[toc]
1. 什么是analysis?
analysis是Elasticsearch在文档发送之前对文档正文执行的过程,以添加到反向索引中(inverted index)。 在将文档添加到索引之前,Elasticsearch会为每个分析的字段执行许多步骤:
- Character filtering (字符过滤器): 使用字符过滤器转换字符
- Breaking text into tokens (把文字转化为标记): 将文本分成一组一个或多个标记
- Token filtering:使用标记过滤器转换每个标记(大小写转化/删除无用词等等)
- Token indexing:把这些标记存于index中
文本分词会发生在两个地方:
创建索引:当索引文档字符类型为text时,在建立索引时将会对该字段进行分词。搜索:当对一个text类型的字段进行全文检索时,会对用户输入的文本进行分词。
2. 主要组成
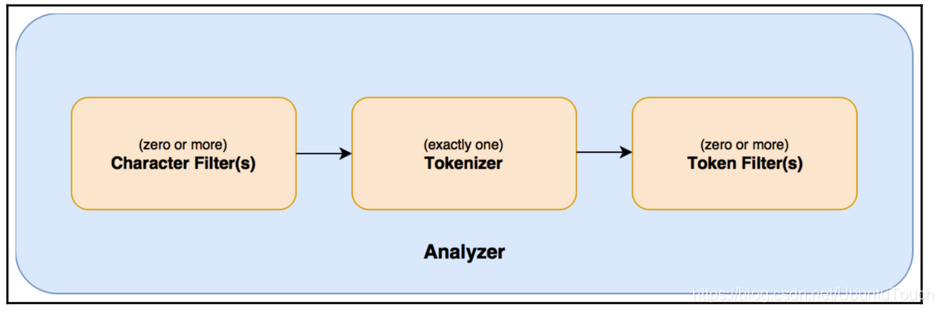
总体说来一个analyzer可以分为如下的几个部分:
0个或1个以上的character filter
接收原字符流,通过添加、删除或者替换操作改变原字符流。例如:去除文本中的html标签,或者将罗马数字转换成阿拉伯数字等。一个字符过滤器可以有零个或者多个。
1个tokenizer
简单的说就是将一整段文本拆分成一个个的词。例如拆分英文,通过空格能将句子拆分成一个个的词,但是对于中文来说,无法使用这种方式来实现。在一个分词器中,有且只有一个tokenizeer
0个或1个以上的token filter
将切分的单词添加、删除或者改变。例如将所有英文单词小写,或者将英文中的停词a删除等。在token filters中,不允许将token(分出的词)的position或者offset改变。同时,在一个分词器中,可以有零个或者多个token filters.
单词的过滤顺序按照 filter过滤器的顺序
3. 使用分析器
默认ES使用standard analyzer
3.1 Elasticsearch的内置分析器
Analyzer
- Standard Analyzer - 默认分词器,按词切分,小写处理
- Simple Analyzer - 按照非字母切分(符号被过滤), 小写处理
- Stop Analyzer - 小写处理,停用词过滤(the,a,is)
- Whitespace Analyzer - 按照空格切分,不转小写
- Keyword Analyzer - 不分词,直接将输入当作输出
- Patter Analyzer - 正则表达式,默认\W+(非字符分割)
- Language - 提供了30多种常见语言的分词器
- Customer Analyzer 自定义分词器
Character Filter
| character filter | logical name | description |
|---|---|---|
| mapping char filter | mapping | 根据配置的映射关系替换字符 |
| html strip char filter | html_strip | 去掉HTML元素 |
| pattern replace char filter | pattern_replace | 用正则表达式处理字符串 |
Tokenizer
| tokenizer | logical name | description |
|---|---|---|
| standard tokenizer | standard | |
| edge ngram tokenizer | edgeNGram | |
| keyword tokenizer | keyword | 不分词 |
| letter analyzer | letter | 按单词分 |
| lowercase analyzer | lowercase | letter tokenizer, lower case filter |
| ngram analyzers | nGram | |
