[TOC]
一、什么是高可用
**高可用HA(**High Availability)是分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计减少系统不能提供服务的时间。
二、如何保障系统的高可用
应用高可用
我们都知道,单点是系统高可用的大敌,单点往往是系统高可用最大的风险和敌人,应该尽量在系统设计的过程中避免单点。方法论上,高可用保证的原则是“集群化”,或者叫“冗余”:只有一个单点,挂了服务会受影响;如果有冗余备份,挂了还有其他backup能够顶上。
保证系统高可用,架构设计的核心准则是:冗余。
有了冗余之后,还不够,每次出现故障需要人工介入恢复势必会增加系统的不可服务实践。所以,又往往是通过“自动故障转移”来实现系统的高可用。
在流量达到系统可承受的上限时, 还得用 降级/限流/熔断 来保证系统的可用性
对于服务状态临界值时怎么保证高可用以及数据的安全?
引入NG的动态负载均衡, 自动剔除不正常的服务
Nginx 模块nginx_upstream_check_module了,这个模块可以让 Nginx 定期地探测后端服务的一个指定的接口,然后根据返回的状态码,来判断服务是否还存活,当探测不存活的次数达到一定阈值时,就自动将这个后端服务从负载均衡服务器中摘除。
upstream server {
server 192.168.1.1:8080;
server 192.168.1.2:8080;
// 检测 URL
check interval=3000 rise=2 fall=5 timeout=1000 type=http default_down=t 5 check_http_send "GET /health_check HTTP/1.0
";
// 检测返回状态码为 200 时认为检测成功
check_http_expect_alive http_2xx;
}
Nginx 按照上面的方式配置之后,你的业务服务器也要实现一个“/health_check”的接口,在这个接口中返回的 HTTP 状态码,这个返回的状态码可以存储在配置中心中,这样在变更状态码时,就不需要重启服务了
**在服务刚刚启动时,**可以初始化默认的 HTTP 状态码是 500,这样 Nginx 就不会很快将这个服务节点标记为可用,也就可以等待服务中,依赖的资源初始化完成,避免服务初始启动时的波动
**在完全初始化之后,**再将 HTTP 状态码变更为 200,Nginx 经过两次探测后,就会标记服务为可用。在服务关闭时,也应该先将 HTTP 状态码变更为 500,等待 Nginx 探测将服务标记为不可用后,前端的流量也就不会继续发往这个服务节点。在等待服务正在处理的请求全部处理完毕之后,再对服务做重启,可以避免直接重启导致正在处理的请求失败的问题。
或者使用灰度机制(AB区机制)
发布部署的时候 关闭A区, 发布B区, 待A区发布完全(spring的优雅停机)且测试通过, 再开放A区, 这样A区也能解决服务初始化时的波动 和 关闭服务而丢失服务正在处理事件的情况
机房高可用
要多机房部署, 机房本身也存在单点问题
如此就遇到跨机房的数据传输, 数据延迟大体如下:
北京同地双机房之间的专线延迟一般在 1ms~3ms
国内异地双机房之间的专线延迟会在 50ms 之内
