[toc]
前言
本文档基于elasticsearch 6.4.2 , jdk 1.8 ,三台centos6 服务器,以下所有操作均在jht用户下完成,以10.10.204.167为主服务器
不要使用root账号安装!!! 使用额外账号安装,例如:
jht
1. 节点角色
ES 支持的功能较多(譬如机器学习),为了更好的支持这些功能,es 定义了多种节点角色,一个节点可以同时担任多种角色,默认具有以下角色:
- master
- data
- data_content
- data_hot
- data_warm
- data_cold
- data_frozen
- ingest
- ml
- remote_cluster_client
- transform
ES 集群中的节点大致可以分为管理节点、数据节点和任务节点。
管理节点 :
- 角色配置为 master,能够参与 leader 投票、可以被选为 leader 的节点
- 被选为 leader 的节点负责集群的管理工作
- 如果同时配置了 voting_only 角色,该节点只参与选举投票,不做候选人
数据节点:
- 角色配置为 data,负责存储数据和提供数据查询、聚合处理的节点
- 数据节点可以进一步细分:data_content,data_hot,data_warm,data_cold,data_frozen
- data_content: 存放 document 数据
- data_hot: 存放刚写入的时间序列数据(热点数据),要能够快速读写
- data_warm:不再经常更新、低频查询的数据
- data_cold:极少访问的只读数据
- data_frozen:缓存从快照中查询出的数据,如果不存在从快照读取后缓存,
任务节点 类型较多,每个角色负责专门的任务:
- []: 角色为空,coordinating node,没有任何角色,只负责将收到的请求转发到其它节点
- ingest:承担 pipeline 处理任务的节点
- remote_cluster_client:跨集群操作时,与其它机器进行通信的节点
- ml:执行机器学习任务和处理机器学习 api 的节点,通常建议同时配置角色 remote_cluster_client
- transform:数据处理节点,对文档数据进行再次加工,通常建议同时配置角色 remote_cluster_client
ElasticSearch 零基础入门(1):基本概念、集群模式、查询语法和聚合语法By李佶澳 (lijiaocn.com)
2. 几种集群模式
基本高可用(数据和管理不分离)
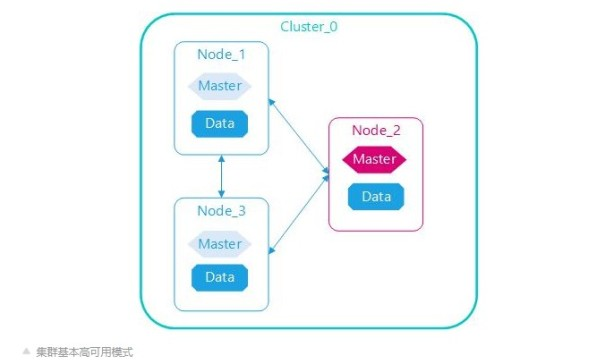
Elasticsearch集群要达到基本高可用,一般要至少启动3个节点,3个节点互相连接,单个节点包括所有角色,其中任意节点停机集群依然可用。为什么要至少3个节点?因为集群选举算法奇数法则。
本文也是介绍的这种
数据与管理分离
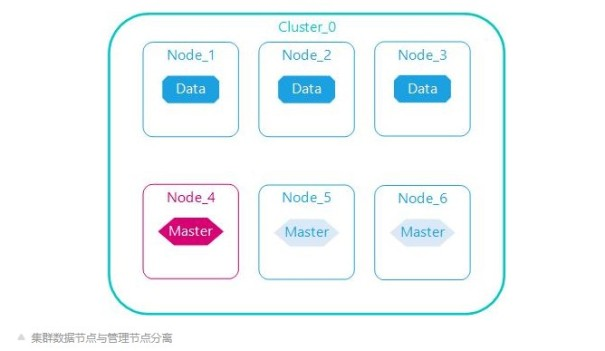
Elasticserach管理节点职责是管理集群元数据、索引信息、节点信息等,自身不设计数据存储与查询,资源消耗低;相反数据节点是集群存储与查询的执行节点。
管理节点与数据节点分离,各司其职,任意数据节点故障或者全部数据节点故障,集群仍可用;管理节点一般至少启动3个,任意节点停机,集群仍正常运行。
数据与协调分离
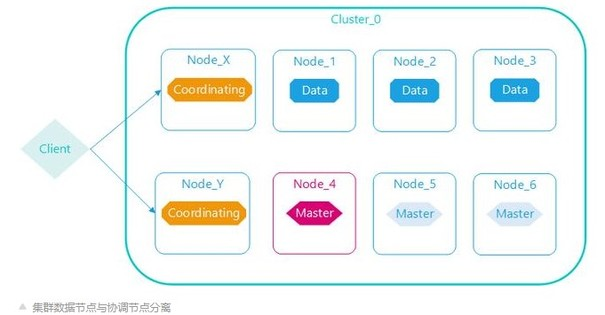
Elasticsearch内部执行查询或者更新操作时,需要路由,默认所有节点都具备此职能,特别是大的查询时,协调节点需要分发查询命令到各个数据节点,查询后的数据需要在协调节点合并排序,这样原有数据节点代价很大,所以分离职责,
数据节点标签
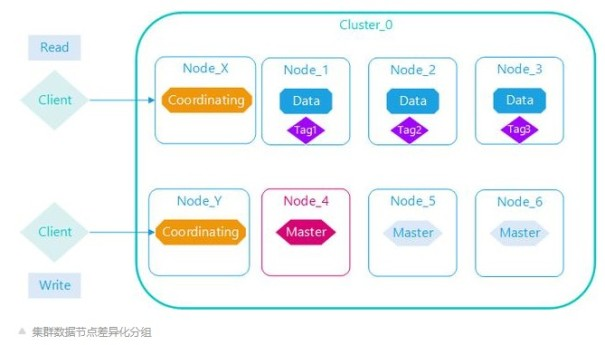
Elasticsearch给数据节点标签,目的是分离索引数据的分布,在一个集群规模中等以上,索引数据用途多种多样,对于数据节点的资源需求不一样,数据节点的配置可以差异化,有的数据节点配置高做实时数据查询,有的数据节点配置低做历史数据查询,有的数据节点做专门做索引重建。