| whitespace analyzer | whitespace | 以空格为分隔符拆分 |
| pattern analyzer | pattern | 定义分隔符的正则表达式 |
| uax email url analyzer | uax_url_email | 不拆分 url 和 email |
| path hierarchy analyzer | path_hierarchy | 处理类似 /path/to/somthing样式的字符串 |
Token Filter
| token filter | logical name | description |
|---|---|---|
| standard filter | standard | |
| ascii folding filter | asciifolding | |
| length filter | length | 去掉太长或者太短的 |
| lowercase filter | lowercase | 转成小写 |
| ngram filter | nGram | |
| edge ngram filter | edgeNGram | |
| porter stem filter | porterStem | 波特词干算法 |
| shingle filter | shingle | 定义分隔符的正则表达式 |
| stop filter | stop | 移除 stop words |
| word delimiter filter | word_delimiter | 将一个单词再拆成子分词 |
| stemmer token filter | stemmer | |
| stemmer override filter | stemmer_override | |
| keyword marker filter | keyword_marker | |
| keyword repeat filter | keyword_repeat | |
| kstem filter | kstem | |
| snowball filter | snowball | |
| phonetic filter | phonetic | 插件 |
| synonym filter | synonyms | 处理同义词 |
| compound word filter | dictionary_decompounder, hyphenation_decompounder | 分解复合词 |
| reverse filter | reverse | 反转字符串 |
| elision filter | elision | 去掉缩略语 |
| truncate filter | truncate | 截断字符串 |
| unique filter | unique | |
| pattern capture filter | pattern_capture | |
| pattern replace filte | pattern_replace | 用正则表达式替换 |
| trim filter | trim | 去掉空格 |
| limit token count filter | limit | 限制 token 数量 |
| hunspell filter | hunspell | 拼写检查 |
| common grams filter | common_grams | |
| normalization filter | arabic_normalization, persian_normalization |
3.2 分析器测试
可以通过_analyzerAPI来测试分词的效果。
POST _analyze
{
"analyzer": "standard",
"text": "The quick Brown Fox"
}
结果: 按空格切分,所以会有四个词
可以按照下面的规则组合使用:
- 0个或者多个
character filters - 一个
tokenizer - 0个或者多个
token filters
POST _analyze
{
"tokenizer": "standard",
