1. 为什么需要prompt
大模型以前的模型要针对一个具体问题选择数据/做标注, 模型能力难以迁移, 往往是一个场景就要做一个模型, 比如人脸识别不好迁移到物体识别上, 而大模型的知识和能力本源于预训练. 一开始并不带着一个特殊的具体任务。而是通过大量数据训练一个能适配多种任务的模型, 这是机器学习的一大突破
大模型本质是基于注意力的自回归函数, 通过前序token预测下一个token, 这种特性使得我们可以使用prompt (用做前序token), 指定模型后续输出的概率范围, 从而让模型完成不同的任务
从另一个角度来说, 我们使用prompt 把大模型置于某个特定的上下文(环境), 使大模型从预训练注入的无数知识中激发出特定领域的知识和能力,例如 设置不同的 prompt 对同一个问题会有不同的回答。
比如 “介绍一下李白”
如果没有指定prompt, 大模型可能会介绍中国诗仙李白或者王者荣耀中的李白技能。
什么是token?
文本被切分后,模型能处理的最小基本单位
在中文语境下,它可能是:
一个词:如“模型”
一个字:如“模”、“型”
一个子词:如“模”和“型”分开,或者英文里的“play”和“ing”
标点符号:如“。”、“,”
甚至是一个特殊控制符(如表示句子开始的
<BOS>)在英文语境下, 它也可以是一个单词, 一个标点符号.
2. prompt和SFT
本文主要介绍提engineer提升模型效果。
本文主要介绍prompt 提升模型效果。但需要注意的是,并非所有的问题/指标都合适使用prompt来解决。
模型SFT(Supervised Fine-Tuning,监督微调) 是目前业务最常用的模型后训练的方式。其目标也和prompt类似,让模型能持续生成符合你要求的内容,
prompt和微调并不是相互冲突的方案,而更像是逐步递进的两种策略。通常情况下建议优先尝试prompt,因为它更快更低成本也更容易迭代。如果prompt达不到业务效果的期望,包括在精度、领域适配等方面不够理想时,再选择微调。
SFT(Supervised Fine-Tuning)即大型语言模型的有监督微调。是一种使用有监督学习来微调预训练语言模型的模型。SFT 目标是使预训练语言模型(如GPT-3、BERT等)能够更好地完成特定的任务。他的工作原理是将预训练语言模型作为基础,然后使用有监督学习来调整模型的参数。有监督学习是指使用带标签的数据来训练模型。在 SFT 过程中,标签通常是目标任务的正确答案。
例如,假设有一个预训练好的语言模型GPT-3,你想要它更好地回答法律领域的问题。你可以收集一些法律文档,并对这些文档进行问答标注,然后通过监督微调步骤,使GPT-3在回答法律相关问题时表现得更好。
所以从成本和时效性来说,调整prompt会来得更快更明显
3. prompt基础
3.1 消息角色和指令遵循
在 open AI中支持设定 system,user,assistant 三种角色的信息,
system: 表示一些系统级别的指令或信息,通常有应用程序开发者提供指令, 指令优先级最高
user: 表示由终端用户提供的指令, 比如用户的提问信息, 指令优先级低于system
assistant: 表示模型生成的消息
3.2 需要关注的模型参数
context window: 模型只能处理特定数量的数据,这种限制称为上下文窗口。它以token来衡量,同一个模型的上下文窗口一般是固定的。
上下文窗口的大小,既受资源的制约(transform 决定计算志愿时上下文长度的2次方),也受训练数据的影响。
一般粗略估算 1token 约等于 1.5~1.8个中文字符
temperature: 翻译为温度, 表示生成结果的随机性。 温度降低会导致结果更少的随机,当温度接近于0时,模型将变得确定性和重复。当温度等于0时表示每个token都取概率最高的结果,这将导致同样的输入,每次都会获得同样的成为贪婪解码。主流模型都不建议使用贪婪解码
- deepseek V3 官方建议温度等于0.3,R1版本为0.5~0.7。
top-p: 对应解码算法top-p。大模型token采样参数p取值范围是[0~1),决定了模型选择token的累计概率范围。例如设置Top p为0.95,表示预测token 会从前n个中积累概率达95%的token中选择,舍弃后面的5%的token。并不会所有的预测值都会保留