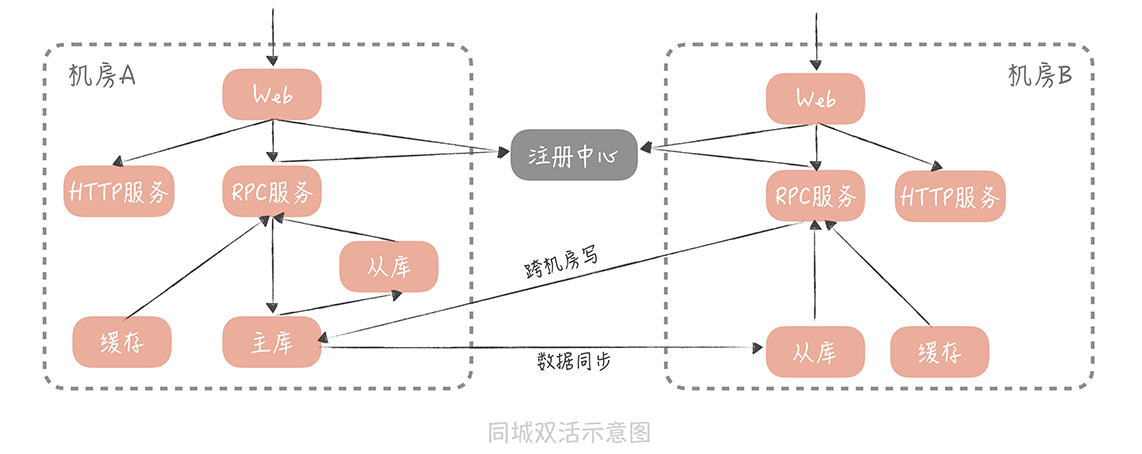
同城多活
就是在一个城市部署多个服务节点, 保证存活(包括应用接口, 数据接口等等 )
鉴于跨机房的数据传输存在延时, 所以应该尽可能的减少跨机房的调用
总的来说, 所有的操作应该尽量在自己机房处理
数据库层(mysql) 采用主从同步的方式, 各自机房,查自己的从库即可, 一般有两种方案
- 基于存储系统的主从复制,比如 MySQL 和 Redis
- 基于消息队列的方式
虽然存在跨机房写数据的问题,不过鉴于写数据的请求量不高,所以在性能上是可以容忍的。
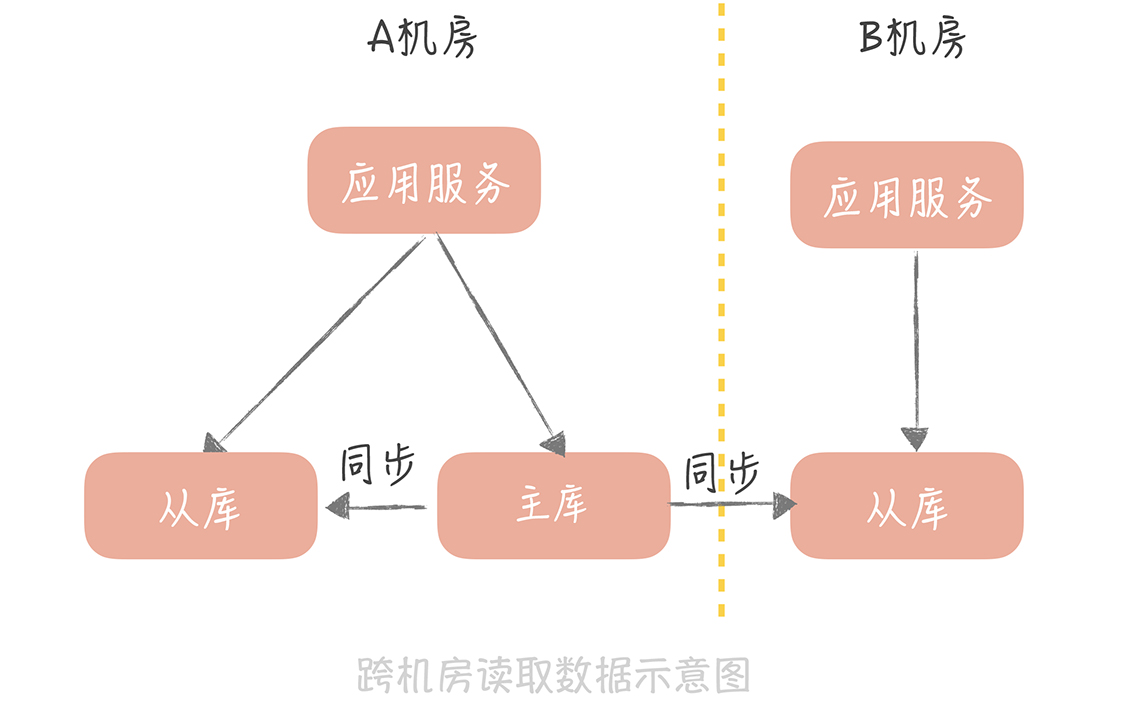
服务间的调用, 也应优先调用自己机房的服务 (使用注册中心分组订阅的能力)
异地多活
如果发生城市级的天灾人祸时, 同城多活就会出现问题, 所以要在多个城市部署多个节点 来保证存活
大前提和同城多活一样, 业务处理尽量在自己机房处理
同城多机房方案可以允许有跨机房数据写入的发生,但是数据的读取,和服务的调用应该尽量保证在同一个机房中。
异地多活方案则应该避免跨机房同步的数据写入和读取,而是采取异步的方式,将数据从一个机房同步到另一个机房。
三、常见的互联网分层架构
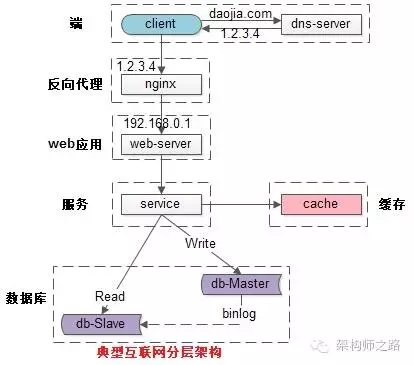
常见互联网分布式架构如上,分为:
(1)客户端层:典型调用方是浏览器browser或者手机应用APP
(2)反向代理层:系统入口,反向代理
(3)站点应用层:实现核心应用逻辑,返回html或者json
(4)服务层:如果实现了服务化,就有这一层
(5)数据-缓存层:缓存加速访问存储
(6)数据-数据库层:数据库固化数据存储
整个系统的高可用,又是通过每一层的冗余+自动故障转移来综合实现的。
和实现高并发一样,在每一层都做处理
四,总结
高可用HA(High Availability)是分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计减少系统不能提供服务的时间。
方法论上,高可用是通过冗余+自动故障转移来实现的。
整个互联网分层系统架构的高可用,又是通过每一层的冗余+自动故障转移来综合实现的,具体的:
(1)【客户端层】到【反向代理层】的高可用,是通过反向代理层的冗余实现的,常见实践是keepalived + virtual IP自动故障转移
(2)【反向代理层】到【站点层】的高可用,是通过站点层的冗余实现的,常见实践是nginx与web-server之间的存活性探测与自动故障转移
(3)【站点层】到【服务层】的高可用,是通过服务层的冗余实现的,常见实践是通过service-connection-pool来保证自动故障转移
(4)【服务层】到【缓存层】的高可用,是通过缓存数据的冗余实现的,常见实践是缓存客户端双读双写,或者利用缓存集群的主从数据同步与sentinel保活与自动故障转移;更多的业务场景,对缓存没有高可用要求,可以使用缓存服务化来对调用方屏蔽底层复杂性
(5)【服务层】到【数据库“读”】的高可用,是通过读库的冗余实现的,常见实践是通过db-connection-pool来保证自动故障转移
(6)【服务层】到【数据库“写”】的高可用,是通过写库的冗余实现的,常见实践是keepalived + virtual IP自动故障转移