介绍
StarRocks 是一款极速统一的Lakehouse产品,具备水平在线扩缩容,金融级高可用,兼容 MySQL 5.7 协议和 MySQL 生态,提供全面向量化引擎与多种数据源联邦查询等重要特性。StarRocks 致力于在全场景 OLAP 业务上为用户提供统一的解决方案,适用于对性能,实时性,并发能力和灵活性有较高要求的各类应用场景
核心特性
- 列式存储: StarRocks 采用列式存储模式,这意味着数据按列而非行组织,有利于提高分析查询速度,特别是在只需要处理少数几个字段的查询中表现出色。
- 向量化查询引擎: 该引擎能够有效地利用现代 CPU 的 SIMD 指令,加速数据处理和计算。
- MPP 架构: 作为一个具有大规模并行处理(MPP)能力的数据库,StarRocks 能够在多个节点上并行执行查询,从而加快处理速度。
- 实时更新: StarRocks 支持实时数据更新和删除,适用于需要频繁更新数据的场景。
原有的以 Hadoop 为核心的大数据生态,在性能、实效性、运维难度及灵活性等方面都难以满足企业的需求。OLAP 数据库面临着越来越多的挑战,很难有一种数据库能够适配大部分的业务。在这种情况下,我们一般会使用不同的数据库处理不同类型的业务,充分发挥每种分析型数据库的优势,比如说:
•对于 T+1 的报表业务,我们一般是将数据放在 Hive 中定时跑批完成
•对于高并发的分析类查询,我们会使用 Druid,缓解高峰时期大量用户集中使用给系统带来的查询压力