top-k: 对应解码算法top-k。大模型token采样参数k,取值范围是[0~20],控制每次生成token时从前k个概率最高的选项中进行选择。
所以大模型会同时用上 top-p和top-k, 解码顺序是先top-k, 然后是top-p, 所以就是 选排名前N的token, 然后从这些token中递减序列选择达到 概率为P的所有token。 若经过top-k后所有的token概率加起来都未达到P概率, 则会保留所有的token, 此时解码规则退化为 贪婪解码
4. prompt推荐写法
一些技巧
让大模型帮你生成prompt
从零开始创建提示和模式可能非常耗时,因此使用大模型自动生成prompt,可以帮助你快速上手,然后你可以在此基础上继续迭代。
在prompt中提供示例
示例 是大模型生成质量的关键秘诀
通过在提示词中加入几个精心设计的事例,可以显著提高大模型输出内容的准确性与一致性和整体质量。这种技巧被称为少量样本提示或者上下文学习。尤其适用于需要结构化输出或遵循特定格式的任务。
如何设计高质量示例
为了获得最佳效果,建议示例具备以下特点
相关性: 示例应真实贴合您的实际使用场景。
多样性: 示例应覆盖边缘情况与潜在挑战。同时避免过度雷同,以防模型误学非预期模式。
清晰性,建议使用
标签包裹单个事例,多个事例则用 标签统一管理,确保结构清晰,易于识别。
为模型分配角色
给大模型明确的设定一个角色,有助于模型更有效的理解并完成特定类型的任务,尤其当你的任务指令还不够详细或清晰时,角色设定可以起到显著的辅助作用。
你可以在prompt中明确告诉大模型,需要以特定模型的身份或视角来回应你的请求。比如
你是一位专业的数据分析师,擅长用Python和sql处理数据。
你是一位有10年经验的文案策划,风格幽默风趣,擅长撰写短视频脚本。
角色设定效果的局限性
有人在设计提示词时会堆叠大量的角色扮演语句,比如"你是一位某领域的顶尖专家",“你是一位丰富经验的顾问”。但模型输出依然不理想,问题往往不在于角色设定是否生效,而是任务描述本身是否足够清晰明确。
事实上,当你提供的任务说明已经非常具体,清晰且完整时,模型往往已经能够很好地理解你的意图,并准确完成任务。此时再加入角色设定,提升效果可能十分有限。
所以只有你提供的内容较为模糊,指令不清晰,这时适当引入角色设定,有助于模型理解语境和目标,能够优化该领域的通用任务的输出结果,
用 markdown 标题或者xml标签的结构化描述
当prompt包含多个组成部分时,你可以通过组合使用markdown格式和xml格式,帮助模型理解 提示词和上下文数据的逻辑边界。
减少模型幻觉
模型知识基于预训练的数据,对于训练数据中出现频率较低的知识,大模型会有一定的概率出现幻觉。很难完全规避,只能通过rag(检索增强生成)降低幻觉的概率。比如
像大模型必须引用检索资料回答,一般用于联网检索。(每一句回答后面像论文一样展示引用的文章链接)
给模型提供一个选项,让他可以说不知道问题的答案,一般用于内部知识检索。(在prompt中写明 如果没有足够的知识来回答用户, 必须回复"我没有足够的信息来回答这个问题")
Jinja模版
Jinja是一种流行的Python模板引擎,常用于生成动态内容,它可以将变量、逻辑条件和循环嵌入到文本中。从而动态生成复杂的输出。它能够大幅提高prompt的复用性和动态性,通过变量差值,条件判断和循环的功能。可以灵活生成复杂的提示词,从而提升模型响应的准确性和多样性。
使用场景:
使用大模型的时候,我们会发现当prompt的指令越多,模型指令遵循的能力就会下降,这是我们只能精简prompt。把没那么重要的指令删掉。有了Jinja模版之后,可以动态生成poment。例如用户输入了某某关键字就注入prompt,否则就不注入. 又例如模型调用特定工具之后就注。注入特定的prompt来指导模型怎么回答,否则就不注入。
使用传入参数来拼接prompt,例如使用循环语句来拼接传入的多个数组。
长上下文prompt
将长上下文数据置于顶部,将你的长文档和输入内容放置在提示词的顶部位于query 示例之前, 这能显著提升大模型的表现,这是因为大模型的目标是预测下一个token,而指令在生成token的附近能够提升模型的指令遵循。
anthropic测试表明, 查询末尾添加问题可使响应质量提升高达30%,尤其针对复杂的多文本输入场景。
总结就是, 长文本放顶部, 用户的问题放在尾部,
5. prompt进阶
5.1 核心方法: 迭代
