[toc]
前言
它通过 「 分而治之 」 的方法尝试将所有可用的处理器内核使用起来帮助加速并行处理。
在实际使用过程中,这种 「 分而治之 」的方法意味着框架首先要 fork ,递归地将任务分解为较小的独立子任务,直到它们足够简单以便异步执行。然后,join 部分开始工作,将所有子任务的结果递归地连接成单个结果,或者在返回 void 的任务的情况下,程序只是等待每个子任务执行完毕。
Fork/Join框架是一个实现了ExecutorService接口的多线程处理器,它专为那些可以通过递归分解成更细小的任务而设计,最大化的利用多核处理器来提高应用程序的性能。
与其他ExecutorService相关的实现相同的是,Fork/Join框架会将任务分配给线程池中的线程。而与之不同的是,Fork/Join框架在执行任务时使用了工作窃取算法。
ForkJoin 有两大核心思想:
- 分治算法;
- 工作密取:为了充分利用 cpu 资源,一个工作线程执行完自己队列的任务之后,不会空闲,而是从其它队列里寻找任务。
使用场景:
ForkJoinPool 不是为了替代 ExecutorService,而是它的补充,在某些应用场景下性能比 ExecutorService 更好。
ForkJoinPool 主要用于实现“分而治之”的算法,特别是分治之后递归调用的函数,例如 quick sort 等。
ForkJoinPool 最适合的是计算密集型的任务,如果存在 I/O,线程间同步,sleep() 等会造成线程长时间阻塞的情况时,最好配合使用 ManagedBlocker。
ManagedBlocker 它可以控制在阻塞时增加并行数, 这样就不会卡死了
18 Fork/Join框架 · 深入浅出Java多线程 (redspider.group)
一文秒懂 Java Fork/Join - Java 一文秒懂 - 简单教程,简单编程 (twle.cn)
在Java8 parallelStream()中使用I/O + ManagedBlocker有什么问题吗? - IT宝库 (itbaoku.cn)
关于ForkJoinPool使用ManagedBlocker防线程阻塞而降低吞吐量的说明_heng_zou的博客-CSDN博客_forkjoin 阻塞
ManagedBlocker的使用和深入理解ForkJoin 有待提升
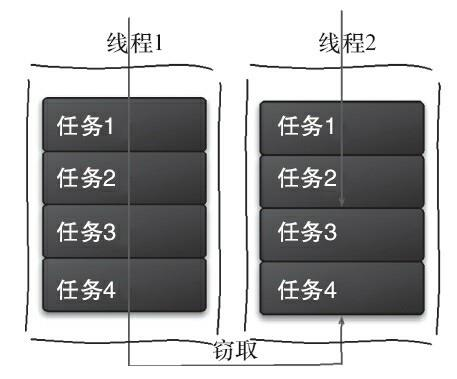
1. 工作窃取算法
工作窃取算法指的是在多线程执行不同任务队列的过程中,某个线程执行完自己队列的任务后从其他线程的任务队列里窃取任务来执行。
工作窃取流程如下图所示:

值得注意的是,当一个线程窃取另一个线程的时候,为了减少两个任务线程之间的竞争,我们通常使用双端队列来存储任务。被窃取的任务线程都从双端队列的头部拿任务执行,而窃取其他任务的线程从双端队列的尾部执行任务。
另外,当一个线程在窃取任务时要是没有其他可用的任务了,这个线程会进入阻塞状态以等待再次“工作”。
工作窃取算法的优点: 充分利用线程进行并行计算,减少了线程间的竞争。
工作窃取算法的缺点: 在某些情况下还是存在竞争,比如双端队列里只有一个任务时。并且该算法会消耗了更多的系统资源,比如创建多个线程和多个双端队列。
2. 源码解释
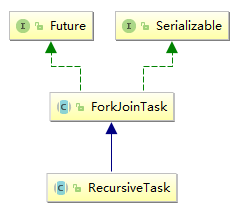
2.1 ForkJoinTask
ForkJoinTask代表运行在ForkJoinPool中的任务。
主要方法:
- fork() 在当前线程运行的线程池中安排一个异步执行。简单的理解就是再创建一个子任务。
- join() 当任务完成的时候返回计算结果。
- invoke() 开始执行任务,如果必要,等待计算完成。
子类:
- RecursiveAction 一个递归无结果的ForkJoinTask(没有返回值)
- RecursiveTask 一个递归有结果的ForkJoinTask(有返回值)
ForkJoinTask是一个类似普通线程的实体,但是比普通线程轻量得多。
fork()方法:使用线程池中的空闲线程异步提交任务