"filter": ["lowercase"],
"text": "The quick Brown Fox"
}
结果: 按空格切分,所以会有四个词,但每个词都是小写
3.3 自定义分析器
当内置的分词器无法满足需求时,可以创建custom类型的分词器。
tokenizer:内置或定制的tokenizer.(必须)char_filter:内置或定制的char_filter(非必须)filter:内置或定制的token filter(非必须)position_increment_gap:当值为文本数组时,设置改值会在文本的中间插入假空隙。设置该属性,对与后面的查询会有影响。默认该值为100.
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"standard",
"char_filter":["html_strip"],
"filter":["lowercase","asciifolding"]
}
}
}
}
}
上面的示例中定义了一个名为my_custom_analyzer的分析器,该分析器的type为custom,tokenizer为standard,char_filter为hmtl_strip,filter定义了两个分别为:lowercase和asciifolding.
测试一下:
POST my_index/_analyze
{
"text": "Is this <b>déjà vu</b>?",
"analyzer": "my_custom_analyzer"
}
结果:
{
"tokens" : [
{
"token" : "is",
"start_offset" : 0,
"end_offset" : 2,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "this",
"start_offset" : 3,
"end_offset" : 7,
"type" : "<ALPHANUM>",
"position" : 1
},
{
"token" : "deja",
"start_offset" : 11,
"end_offset" : 15,
"type" : "<ALPHANUM>",
"position" : 2
},
{
"token" : "vu",
"start_offset" : 16,
"end_offset" : 22,
"type" : "<ALPHANUM>",
"position" : 3
}
]
}
4. 分析器作用位置及使用
分析器的使用地方有两个:
- 创建索引时
- 进行搜索时
4.1 创建索引时指定分析器
如果设置手动设置了分析器,ES将按照下面顺序来确定使用哪个分析器:
- 先判断字段是否有设置分析器,如果有,则使用字段属性上的分析器设置
- 如果设置了
analysis.analyzer.default,则使用该设置的分析器 - 如果上面两个都未设置,则使用默认的
standard分析器
为字段指定分析器
PUT my_index
{
"mappings": {
"properties": {
"title":{
"type":"text",
"analyzer": "whitespace"
}
}
}
}
设置索引默认分析器
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"default":{
"type":"simple"
}
}
}
}
}
4.2 搜索时如何确定分析器
在搜索时,通过下面参数依次检查搜索时使用的分词器:
- 搜索时指定analyzer参数
- 创建mapping时指定字段的search_analyzer属性
- 创建索引时指定
setting的analysis.analyzer.default_search - 查看创建索引时字段指定的analyzer属性
- 如果上面几种都未设置,则使用默认的standard分词器。
搜索时指定analyzer查询参数
GET my_index/_search
{
"query": {
"match": {