•对于像固定报表业务,我们预先知道了大部分的查询请求,将可以将数据打平成宽表的,放在 ClickHouse 中,充分发挥 ClickHouse 在单表查询的性能优势
•对于明细数据的查询或者全文检索的需求,我们可以使用 Elasticsearch 中,发挥倒排索引的优势
•对于多表关联的需求,我们可以通过 Presto 跨数据源完成多表的 join 操作
一方面,多种技术栈的堆叠确实能够解决我们的问题,另一方面这样的复杂架构也大大增加了开发与运维的成本。这也是 StarRocks 要解决的痛点问题,我们希望把简单的事情回归到简单,能够使用一种统一 OLAP 数据库完成大数据生态中分析层的构建。
StarRocks大数据生态定位
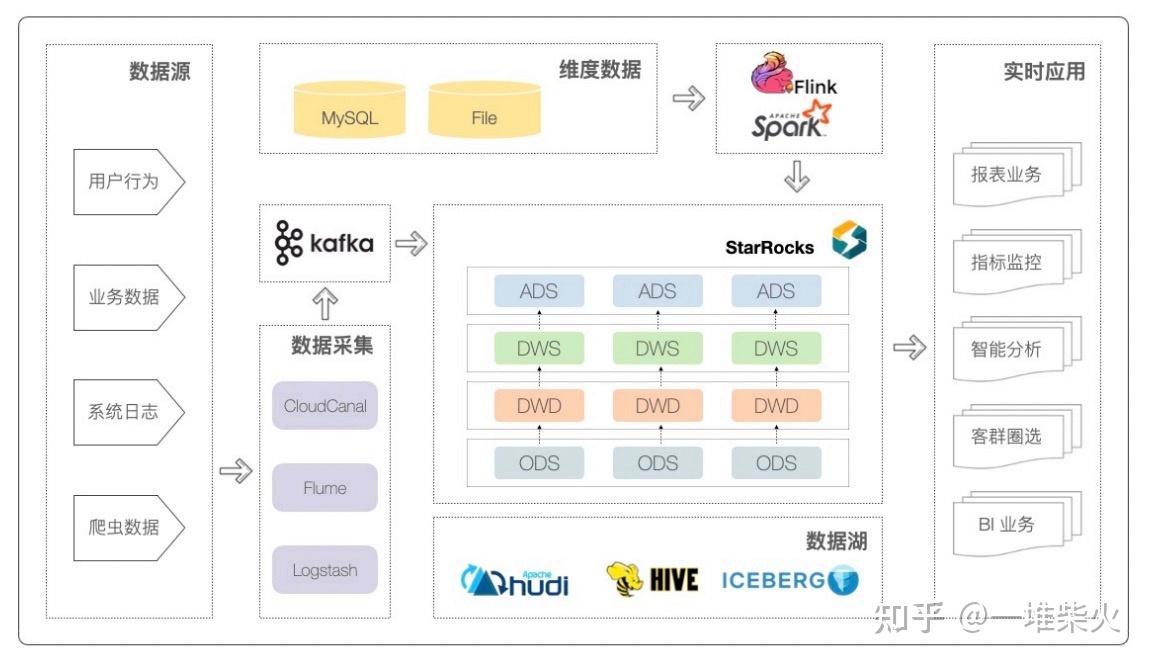
作为一款 MPP 架构的分析性数据库,StarRocks 能够支撑 PB 级别的数据量,拥有灵活的建模方式,可以通过向量化引擎、物化视图、位图索引、稀疏索引等优化手段构建极速统一的分析层数据存储系统。
重构企业数据基础设施
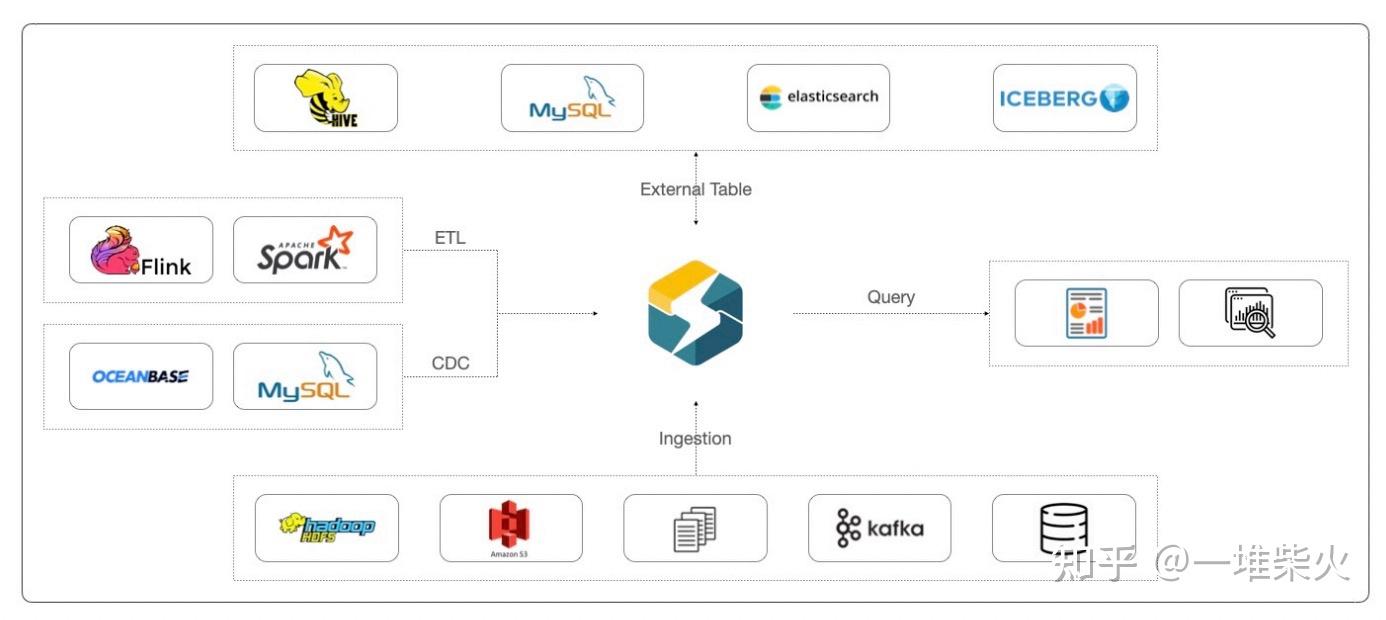
可以说,StarRocks 重构了企业数据基础设施,把复杂的多模分析结构变得简单⽽统⼀。
StarRocks 不依赖于某⼀种技术栈,⽽又能够兼容⼤数据平台的绝⼤部分技术栈:
• 在数据导⼊层⾯上,StarRock 可以拉取 HDFS、S3、OSS 中的数据,也可以导⼊平⾯ ⽂件,或者是消费 Kafka 中的增量数据