// 本文所有代码都引自Java 8
public final ForkJoinTask<V> fork() {
Thread t;
// ForkJoinWorkerThread是执行ForkJoinTask的专有线程,由ForkJoinPool管理
// 先判断当前线程是否是ForkJoin专有线程,如果是,则将任务push到当前线程所负责的队列里去
if ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread)
((ForkJoinWorkerThread)t).workQueue.push(this);
else
// 如果不是则将线程加入队列
// 没有显式创建ForkJoinPool的时候走这里,提交任务到默认的common线程池中
ForkJoinPool.common.externalPush(this);
return this;
}
其实fork()只做了一件事,那就是把任务推入当前工作线程的工作队列里。
join()方法:等待处理任务的线程处理完毕,获得返回值。来看下join()的源码:
public final V join() {
int s;
// doJoin()方法来获取当前任务的执行状态
if ((s = doJoin() & DONE_MASK) != NORMAL)
// 任务异常,抛出异常
reportException(s);
// 任务正常完成,获取返回值
return getRawResult();
}
/**
* doJoin()方法用来返回当前任务的执行状态
**/
private int doJoin() {
int s; Thread t; ForkJoinWorkerThread wt; ForkJoinPool.WorkQueue w;
// 先判断任务是否执行完毕,执行完毕直接返回结果(执行状态)
return (s = status) < 0 ? s :
// 如果没有执行完毕,先判断是否是ForkJoinWorkThread线程
((t = Thread.currentThread()) instanceof ForkJoinWorkerThread) ?
// 如果是,先判断任务是否处于工作队列顶端(意味着下一个就执行它)
// tryUnpush()方法判断任务是否处于当前工作队列顶端,是返回true
// doExec()方法执行任务
(w = (wt = (ForkJoinWorkerThread)t).workQueue).
// 如果是处于顶端并且任务执行完毕,返回结果
tryUnpush(this) && (s = doExec()) < 0 ? s :
// 如果不在顶端或者在顶端却没未执行完毕,那就调用awitJoin()执行任务
// awaitJoin():使用自旋使任务执行完成,返回结果
wt.pool.awaitJoin(w, this, 0L) :
// 如果不是ForkJoinWorkThread线程,执行externalAwaitDone()返回任务结果
externalAwaitDone();
}
我们在之前介绍过说Thread.join()会使线程阻塞,而ForkJoinPool.join()会使线程免于阻塞,下面是ForkJoinPool.join()的流程图:

2.2 ForkJoinWorkerThread
ForkJoinWorkerThread代表ForkJoinPool线程池中的一个执行任务的线程。
/**
* Default ForkJoinWorkerThreadFactory implementation; creates a
* new ForkJoinWorkerThread.
*/
static final class DefaultForkJoinWorkerThreadFactory implements ForkJoinWorkerThreadFactory {
public final ForkJoinWorkerThread newThread(ForkJoinPool pool) {