"message": {
"query": "Quick foxes",
"analyzer": "stop"
}
}
}
}
指定字段的seach_analyzer
PUT my_index
{
"mappings": {
"properties": {
"title":{
"type":"text",
"analyzer": "whitespace",
"search_analyzer": "simple"
}
}
}
}
// 上面指定创建索引时使用的默认分析器为whitespace分词器,而搜索的默认分词器为 simple分词器。
指定索引的默认搜索分词器
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"default":{
"type":"simple"
},
"default_seach":{
"type":"whitespace"
}
}
}
}
}
// 上面指定创建索引时使用的默认分词器为simple分词器,而搜索的默认分词器为whitespace分词器。
5. 常用分析器
5.1 繁简转换分析器
简体和繁体的几个主要情况:
字形差异,汉字字形本身存在着明显差异,如劉与刘,一般是单个字。
词汇的差异,习惯、文化环境造成的用法差异,如滑鼠与鼠标,一般是多字词语。
多种形态共存,有很多代表不同意思的繁体最后简化成了一个字,所以就出现了多音和多义的简体字,如:飆、飈、𩙪都对应于一个简体:飚。
对应第一种,我们可以采用替换的办法,将所有的繁体都替换成对应的简体,在创建索引的时候,就进行标准化,比较好实现,(此文仅针对第一种)
第二种我们可以采用收集相应的词汇转换关系,进行替换,不过因为是多字词语的替换,所以这里面还需要提取处理好分词,不然就有可能替换错误反而引起歧义的问题。
第三种情况,因为繁体和简体是一对多的情况,我们将繁体通过映射表转成简体相对容易,反过来将简体转换成繁体将遇到调整,可能需要结合前后语义来选择正确的繁体。
5.1.1 安装与验证
Github 上的地址是:https://github.com/medcl/elasticsearch-analysis-stconvert/releases
下载之后解压到es的安装目录下的plugins 子目录,重启es即可 (必须选择对应版本)
验证:

如果你的集群里面有不止一个 Elasticsearch 的节点,你需要在每一台 Elasticsearch 的实例上执行相同的插件安装,并进行重启让其加载生效。
5.1.2 插件介绍
STConvert 这个插件一共提供了 4 个不同的组件:
- 一个名为
stconvert的 Analyzer,可以将简体转换成繁体 - 一个名为
stconvert的 Tokenizer,可以将简体转换成繁体 - 一个名为
stconvert的 Token Filter,可以将简体转换成繁体 - 一个名为
stconvert的 Char Filter,可以将简体转换成繁体
每个组件都可以有以下3个参数用来进行自定义配置,分别是:
- 参数
convert_type设置转换的方向,默认是s2t,表示简体到繁体,如果要将繁体转换为简体,则设置为t2s - 参数
keep_both用于设置是否保留转换之前的内容,一般来说保留原始内容可以提高我们的搜索命中率(也就是说可以同时搜索繁体和简体),默认是false,也就是不保留 - 参数
delimiter主要是用于,当保留原始内容的时候,如何分割两部分内容,默认的值是逗号,
t: Traditional (传统的) => Traditional Chinese (繁体)
s: Simplified (简化的) => Simplified Chinese (简体)
5.1.3 简转繁
简转繁好做,因为插件默认就是做这个的
GET /_analyze
{
"tokenizer" : "standard",
"filter" : ["lowercase"],
"char_filter" : ["stconvert"],
"text" : "我爱China。"
}
我们指定了 Tokenizer 为