• 对于像 MySQL 或者 Oceanbase 这样的 TP 业务库,全量数据我们可以通过 dataX, sqoop 等⼯具进⾏同步,增量数据我们可以通过 canal 这样的 CDC ⼯具实时同步。
• 如果在同步的过程中,我们需要进⾏⼀些清洗或者数据转换操作,可以使⽤ Flink 或 者 Spark
• 此外 StarRocks 还⽀持外表联邦查询,可以拉取 Hive、MySQL、ES 以及 Iceberg 中的 数据,与 StarRocks 中的表进⾏关联,避免数据孤岛的存在
• 从顶层协议来看,StarRocks 兼容了 MySQL 协议,可以轻松平稳的对接多种开源或者 商业 BI ⼯具,⽐如说 Tableau,FineBI,SmartBI,Superset 等
StarRocks架构
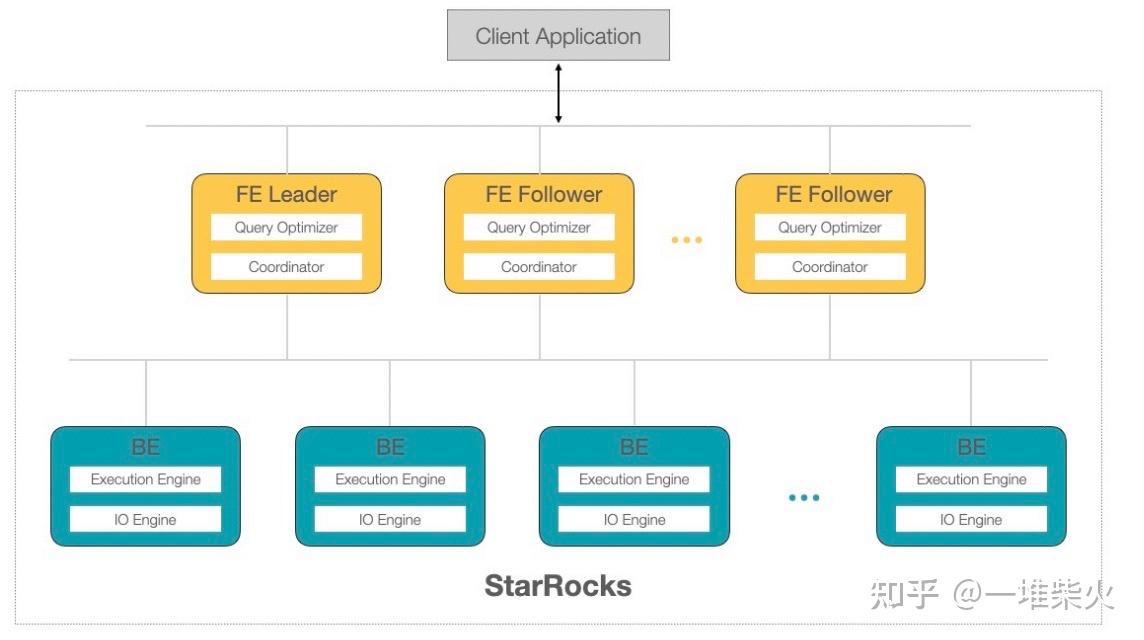
StarRocks 整体上架构⽐较简单,有两层结构,黄⾊的是 FrontEnd 节点,蓝⾊的是 BackEnd 节点:
• FrontEnd 节点主要负责元数据的管理和客户端链接的管理,并且根据元数据信息进⾏ 查询的规划和查询的调度。从 MySQL 客户端发起的请求通过 FrontEnd 节点转化成分 布式的 AST,也就是我们所说的执⾏计划树,推送给对应的 BackEnd 节点。每⼀个 FrontEnd 节点都存储全量的元数据,通过类 Paxos 协议进⾏数据同步,这种多数派的 数据同步协议也保证了我们可以线上⽔平阔所容 FrontEnd 节点。