return new ForkJoinWorkerThread(pool);
}
}
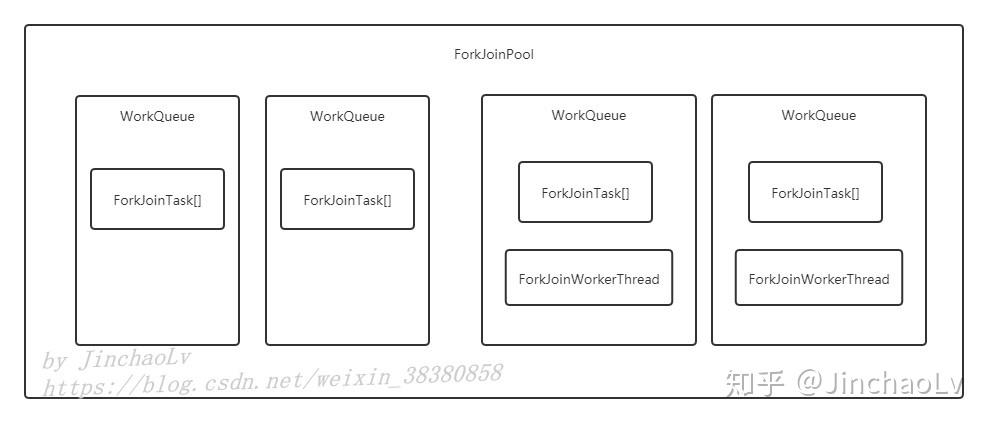
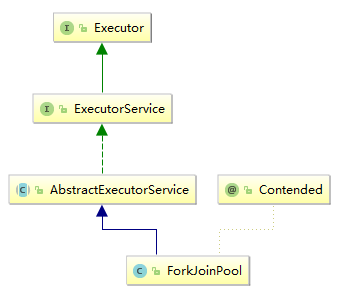
2.3 ForkJoinPool
ForkJoinPool是用于执行ForkJoinTask任务的执行(线程)池。
ForkJoinPool管理着执行池中的线程和任务队列,此外,执行池是否还接受任务,显示线程的运行状态也是在这里处理。
我们来大致看下ForkJoinPool的源码:
@sun.misc.Contended
public class ForkJoinPool extends AbstractExecutorService {
// 任务队列
volatile WorkQueue[] workQueues;
// 线程的运行状态
volatile int runState;
// 创建ForkJoinWorkerThread的默认工厂,可以通过构造函数重写
public static final ForkJoinWorkerThreadFactory defaultForkJoinWorkerThreadFactory;
// 公用的线程池,其运行状态不受shutdown()和shutdownNow()的影响
static final ForkJoinPool common;
// 私有构造方法,没有任何安全检查和参数校验,由makeCommonPool直接调用
// 其他构造方法都是源自于此方法
// parallelism: 并行度,
// 默认调用java.lang.Runtime.availableProcessors() 方法返回可用处理器的数量
private ForkJoinPool(int parallelism,
ForkJoinWorkerThreadFactory factory, // 工作线程工厂
UncaughtExceptionHandler handler, // 拒绝任务的handler
int mode, // 同步模式
String workerNamePrefix) { // 线程名prefix
this.workerNamePrefix = workerNamePrefix;
this.factory = factory;
this.ueh = handler;
this.config = (parallelism & SMASK) | mode;
long np = (long)(-parallelism); // offset ctl counts
this.ctl = ((np << AC_SHIFT) & AC_MASK) | ((np << TC_SHIFT) & TC_MASK);
}
/**
* Creates and returns the common pool, respecting user settings
* specified via system properties.
* jdk8 提供了一个简单的pool,(默认并行数是cpu核数-1), Lambda中(所有)的并行流用的就是这个方法,所以乱用并行流可能会导致线程阻塞卡死
*/
private static ForkJoinPool makeCommonPool() {
int parallelism = -1;
ForkJoinWorkerThreadFactory factory = null;
UncaughtExceptionHandler handler = null;
try { // ignore exceptions in accessing/parsing properties
String pp = System.getProperty
("java.util.concurrent.ForkJoinPool.common.parallelism");
String fp = System.getProperty
("java.util.concurrent.ForkJoinPool.common.threadFactory");