standard,也指定了lowercase作为分词之后的 Filter,这样就跟标准的 Standard Analyzer 的分析效果一样了,我们还新增了一个 Char Filter 的参数设置,使用的是我们新安装的简繁体转换插件提供的stconvert,也就是将简体转成繁体,其结果如下
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "<IDEOGRAPHIC>",
"position": 0
},
{
"token": "愛",
"start_offset": 1,
"end_offset": 2,
"type": "<IDEOGRAPHIC>",
"position": 1
},
{
"token": "china",
"start_offset": 2,
"end_offset": 7,
"type": "<ALPHANUM>",
"position": 2
}
]
}
可以看到,除了和 Standard 分词效果一样的地方以外,我们还额外的将中文字符都转成了繁体,
爱字转成了愛,而我没有变化,是因为它的繁体也是我。建议我们在真正动手进行自定义分词之前,通过这样的方式先进行分词效果的测试,得到满意的结果之后再进行具体的自定义 Analyzer 的创建工作。
5.1.4 繁转简
创建索引时指定分析器
PUT /my_index
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "standard",
"filter": ["lowercase"],
"char_filter": ["tsconvert"]
}
},
"char_filter": {
"tsconvert" : {
"type" : "stconvert",
"delimiter" : "#",
"keep_both" : false,
"convert_type" : "t2s"
}
}
}
}
}
// delimiter 和 keep_both 属性可以不写
测试:
POST /my_index/_analyze
{
"analyzer": "my_analyzer",
"text": "我愛China。"
}
经过执行,得到的分析结果如下:
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "<IDEOGRAPHIC>",
"position": 0
},
{
"token": "爱",
"start_offset": 1,
"end_offset": 2,
"type": "<IDEOGRAPHIC>",
"position": 1
},
{
"token": "china",
"start_offset": 2,
"end_offset": 7,
"type": "<ALPHANUM>",
"position": 2
}
]
}
5.2 Ik分析器
IK分析插件将Lucene IK分析器(http://code.google.com/p/ik-analyzer/)集成到elasticsearch中,支持自定义字典。
5.2.1 安装与验证
Github 上的地址是:https://github.com/medcl/elasticsearch-analysis-ik/releases
下载之后解压到es的安装目录下的plugins 子目录,重启es即可 (必须选择对应版本)
5.2.2 插件介绍
- Analyzer:
ik_smart,ik_max_word, - Tokenizer:
ik_smart,ik_max_word
ik_max_word和ik_smart什么区别?
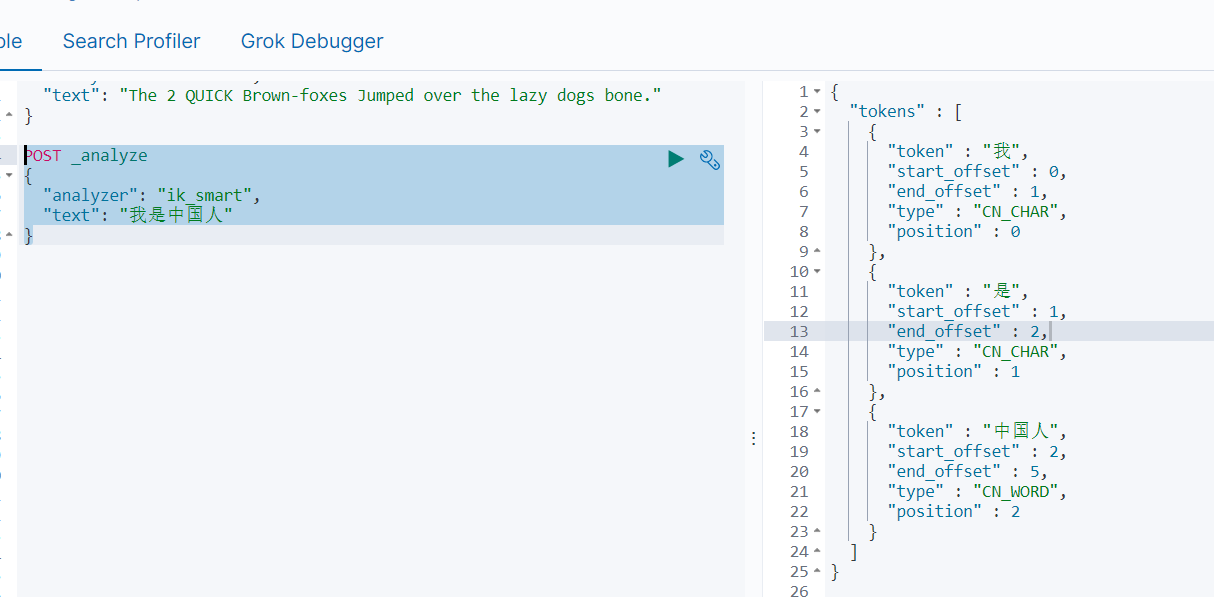
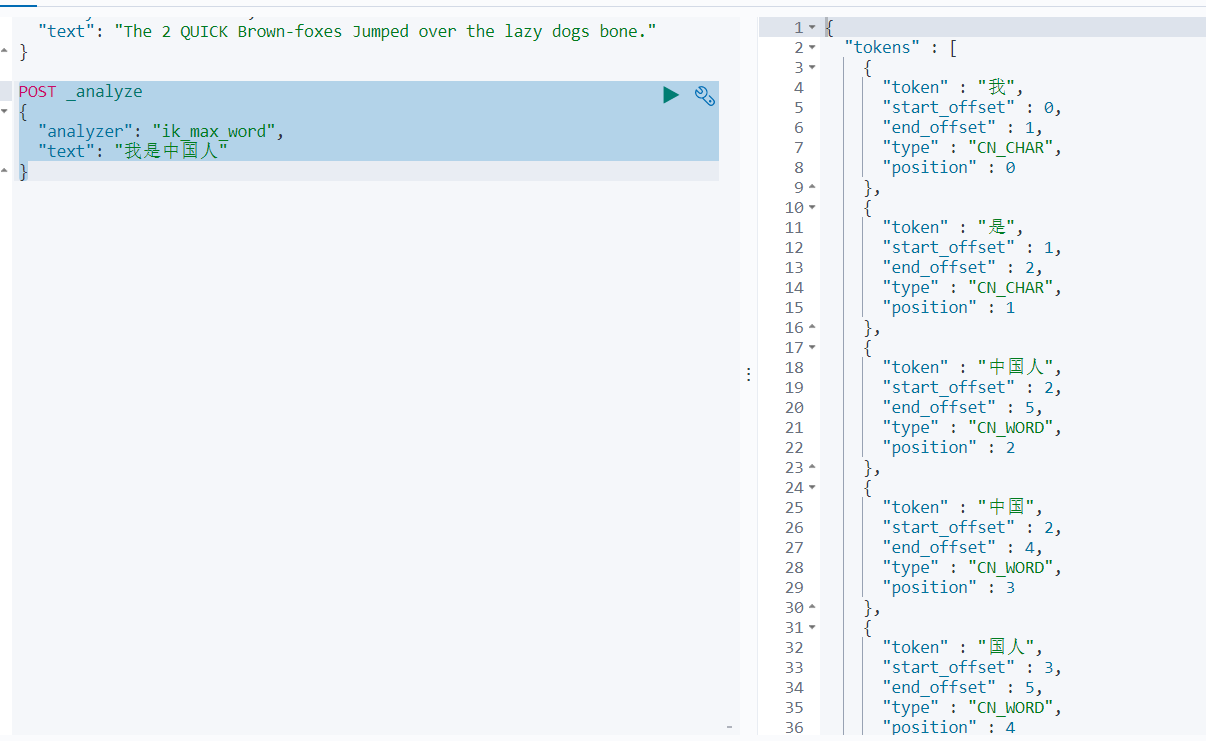
ik_max_word: 会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合,适合 Term Query;
ik_smart: 会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”,适合 Phrase 查询。