• BackEnd 节点主要负责数据存储及 SQL 的计算⼯作。FrontEnd 节点按照⼀定的策略 将数据分配给对应的 BackEnd 节点。在执⾏ SQL 计算时,⼀条 SQL 语句⾸先会按照 具体的语义规划成逻辑执⾏单元,然后再按照数据的分布情况拆分成具体的物理执⾏ 单元在 BackEnd 中进⾏计算。BackEnd 节点是完全对等的,数据通过 Qurom 协议进 ⾏同步。BackEnd 节点同样也⽀持在线⽔平阔缩容。
向量化引擎
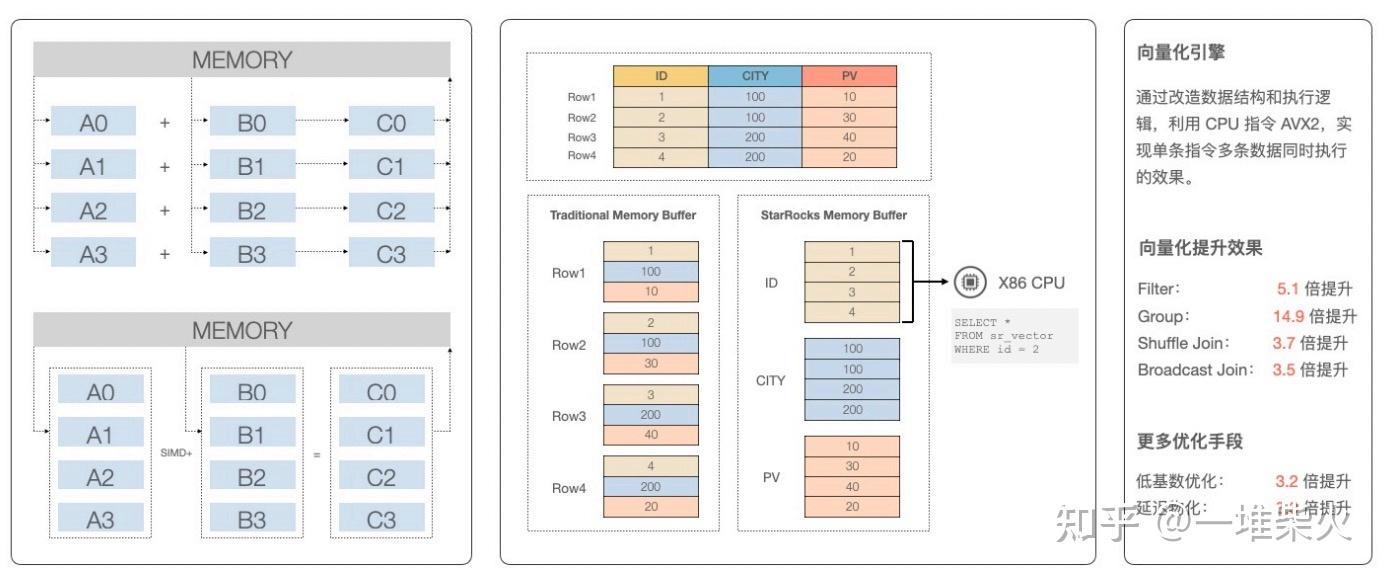
StarRocks 执⾏器的⼀个重⼤的特性就是向量化引擎。通过向量化引擎,可以极⼤程度的提 ⾼查询性能。
作为⼀个列存数据库,StarRocks 的数据在 BackEnd 存储层是以列的形式组织的。 在没有做向量化引擎之前,数据以列的形式存储,但以⾏的形式被加载到内存中。⽐如说我 们要计算 A 列与 B 列的和,会以⾏的维度不停的调⽤ CPU 的加指令,循环迭代 A0 + B0, A1 + B1,A2 + B2。
有了向量化引擎之后,StarRocks 在将数据加载到内存中时,也是按照列的形式进⾏布局。 通过调⽤ CPU 的 SIMD 指令集,计算 A 列与 B 列相加,减少了连续的虚函数调⽤,避免 CPU 流⽔线被打断。
通过向量化引擎的加速,过滤操作⼤概有 5 倍左右的性能提升,聚合操作有 15 倍的性能提 升,关联操作有⼤概 3-4 倍的性能提升。
多种分布式Join方式