String hp = System.getProperty
("java.util.concurrent.ForkJoinPool.common.exceptionHandler");
if (pp != null)
parallelism = Integer.parseInt(pp);
if (fp != null)
factory = ((ForkJoinWorkerThreadFactory)ClassLoader.
getSystemClassLoader().loadClass(fp).newInstance());
if (hp != null)
handler = ((UncaughtExceptionHandler)ClassLoader.
getSystemClassLoader().loadClass(hp).newInstance());
} catch (Exception ignore) {
}
if (factory == null) {
if (System.getSecurityManager() == null)
factory = defaultForkJoinWorkerThreadFactory;
else // use security-managed default
factory = new InnocuousForkJoinWorkerThreadFactory();
}
if (parallelism < 0 && // default 1 less than #cores
(parallelism = Runtime.getRuntime().availableProcessors() - 1) <= 0)
parallelism = 1;
if (parallelism > MAX_CAP)
parallelism = MAX_CAP;
return new ForkJoinPool(parallelism, factory, handler, LIFO_QUEUE,"ForkJoinPool.commonPool-worker-");
}
}
2.4 WorkQueue
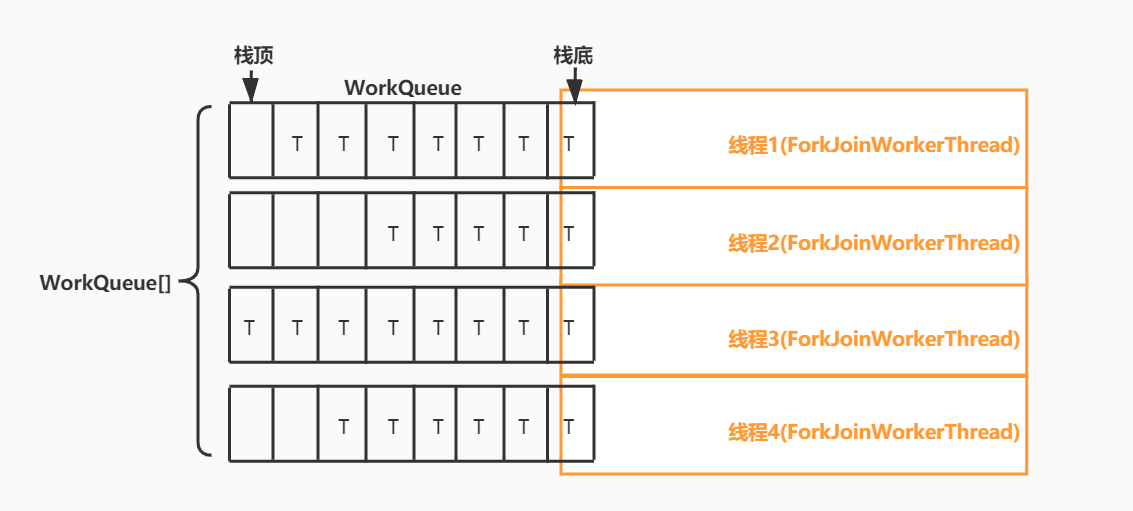
双端队列,ForkJoinTask们存放在这里。
当工作线程在处理自己的工作队列时,会从队列首取任务来执行(FIFO);如果是窃取其他队列的任务时,窃取的任务位于所属任务队列的队尾(LIFO)。
ForkJoinPool与传统线程池最显著的区别就是它维护了一个工作队列数组(volatile WorkQueue[] workQueues,ForkJoinPool中的每个工作线程都维护着一个工作队列)。
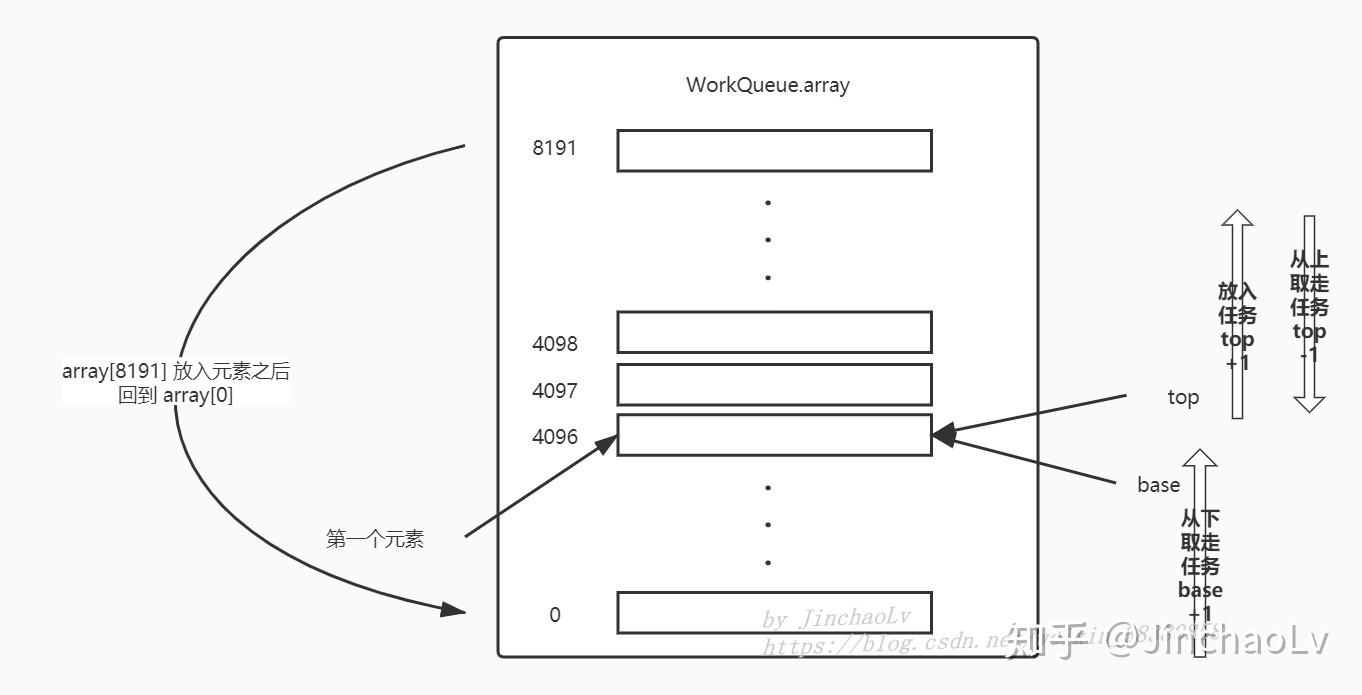
- array 初始容量 8192;
- 第一个任务放在 4096,似乎是因为操作系统内存的原因;
- 8191 的位置放入任务之后,还是会回到 0 的位置;
- 初始 base = top = 4096;
- 从上面放入一个任务 top + 1,不会从下面放入任务;
- LIFO 模式自己线程从上面取走任务 top - 1;
- FIFO 模式自己线程从下面取走任务 base + 1;
- 被其它线程从下面窃取任务,base + 1,其它线程不会从上面窃取任务;
- 数组 size 由 top - base 获得;
- 从 8191 回到 0 之后,top 和 base 会继续往上加,索引值通过取余获得。
static final int INITIAL_QUEUE_CAPACITY = 1 << 13; // 2^13 = 8192
static final int MAXIMUM_QUEUE_CAPACITY = 1 << 26; // 2^26 = 67108864
如果队列长度不够了,会自动两倍扩容的
/**
* Callback from ForkJoinWorkerThread constructor to establish and
* record its WorkQueue.
*
* @param wt the worker thread
* @return the worker's queue
*/
final WorkQueue registerWorker(ForkJoinWorkerThread wt) {
UncaughtExceptionHandler handler;
wt.setDaemon(true); // configure thread
if ((handler = ueh) != null)
wt.setUncaughtExceptionHandler(handler);
WorkQueue w = new WorkQueue(this, wt);
int i = 0; // assign a pool index
int mode = config & MODE_MASK;
int rs = lockRunState();
try {
WorkQueue[] ws; int n; // skip if no array
if ((ws = workQueues) != null && (n = ws.length) > 0) {
int s = indexSeed += SEED_INCREMENT; // unlikely to collide
int m = n - 1;
i = ((s << 1) | 1) & m; // odd-numbered indices
if (ws[i] != null) { // collision
int probes = 0; // step by approx half n
int step = (n <= 4) ? 2 : ((n >>> 1) & EVENMASK) + 2;
while (ws[i = (i + step) & m] != null) {
if (++probes >= n) {
// 这里用 copyOf 进行复制, 这段代码太难读了,以后再来分析吧
workQueues = ws = Arrays.copyOf(ws, n <<= 1);
m = n - 1;
probes = 0;
}
}
}
w.hint = s; // use as random seed
w.config = i | mode;
w.scanState = i; // publication fence
ws[i] = w;
}
} finally {
unlockRunState(rs, rs & ~RSLOCK);
}
wt.setName(workerNamePrefix.concat(Integer.toString(i >>> 1)));
return w;
}
2.5 runState
ForkJoinPool的运行状态。SHUTDOWN状态用负数表示,其他用2的幂次表示。
总结
对于一个 new ForkJoinPool(),执行任务全流程如下:
ForkJoinPool 初始化 parallelism size = cpu 逻辑核心数,没有队列,没有线程;
向 ForkJoinPool 提交一个任务;
初始化队列数组,容量为 2 * Max { parallelism size, 2 ^ n };
创建一个没有线程的队列,容量为 2 ^ 13,随机放在队列数组的某一个偶数索引处;
任务存入这个队列索引值为 2 ^ 12 处;
再创建一个有线程的队列,容量为 2 ^ 13,随机放在队列数组的某一个奇数索引处;
线程启动;
线程从随机一个队列开始,遍历所有队列,最终扫描找到前面提交的任务,并从其所在队列取出;
线程执行任务,拆分出两个子任务;
- 如果用 invokeAll 提交,则一个进入线程所在队列,另一个直接在线程里执行;
- 如果用 fork 提交,则两个都进入线程所在队列;
提交的子任务触发创建新的线程,及与其对应的队列,还是在奇数索引处;
提交的子任务可能仍然被当前线程执行,可能被其它线程窃取;
线程在子任务处 join,join 期间会尝试从窃取自己任务的线程那里窃取任务执行;
- 优先窃取队列底部;
- 队列没有任务则窃取其正在 join 的任务;
- 还没有则阻塞自己等待被唤醒,在阻塞之前会补偿一个活跃线程;
提交的子任务不管被哪个线程执行,仍会重复上述拆分、提交、窃取、阻塞流程;
当任务被拆分的足够细,则会真正开始计算;
计算完成从递归一层一层返回;
最终所有子任务都完成,得到结果;
如果不再提交任务,所有线程扫描不到任务进入 inactive 状态;
最终,所有线程销毁,所有奇数索引位的队列回收,ForkJoinPool 中只剩下一个最初创建的在偶数索引位的队列。
thread_fork/join并发框架2 - dengzy - 博客园 (cnblogs.com)
[笔记][Java7并发编程实战手册]5.Fork\Join(Java1.7新特性)框架_代码有毒的博客-CSDN博客