5.2.3 基本使用
使用analyzer:
使用tokenizer
PUT product
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"type": "custom",
"filter": [
"lowercase"
],
"tokenizer": "ik_smart"
}
}
}
}
}
5.2.4 自定义分词库
配置 在ik分析器的config目录下的 IKAnalyzer.cfg.xml
内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">custom/mydict.dic;custom/single_word_low_freq.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">custom/ext_stopword.dic</entry>
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">location</entry>
<!--用户可以在这里配置远程扩展停止词字典-->
<entry key="remote_ext_stopwords">http://xxx.com/xxx.dic</entry>
</properties>
扩展词: 不想被分词的词: 比如, 乔碧罗, 神罗天征等
停止词: 不想要的词,搜索时不会搜它, 比如: 个 ,啊, the , a 等
远程词典具备热更新的能力, 满足以下前两点即可实现热更新
其中 location 是指一个 url,比如 http://yoursite.com/getCustomDict,该请求只需满足以下两点即可完成分词热更新。
该 http 请求需要返回两个头部(header),一个是
Last-Modified,一个是ETag,这两者都是字符串类型,只要有一个发生变化,该插件就会去抓取新的分词进而更新词库。写个接口,返回修改时间和ETag即可
或者用Ng转发静态文件, 会自动加上这个两个配置,当文件改动时,这两个值自动改变
该 http 请求返回的内容格式是一行一个分词,换行符用
即可。url返回一个UTF-8格式的文本即可
如果有多个文件,用英文分号隔开
;
监控流程
读取
IKAnalyzer.cfg.xml配置文件,并解析其中的配置向词库服务器发送Head请求
从响应中获取
Last- Modify、Etags字段值,判断是否变化如果未变化,体眠1min,返回第0步
如果有变化,重新加戟词典
休眠1min,返回第0步
自定义词汇只会对新加的数据生效,不会对存量数据生效,需要更新一次才行
数据在写入时就已分词存储,所以自定义词汇不会对存量数据生效
官方
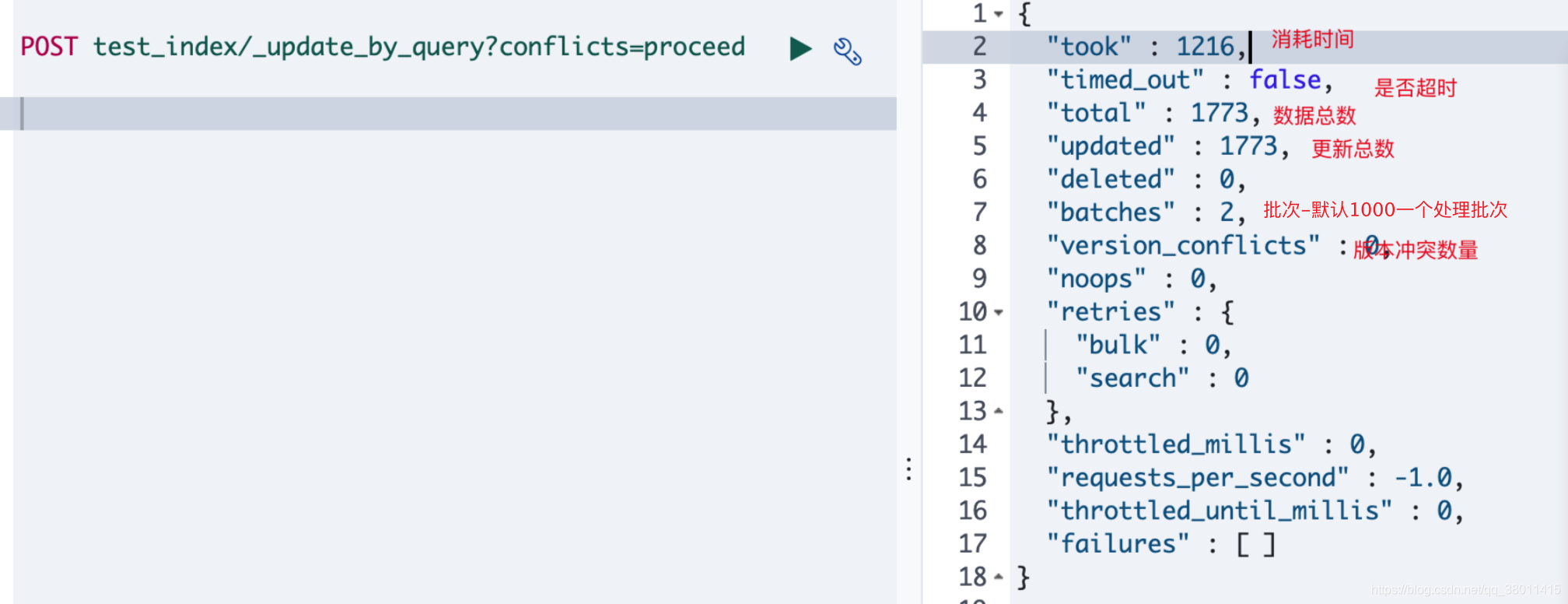
提供更新方式 POST product/_update_by_query?conflicts=proceed
update_by_query原理
开始时获取一个索引的快照,并且使用内部版本来号来进行更新。这意味着如果文档在获得快照后,对索引处理 过程中版本发生更改,将会发生版本冲突。当快照的版本和索引版本一直时则进行更新,并且递增文档版本号。
当遇到冲突而导致整个更新过程失败时,更新过程是不会回滚的。如果不想因为冲突导致整个更新过程终止,可以在url中添加参数conflicts=proceed。或者在请求body中添加”conflicts”:”proceed”
不光这里可以用,修改es文档也是用
_update_by_query执行结果如图:(消耗时间单位 : 毫秒)
格力的es集群,执行效率大概是2300条/s, 26万数据,大概花了1.7分钟
更新可能耗时太久导致客户端连接超时,可以用命令查看任务执行情况(未结束的任务)
GET _tasks?actions=*update*&detailed
5.3 同义词分析器
5.4 拼音分析器
Pinyin Analysis for Elasticsearch
参考链接: