1.java是值传递还是引用传递
答: 全部均为值传递!!!!
以前我认为基本类型是值传递,而对象是引用传递,这是错误的!!!!
有时候我会觉得传对象时里面的属性值变化了,
(瞎猜:)其实是属性值的地址变化了,值也就改变了,而原来的值还在,指向原来的地址,只是没人用而已(等待被回收)
来自* <https://blog.csdn.net/bjweimengshu/article/details/79799485 >
2.尾递归
有一种特殊的递归方式叫尾递归。如果函数中的递归调用都是尾调用,则该函数是尾递归函数。尾递归的特性使得递归调用不需要额外的空间 . 不能有任何操作, 如果有f(n)+1这类的操作,都不算尾递归(因为还是保存了函数的返回值)
来自:https://www.ibm.com/developerworks/cn/java/j-understanding-functional-programming-2/index.html?ca=drs-#icomments
// 实现斐波那契数列
// 普通递归
int FibonacciRecursive(int n) {
if( n < 2)
return n;
return FibonacciRecursive(n-1)+FibonacciRecursive(n-2);
}
// 尾递归
int FibonacciTailRecursive(int n,int ret1,int ret2) {
if(n==0)
return ret1;
return FibonacciTailRecursive(n-1,ret2,ret1+ret2);
}
来自: https://blog.csdn.net/mengxiangjia_linxi/article/details/78158819
尾递归效率高的原理:
尾递归就是从最后开始计算, 每递归一次就算出相应的结果, 也就是说, 函数调用出现在调用者函数的尾部, 因为是尾部, 所以根本没有必要去保存任何局部变量. 直接让被调用的函数返回时越过调用者, 返回到调用者的调用者去。精髓:尾递归就是把当前的运算结果(或路径)放在参数里传给下层函数 , 也不用开辟新的栈空间,直接用上一个栈
尾递归优化得益于编译器的支持,恰巧java不支持尾递归优化,但是上面那种省栈省开销还是有的(应该吧).一般函数式语言都是支持的,比如scala
但是可以利用lambda的懒加载来实现尾递归优化,
详情: https://www.cnblogs.com/invoker-/p/7723420.html#autoid-3-0-0
3. java中的CAS和AQS
CAS : Conmpare And Swap (比较和交换) 是用于实现多线程同步的原子指令。 它将内存位置的内容与给(期望)定值进行比较,只有在相同的情况下,将该内存位置的内容修改为新的给定值。 这是作为单个原子操作完成的。
AQS: 抽象队列同步器(AbstractQueuedSynchronizer) , 是用来构建锁或者其他同步组件的基础框架,它使用一个int成员表示同步状态,通过内部的FIFO队列来完成资源获取线程的排序工作。ReentrantLock、Semaphore、CountDownLatch、CyclicBarrier等并发类均是基于AQS来实现的,
https://blog.csdn.net/yanghan1222/article/details/80247844
3.1 CAS 的三大问题
尽管 CAS 提供了一种有效的同步手段,但也存在一些问题,主要有以下三个:ABA 问题、长时间自旋、多个共享变量的原子操作。
1. ABA 问题
所谓的 ABA 问题,就是一个值原来是 A,变成了 B,又变回了 A。这个时候使用 CAS 是检查不出变化的,但实际上却被更新了两次。
ABA 问题的解决思路是在变量前面追加上版本号或者时间戳。从 JDK 1.5 开始,JDK 的 atomic 包里提供了一个类AtomicStampedReference类来解决 ABA 问题。
2. 长时间自旋 CAS 多与自旋结合。如果自旋 CAS 长时间不成功,会占用大量的 CPU 资源。
解决思路是让 JVM 支持处理器提供的pause 指令。
pause 指令能让自旋失败时 cpu 睡眠一小段时间再继续自旋,从而使得读操作的频率降低很多,为解决内存顺序冲突而导致的 CPU 流水线重排的代价也会小很多。
3. 多个共享变量的原子操作
当对一个共享变量执行操作时,CAS 能够保证该变量的原子性。但是对于多个共享变量,CAS 就无法保证操作的原子性,
这时通常有两种做法:
- 使用
AtomicReference类保证对象之间的原子性,把多个变量放到一个对象里面进行 CAS 操作; - 使用锁。锁内的临界区代码可以保证只有当前线程能操作。
一文彻底搞清楚Java实现CAS的原理 | 二哥的Java进阶之路 (javabetter.cn)
4. jvm中的记忆集(Remembered Set)是什么?
jvm的堆内存分为了 年轻代和老年代, 分别使用各自的垃圾回收器回收
如果年轻代中的对象引用了老年代的对象, 当youngGC时就不能只扫描年轻代, 还得扫描老年代看对象是否有引用, 这种情况下, 就会变成扫描整个堆 —– 称为 跨代引用假说
所以jvm在年轻代中存了一个全局的数据结构, 称为记忆集. 这个结构把老年代划分成若干小块,标识出老年代的哪一块内存会存在跨代引用。此后当发生Minor GC时,只有包含了跨代引用的小块内存里的对象才会被加入到GC Roots进行扫描
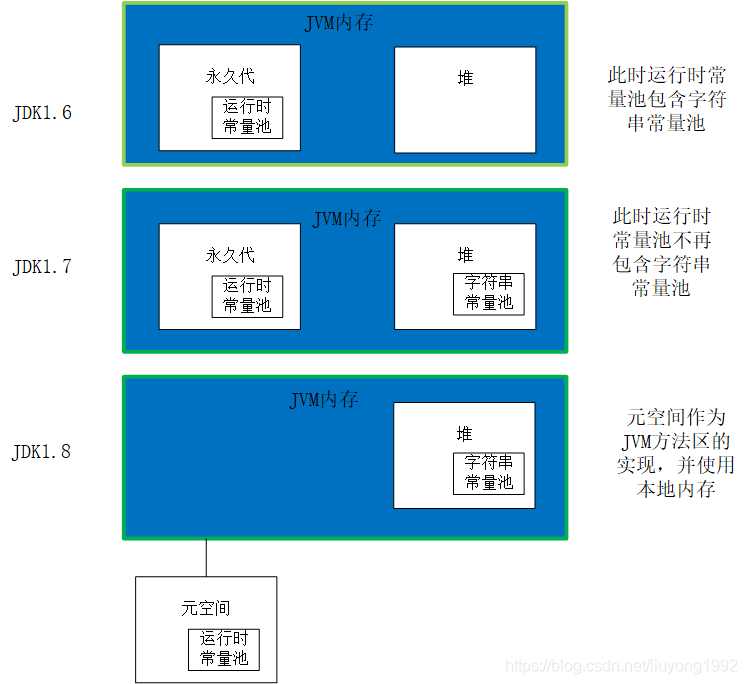
5. 运行时常量池和字符串常量池
运行时常量池
类文件中除了包含类的版本、字段、方法、接口等描述信息, 这些最开始都是保存在常量池中,他们都是静态信息,
当程序运行时被加载到内存后,这些符号才有对应的内存地址信息。这些常量一旦被转入内存就会变成运行时常量池。运行时常量池在方法区中。
比如
math.compute(), 在代码中写的是字符串, 那具体怎么调用的呢?compute()这个符号引用在运行时就会被转变为compute()方法具体代码在内存中的地址,主要通过对象头里的类型指针去转换直接引用。
compute()方法被加载到内存以后,就有了自己的地址,原来调用computer()方法的符号引用,现在就变成对compute()地址的直接引用,这个直接引用是存在对象头里的,通过指针来指向直接引用
所以 运行时常量池 存的类和方法等一些描述信息, 用于程序调用执行, 存在方法区中, jdk8后放入元空间了
字符串常量池
字符串常量池存的是字符串信息 , 存在于堆中 , 因为字符串用的多, 所以用个池单独存起来, 并实现值的复用
比如:
String c = "abcdefg" String d = "abcdefg"c和d 都指向字符串常量池, 且为同一个内存地址,
jdk8后 静态成员变量也放在堆中了
两个池的存放位置
深刻理解运行时常量池、字符串常量池 - 掘金 (juejin.cn)
java的字符串存储在堆中还是常量池中_编码大神经的博客-CSDN博客
6. java 虚拟线程
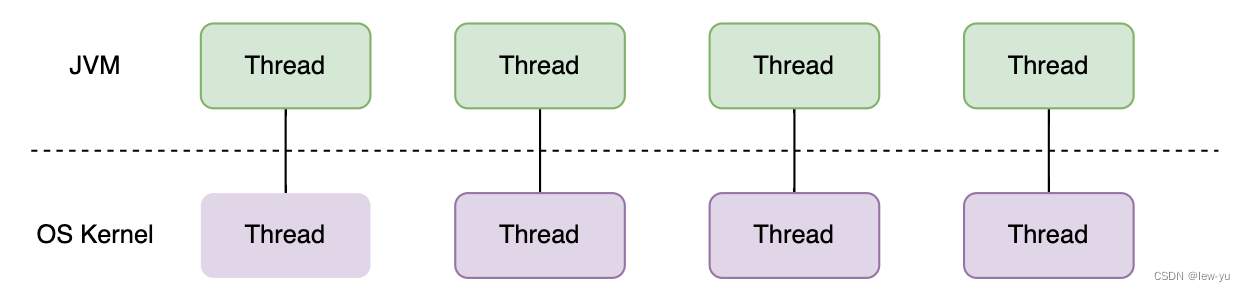
虚拟线程(Virtual Thread-)是 JDK 而不是 OS 实现的轻量级线程(Lightweight Process,LWP),许多虚拟线程共享同一个操作系统线程,虚拟线程的数量可以远大于操作系统线程的数量。
近几十年来,我们一直依靠上述多线程模型来解决 Java 中的并发编程问题。为了提高系统的吞吐量,我们必须不断增加线程的数量,但是机器的线程很昂贵,可用线程的数量是有限的。尽管我们使用各种线程池来最大限度地提高线程的成本效益,但在 CPU、网络或内存资源被耗尽之前,线程往往成为我们应用程序性能的瓶颈,无法释放硬件应具有的最大性能。
我们常见的Java线程与系统内核线程是一一对应的,系统内核线程调度器负责调度Java线程。
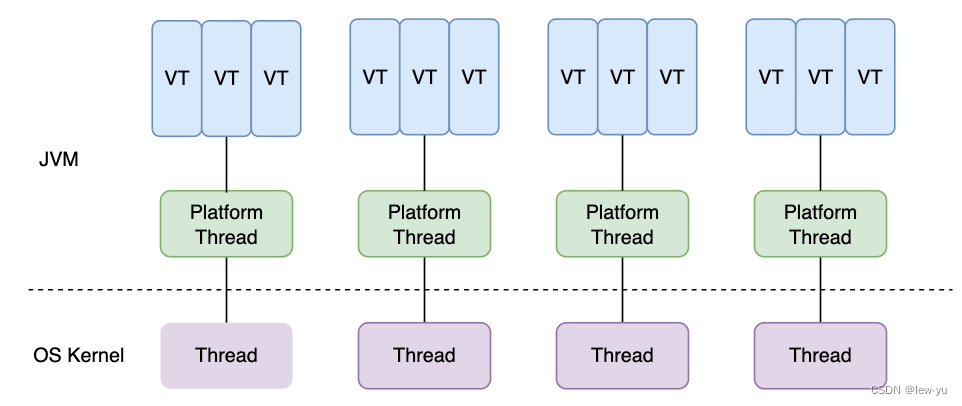
Java19 引入了虚拟线程。在 Java19 中,我们以前使用的线程称为平台线程,仍然与系统内核线程一一对应。大量 (M个) 的虚拟线程,运行在少量 (N个) 的平台线程上(与 OS 线程一一对应)(M:N 调度)。JVM调度多个虚拟线程在特定平台线程上执行,并且在平台线程上一次只执行一个虚拟线程。
- 直接用虚拟线程池代替线程池。如果您的项目使用
CompletableFuture,您也可以直接将执行异步任务的线程池替换为Executors.newVirtualThreadPerTaskExecutor().- 消除池化机制。虚拟线程非常轻量级,不需要池化。
- synchronized更改为ReentrantLock减少固定到平台线程的虚拟线程。
Java19 虚拟线程原理介绍及实现_lew-yu的博客-CSDN博客
7. 为什么Switch支持枚举但不能用类名的方式写(限定名称)
enum Foobar {
FOO,
BAR;
}
class Test {
static int test(Foobar var0) {
switch (var0) {
case FOO:
return 1;
case BAR:
return 2;
case Foobar.BAR: // 这样写就会报错,提示: 不能是限定名称
return 2;
default:
return 0;
}
}
}
限定名称: 带了路径去表示一个类, 例如: java.lang.String
switch本质只支持int类型的值, 所以支持int, Integer, char, 枚举,string 等等, 但不支持Long, double这类
支持String是把字符串通过hashCode()转成整型,
Long型转成int会丢失精度, 所以jvm不会自动转换,(可以自己手动强转)
枚举比较特殊, switch是调用 ordinal() 方法来做判断 (表示枚举的顺序)
进入正题: 枚举类型在JVM中是以类的形式表示的,每个枚举常量都是该类的一个实例, 枚举常量可以有自己的字段和方法, 所以当用限定名称指定枚举后, 就变成了一个类 (类无法转成整型), 如果只写枚举, 就是一个实例,
原理:
switch语句要使用tableswitch和lookupswitch这两个指令,这两个指令只针对int类型进行操作
tableswitch case值连续的场景使用
lookupswitch case较为稀疏的场景使用
截止于 jdk1.8