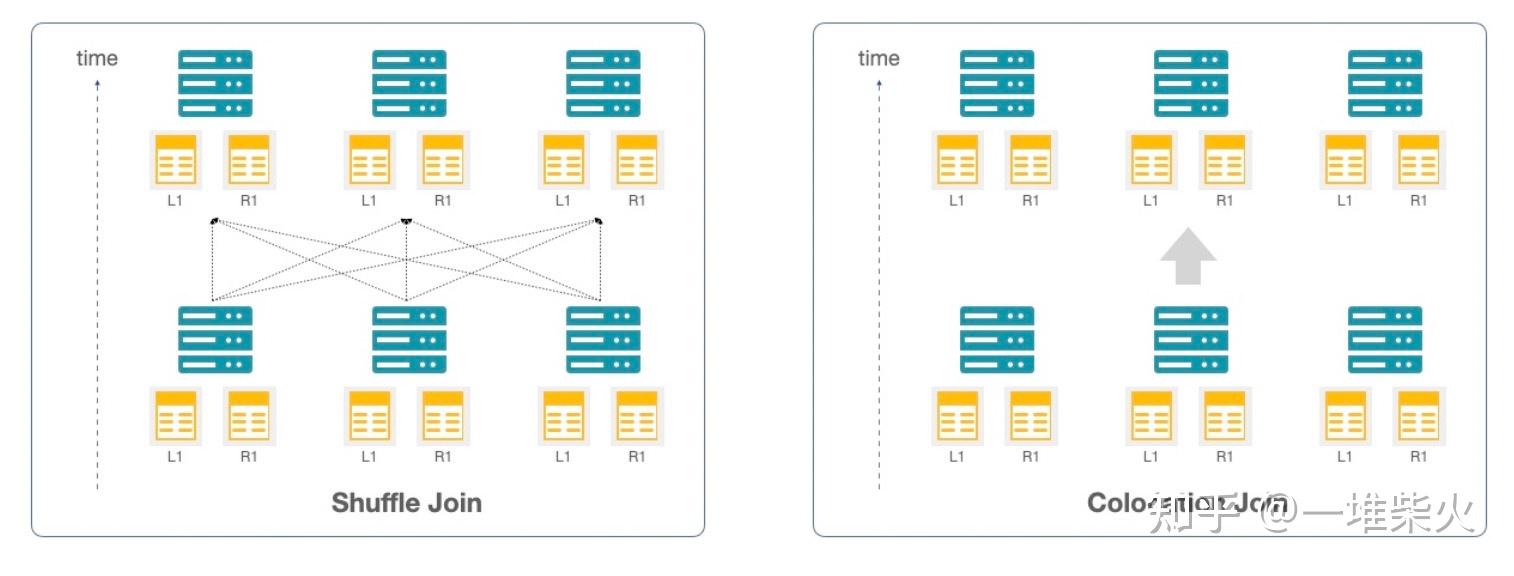
对于实时 Join 的支持是 StarRocks 的一个非常重要的功能。我们提供了不同的 Join 的类型, 比如说小表与大表关联,可以使用 broadcast join,将小表以广播的方式推到不同 server 的内 存中进行关联操作。大表与大表的关联,可以使用 shuffle join 的模式,这也是 MPP 数据库 独有的一种 join 的模式。将数据分割后重新分发到不同的 server 上,利用每一台机器的内存 与 CPU 资源进行计算。当然,在数据 shuffle 的过程中,会带来大量的 IO 开销与网络开 销,可能会影响到查询的性能。
此时可以人工的进行干预,选择 colocation join 的模式。比如我们在使用星型模型的时候, 预先就会计划好,事实表的 ID 列一定会与维度表的 ID 列进行关联,那么我们在数据导入的 过程中,可以人为的将两张表的 ID 列存储到同一台机器上,查询的时候就不需要进行数据 shuffle,直接在这台机器上进行 join 就可以,最大程度的减少了网络开销带来的性能影响。 通过 CBO 的优化,StarRocks 会根据表的统计信息自动选择出最为合适的 Join 类型。如果我 们对查询的性能有更高的要求,也可以手动的指定 colocation join 这种模式,进行特殊优化 的操作。
高并发查询
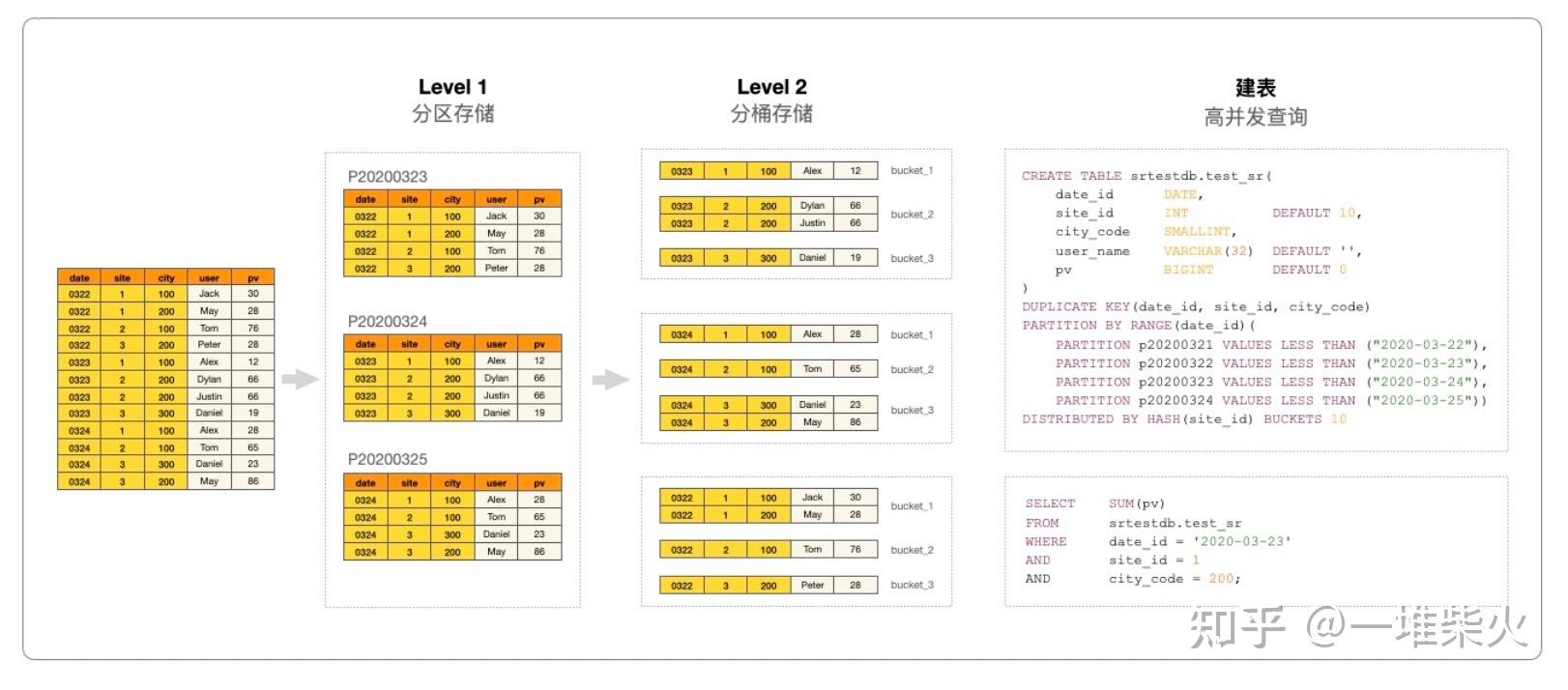