Elasticsearch集群部署时需要考虑基础硬件条件,集群规模越来越大,需要多个数据中心,多个网络服务、多个服务器机架,多个交换机等组成,索引数据的分布与这些基础硬件条件都密切相关。
主副分片分离
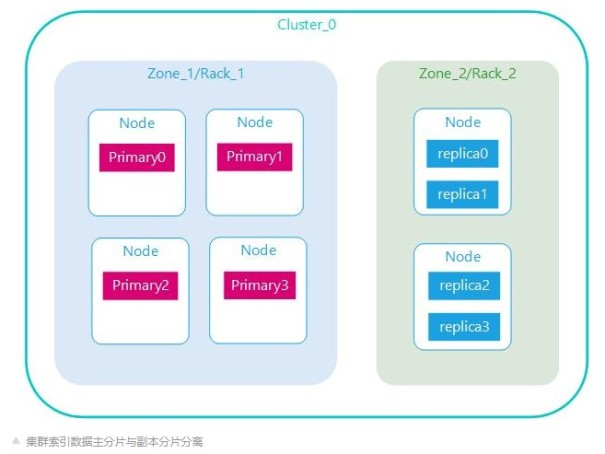
Elasticsearch集群规模大了之后得考虑集群容灾,若某个机房出现故障,则可以迅速切换到另外的容灾机房。
跨集群操作
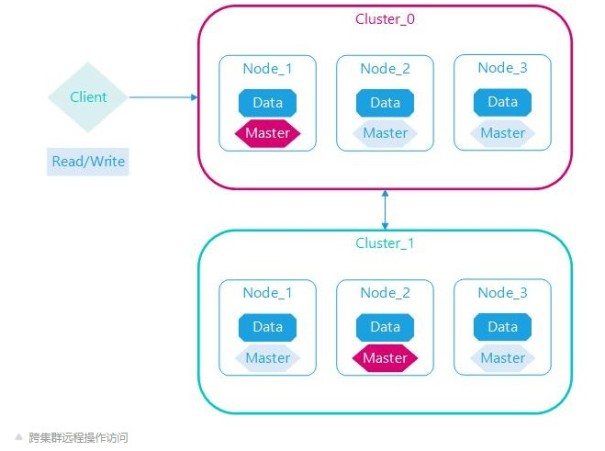
Elasticsearch单个集群规模不能无限增长,理论上可以,实际很危险,通过创建多个分集群分解,集群直接建立直接连接,客户端可以通过一个代理集群访问任意集群,包括代理集群本身数据。
Elasticsearch集群支持异地容灾,采用的是跨集群复制的机制,与同一集群主分片副本分片分离是不同的概念,2个集群完全是独立部署运行,仅数据同步复制。
Elasticsearch集群模式知多少?-阿里云开发者社区 (aliyun.com)
3.1 集群搭建
3.1. 准备
- 安装jdk
- 下载elasticsearch安装包并解压
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.4.2.tar.gz && tar-xzvf elasticsearch-6.4.2.tar.gz
3.2. 安装
修改配置
进入
elasticsearch-6.4.2/config,修改elasticsearch.yml文件(已删除多余注释)# 集群名称,各节点应保持一致 cluster.name: bdp_es # 节点名称,每台服务器应不一样 node.name: node167 #当主节点挂了后,是否有资格被竞选为主节点 node.master: true #是否为数据节点(能否存储数据) node.data: true path.data: /opt/soft/es-cdh/elasticsearch-6.4.2/data path.logs: /opt/soft/es-cdh/elasticsearch-6.4.2/logs bootstrap.system_call_filter: false network.host: 0.0.0.0 http.port: 9200 transport.tcp.port: 9300 # 集群配置 discovery.zen.ping.unicast.hosts: ["10.10.204.166:9300", "10.10.204.167:9300","10.10.204.165:9300"] #以下三个配置的意思是:每隔30秒向主节点发送一次心跳监测,120秒之内如果没有回应,则算超时 ##连续超时6次,则认为主节点已经挂了 discovery.zen.fd.ping_timeout: 120s discovery.zen.fd.ping_retries: 6 discovery.zen.fd.ping_interval: 30s ##ping节点的响应时间 client.transport.ping_timeout : 60s # 至少几个节点 discovery.zen.minimum_master_nodes: 2
创建 数据和日志目录
mkdir -p /opt/soft/es-cdh/elasticsearch-6.4.2/data
mkdir -p /opt/soft/es-cdh/elasticsearch-6.4.2/logs
- 修改系统配置
编辑
/etc/security/limits.conf文件# 配置解释见limits.conf # 追加如下内容,如已存在则更新 * soft nofile 65536 * hard nofile 65536 * soft nproc 16384 * hard nproc 16384编辑