prompt Engineer之所以被称为engineer,是因为它包含了系统化的试错与改进进程,与人类交流不同,与ai模型交流时你可以随时重新开始,独立测试不同方案,而不会受到之前交互的干扰。这种能够不断实验和设计的能力,正是prompt engineer的精髓所在。
真正的提示词工程师在短时间内可能向模型发送数10甚至上百条提示,不断调整和完善,直到达到理想效果,这种迭代不仅仅是修改几个词那么简单,而是深入理解模型反应并据此调整策略的过程。
为什么需要迭代
模型≠人: 他不会像同事那样主动做澄清回答,你得在反复试错中把隐藏假设补全。
输入千变万化: 真实用户,真实数据永远会出现意料之外的格式/错别字/噪声。
能力边界未知: 只有把模型推到极致,才能发现真正的性能拐点和风险点。

5.2 自动化迭代
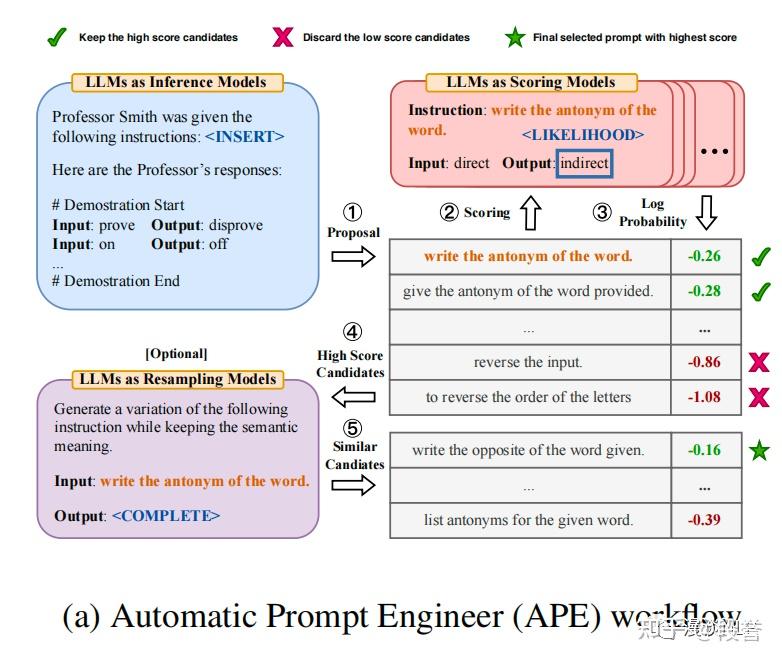
如果能够总结出明确的业务评估指标,我们就可以把prompt的迭代自动化。
比如需要使用大模型简化一篇文章, 所以需要迭代出合适的prompt, 以下是一个简单示例:
使用 [简化prompt v1] 输入原始内容, 得出简化文本
使用[rank prompt] 根据评估指标- 可读性/完整性/忠实性 —-评判简化效果
通过 [修改prompt的大模型] 根据评判结果优化简化prompt, 输出 [简化 prompt v2]
使用 [简化 prompt v2]继续循环
5.3 如何使用prompt实现agent
进一步学习 agent
什么是agent?
5.3.1 通过prompt实现 function call
function call (函数调用) 是指大模型能够理解并执行函数/工具/插件的能力. function call 是所有agent 框架的核心能力
function call最基础的链路如下:
系统(工程链路)第1次调用模型,模型以结构化的格式输出给工具id和参数。
系统执行对应的工具,再把工具执行结果放入上下文。
系统第二次调用模型
这里的重点是 “模型以结构化的格式输出工具id和参数”。一般是通过prompt的方法让模型输出。而大部分模型会针对function call的特定格式做后训练, 我们的prompt最好跟模型的模版一致
5.3.2 agent prompt
模型在关键能力上的成熟—-理解复杂输入,进入推理规划,可靠使用工具及从错误中恢复— 使得agent生产环境中崭露头角。
在明确任务后,agent就自主规划执行, 执行阶段的关键在于, agent需要在每个步骤从环境中获取"真实反馈"(如工具调用结果或代码执行) 来评估进展, 通常由agent自主决策何时终止,但有时也会由环境设置停止条件。(如最大循环次数)
Agent能复杂处理任务,但它的实现往往很简单,通常只是大模型在循环中 基于环境反馈使用工具,因此精心设计agent prompt和 工具及其说明文档至关重要。
需要注意的是,prompt只是构成agent的能力的其中一部分, 模型的agentic能力(持续与环境交互以完成特定任务)是更重要的一环。例如在同样的prompt下, Claude 的agentic 能力远高于Deepseek的模型
为了充分发挥gpt4.1的agent的能力,我们建议在所有代理提示中包含三种关键。以下提供专门针对智能代码编码工作流进行了优化.
持久化: 这确保模型理解它正在进入多轮对话,并防止其过早的将控制权交还给用户,即没有调用所有需要的工具就结束。
工具调用: 这鼓励模型充分利用其工具,并减少其产生幻觉或猜测答案的可能性。
规划[可选]: 该功能确保模型以文本形式明确规划并反思每次工具调用, 而非仅通过串联一系列工具调用来完成任务。
案例如下:
你是一个agent, 你可以在回复的 开始,中间或者结束调用0个, 一个或者多个工具。查询外部资料和执行操作,无需用户确认和授权,从而解答用户的问题,帮助用户完成多种多样的任务。停止调用工具后,系统会自动交还给控制权给用户,请只有在确定问题已解决后才终止调用工具。
调用工具的原则:
在每一轮对话中,你应尽大努力完成用户当前回合提出的任务,持续调用工具,直到满足用户请求。
在每轮调用工具之前,你必须进行充分的规划,并在每次调用工具之后进入深入反思其结果,以提升解决问题的能力和深度思考的能力。
如果没有可以使用的工具,或者你认为不需要使用工具,你可以直接回答用户。