和大多数的 MPP 数据库不同,StarRocks 支持高并发查询。这得益于 StarRocks 对表的两级 分区管理。 首先我们会根据数据的业务属性对表进行分区,一般来说我们会将时间列作为分区键,这样 做可以优化根据时间,删除过期数据所带来的性能问题,也方便了冷热数据的分级存储。 分区的下一级是分桶,StarRocks 采用 Hash 算法对分区数据进行分片管理。在同一分区内, 分桶键的哈希值相同的数据被聚集到一起,形成一个子表,我们称之为 tablet。每一个 tablet 都以多副本的形式进行数据冗余存储。同时 tablet 也是做扩容缩容,failover 与 failback 的最小物理单位。
当表经过分区分桶后,数据的指向性有了显著的提高。如果分区分桶恰好可以有效的覆盖大 部分的查询条件的,那么就可以利用分区分桶剪裁,避免全表扫描。比如在这个例子中,我 们根据 date 列进行了分区操作,又根据 site id 列进行了分桶的操作。查询中,我们既使用 了 date 列,又使用了 site id 列进行条件过滤,通过 date 列的分区我们可能过滤了十几分之 一,再通过 site id 列分桶,又过滤了几十分之一的数据,两者相乘,扫描的数据量可能只是 全表的千分之一甚至万分之一,这样可以降低单个查询的资源消耗,从而实现业务的高并发 查询。在以往的案例中,我们经过分区分桶的操作,加上 StarRocks 的水平扩容的能力,可 以支撑万级别的并发量。
10分钟带你全面了解StarRocks! - 知乎 (zhihu.com)