/etc/sysctl.conf# 追加如下内容,如已存在则更新 vm.max_map_count = 655360修使配置生效, 执行命令
sysctl -p检查防火墙,必要时打开9200和9300端口
检查防火墙,必要时打开9200和9300端口
sudo vim /etc/sysconfig/iptables-A INPUT -m state --state NEW -m tcp -p tcp --dport 9200 -j ACCEPT -A INPUT -m state --state NEW -m tcp -p tcp --dport 9300 -j ACCEPT#重启防火墙,检查防火墙重启是否成功
service iptables restart
启动时如果仍报错,就继续如下编辑操作(没有则新建)
编辑
/etc/security/limits.d/90-nproc.conf* soft nproc 204800 * hard nproc 204800编辑
/etc/security/limits.d/def.conf* soft nofile 204800 * hard nofile 204800
启动单机并检测
进入es的bin目录,执行
./elasticsearch出现一直在等待其他节点相关日志即成功(因为至少启动两个节点)
搭建其他节点
- 将所有文件复制到其他服务器上
scp -r elasticsearch-6.4.2 jht@10.10.204.166:/opt/soft/es-cdhscp -r elasticsearch-6.4.2 jht@10.10.204.165:/opt/soft/es-cdh- 修改
elasticsearch.yml文件,保证节点名不一样
启动三台服务器并验证
使用elasticsearch head插件验证
连接集群中任意一台均可,能连接上即搭建成功
2.3. 实战
以10.101.204.167为主服务器,在其上写了管理脚本,脚本路径: /home/jht/runShell/esManage.sh
#!/bin/bash
# 简易es管理脚本,可一键启动和停止
# 可改进: 脚本健壮性(如:可重复启动); 命令提取为变量等
start(){
echo "启动es集群....."
esPath=/opt/soft/es-cdh/elasticsearch-6.4.2/bin
# ${esPath}/elasticsearch -d // 表示后台启动
nohup ${esPath}/elasticsearch > /home/jht/runShell/logs/es.log 2>&1 &
ssh jht@10.10.204.166 "source /etc/profile; nohup ${esPath}/elasticsearch > /home/jht/runShell/logs/es.log 2>&1 &"
ssh jht@10.10.204.165 "source /etc/profile; nohup ${esPath}/elasticsearch > /home/jht/runShell/logs/es.log 2>&1 &"
}
stop(){
echo "关闭es集群....."
pgrep -f Elasticsearch | xargs kill -9
ssh jht@10.10.204.166 " pgrep -f Elasticsearch | xargs kill -9"
ssh jht@10.10.204.165 " pgrep -f Elasticsearch | xargs kill -9"
}
case "$1" in
"start")
start ;;
"stop")
stop ;;
*)
echo " 允许的参数(必选): { start| stop } " ;;
esac
启动es集群 : /home/jht/runShell/esManage.sh start
关闭es集群: /home/jht/runShell/esManage.sh stop
参考文章: