这个事务在Read View生成之前就已经提交了,修改的结果,当前事务是能看见的。
整体流程
我们模拟一下
- 当事务 2 对某行数据执行了快照读,数据库为该行数据生成一个Read View读视图,假设当前事务 ID 为 2,此时还有事务1和事务3在活跃中,事务 4 在事务 2 快照读前一刻提交更新了,所以 Read View 记录了系统当前活跃事务 1,3 的 ID,维护在一个列表上,假设我们称为
m_ids
| 事务 1 | 事务 2 | 事务 3 | 事务 4 |
|---|---|---|---|
| 事务开始 | 事务开始 | 事务开始 | 事务开始 |
| … | … | … | 修改且已提交 |
| 进行中 | 快照读 | 进行中 |
- Read View 不仅仅会通过一个列表 trx_list 来维护事务 2执行快照读那刻系统正活跃的事务 ID 列表,还会有两个属性 min_limit_id( m_ids列表中事务 ID 最小的 ID ),max_limit_id( 快照读时刻系统尚未分配的下一个事务 ID ,也就是目前已出现过的事务ID的最大值 + 1 传送门 ) 。所以在这里例子中 min_limit_id 就是1,max_limit_id就是 4 + 1 = 5,m_ids 集合的值是 1, 3,Read View 如下图

- 我们的例子中,只有事务 4 修改过该行记录,并在事务 2 执行快照读前,就提交了事务,所以当前该行当前数据的 undo log 如下图所示;我们的事务 2 在快照读该行记录的时候,就会拿该行记录的 DB_TRX_ID 去跟 min_limit_id, max_limit_id和活跃事务 ID 列表( m_ids )进行比较,判断当前事务 2能看到该记录的版本是哪个。
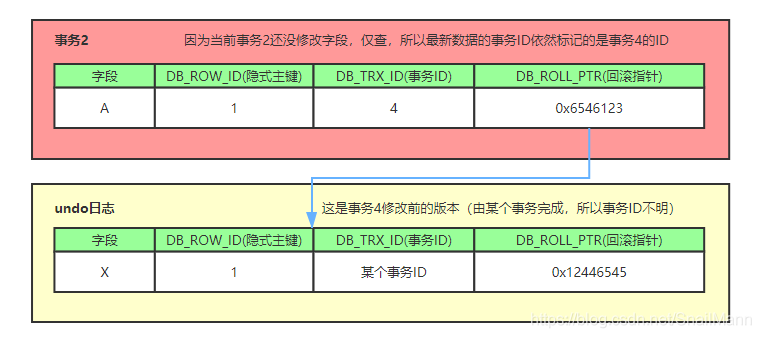
所以先拿该记录 DB_TRX_ID 字段记录的事务 ID 4 去跟 Read View 的 min_limit_id比较,
看 4 是否小于 min_limit_id( 1 ),所以不符合条件,
继续判断 4 是否大于等于 max_limit_id( 5 ),也不符合条件,
最后判断 4 是否处于 m_ids 中的活跃事务, 最后发现事务 ID 为 4 的事务不在当前活跃事务列表中, 符合可见性条件,所以事务 4修改后提交的最新结果对事务 2 快照读时是可见的,所以事务 2 能读到的最新数据记录是事务4所提交的版本,而事务4提交的版本也是全局角度上最新的版本
RC , RR 级别下的 InnoDB 快照读有什么不同?
RC: read commit , 读已提交
RR: repeatable read, 可重复读
正是 Read View 生成时机的不同,从而造成 RC , RR 级别下快照读的结果的不同
在 RR 级别下的某个事务的对某条记录的第一次快照读会创建一个快照及 Read View, 将当前系统活跃的其他事务记录起来,此后在调用快照读的时候,还是使用的是同一个 Read View,所以只要当前事务在其他事务提交更新之前使用过快照读,那么之后的快照读使用的都是同一个 Read View,所以对之后的修改不可见;
即 RR 级别下,快照读生成 Read View 时,Read View 会记录此时所有其他活动事务的快照,这些事务的修改对于当前事务都是不可见的。而早于Read View创建的事务所做的修改均是可见
而在 RC 级别下的,事务中,每次快照读都会新生成一个快照和 Read View , 这就是我们在 RC 级别下的事务中可以看到别的事务提交的更新的原因
总之在 RC 隔离级别下,是每个快照读都会生成并获取最新的 Read View;而在 RR 隔离级别下,则是同一个事务中的第一个快照读才会创建 Read View, 之后的快照读获取的都是同一个 Read View。