[TOC]
释放内存其实在每次处理命令时都会执行, 只是满足判断条件才执行 , 例如内存满了, 需要淘汰key等等条件, 若发现已用内存超出
maxmemory,会计算需释放的内存量。这个释放内存大小=已使用内存量-maxmemory。
redis中的LRU实现
redis没有使用标准的LRU算法, 只是近似的LRU算法, 因为嫌LinkedList占用的空间太大了(因为起码要记录头尾指针)
简述: redis通过计算每个key的闲置时间来决定是否要选它淘汰(全局时钟 减去 当前key的访问时钟), redis会随机选几个key, 它们的闲置时间都要大于一个阈值(其实会存入一个pool, 这个阈值就是pool中最小的闲置时间), 当内存不够时, 就从这几个key中淘汰闲置时间最大的值
首先看一下全局时钟定义
#define LRU_BITS 24
struct redisServer {
pid_t pid; /* Main process pid. */
char *configfile; /* Absolute config file path, or NULL */
…..
unsigned lruclock:LRU_BITS; /* Clock for LRU eviction */
...
};
redisServer 中包含了redis服务器启动之后的基本信息(PID,配置文件路径,serverCron运行频率hz等),外部可调用模块信息,网络信息,RDB/AOF信息,日志信息,复制信息等等。
上述结构体中lruclock:LRU_BITS,其中存储了服务器自启动之后的lru时钟,该时钟是全局的lru时钟。该时钟100ms更新一次。
可以通过hz来调整,默认情况hz=10,因此每1000ms/10=100ms执行一次定时任务
因此lrulock最大能到(2**24-1)/3600/24 = 194天,如果超过了这个时间,lrulock重新开始。对于redis server来说,server.lrulock表示的是一个全局的lrulock,
如果全局时钟 小于 对象时钟, 则会再加上时钟最大值
REDIS_LRU_CLOCK_MAX, 也就是 194天 的秒数, 相当于是第二轮了/* Given an object returns the min number of seconds the object was never * requested, using an approximated LRU algorithm. */ #define REDIS_LRU_CLOCK_MAX ((1<<REDIS_LRU_BITS)-1) /* Max value of obj->lru */ #define REDIS_LRU_CLOCK_RESOLUTION 1 /* LRU clock resolution in seconds */ unsigned long estimateObjectIdleTime(robj *o) { if (server.lruclock >= o->lru) { return (server.lruclock - o->lru) * REDIS_LRU_CLOCK_RESOLUTION; } else { return ((REDIS_LRU_CLOCK_MAX - o->lru) + server.lruclock) * REDIS_LRU_CLOCK_RESOLUTION; } }
那么对于每个redisObject都有一个自己的lrulock。这样每redisObject就可以根据自己的lrulock和全局的server.lrulock比较,来确定是否能够被淘汰掉。
再看一下 redisObject的实现
#define REDIS_LRU_BITS 24
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
// 从这里看出, 这个字段在不同淘汰策略下, 存的内容是不一样的
unsigned lru:LRU_BITS; /* LRU time (relative to server.lruclock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits decreas time). */
int refcount;
void *ptr;
} robj
在Redis的dict中每次按key获取一个值的时候,都会调用lookupKey函数,如果配置使用了LRU模式,该函数会更新value中的lru字段为当前秒级别的时间戳
robj *lookupKey(redisDb *db, robj *key, int flags) {
...
if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) { //如果配置的是lfu方式,则更新lfu
updateLFU(val);
} else {
val->lru = LRU_CLOCK();//否则按lru方式更新
}
...
}
第一次随机选取的key都会放入一个pool中(pool的大小为16),pool中的key是按lru大小顺序排列的。接下来每次随机选取的key lru值必须大于pool中最小的lru才会继续放入,直到将pool放满。放满之后,每次如果有新的key需要放入,需要将pool中lru最大的一个key取出。淘汰的时候,直接从pool中选取一个lru最大的值然后将其淘汰。这样一来,每次移除的Key并不仅仅是随机选择的N个Key里面最大的,而且还是pool里面idle time最大的
随机选的key的数量默认为5, 由 server.maxmemory_samples 控制, maxmemory_samples 就是样本大小, 值越大, 约接近LRU, 淘汰的正确率越高, 性能消耗也越大
采用"pool",把一个全局排序问题 转化成为了 局部的比较问题。(尽管排序本质上也是比较,囧)。要想知道idle time 最大的key,精确的LRU需要对全局的key的idle time排序,然后就能找出idle time最大的key了。但是可以采用一种近似的思想,即随机采样(samping)若干个key,这若干个key就代表着全局的key,把samping得到的key放到pool里面,每次采样之后更新pool,使得pool里面总是保存着随机选择过的key的idle time最大的那些key。需要evict key时,直接从pool里面取出idle time最大的key,将之evict掉。这种思想是很值得借鉴的。
redis中的LFU实现
简述: 它和LRU规则一样, 利用在key中时间钟字段, 不过把内部时钟的24位分成两部分,前16位还代表时钟,后8位代表一个计数器。8位只能代表255,但是redis并没有采用线性上升的方式,而是结合增长因子来计数, 而且还有衰退因子来减少计数。也会和LRU一样, 存在一个淘汰池, 从淘汰池中redis会对内部时钟最小的key进行淘汰(最小表示最不频繁使用),注意这个过程也是根据策略随机选择键
在LFU模式下,Redis对象头的24bit lru字段被分成两段来存储,高16bit存储ldt(Last Decrement Time),低8bit存储logc(Logistic Counter)。
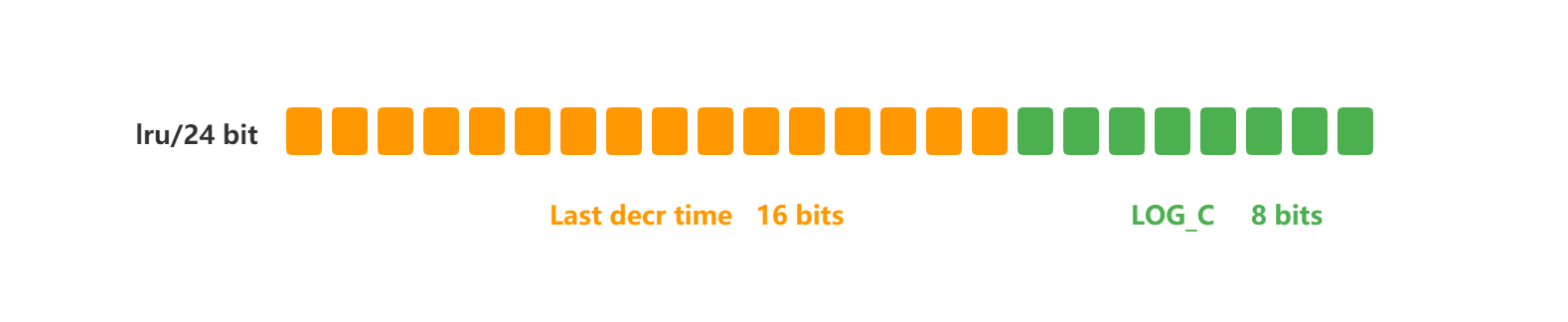
ldt(Last Decrement Time)
高16bit用来记录最近一次计数器降低的时间,由于只有8bit,存储的是Unix分钟时间戳取模2^16,16bit能表示的最大值为65535(65535/24/60≈45.5),大概45.5天会折返(折返指的是取模后的值重新从0开始)。
源码如下:
/* Return the current time in minutes, just taking the least significant
* 16 bits. The returned time is suitable to be stored as LDT (last decrement
* time) for the LFU implementation. */
// server.unixtime是Redis缓存的Unix时间戳
// 可以看出使用的Unix的分钟时间戳,取模2^16
unsigned long LFUGetTimeInMinutes(void) {
return (server.unixtime/60) & 65535;
}
/* Given an object last access time, compute the minimum number of minutes
* that elapsed since the last access. Handle overflow (ldt greater than
* the current 16 bits minutes time) considering the time as wrapping
* exactly once. */
unsigned long LFUTimeElapsed(unsigned long ldt) {
// 获取系统当前的LFU time
unsigned long now = LFUGetTimeInMinutes();
// 如果now >= ldt 直接取差值
if (now >= ldt) return now-ldt;
// 如果now < ldt 增加上65535
// 注意Redis 认为折返就只有一次折返,多次折返也是一次,我思考了很久感觉这个应该是可以接受的,本身Redis的淘汰算法就带有随机性
return 65535-ldt+now;
}
logc(Logistic Counter)
低8位用来记录访问频次,8bit能表示的最大值为255,logc肯定无法记录真实的Rediskey的访问次数,其实从名字可以看出存储的是访问次数的对数值,每个新加入的key的logc初始值为5(LFU_INITI_VAL),这样可以保证新加入的值不会被首先选中淘汰;logc每次key被访问时都会更新;此外,logc会随着时间衰减。
logc 算法调整
redis.conf 提供了两个配置项,用于调整LFU的算法从而控制Logistic Counter的增长和衰减。
-- 用于调整Logistic Counter的增长速度,lfu-log-factor值越大,Logistic Counter增长越慢。
lfu-log-factor 10
-- 用于调整Logistic Counter的衰减速度,它是一个以分钟为单位的数值,默认值为1,;lfu-decay-time值越大,衰减越慢。
lfu-decay-time 1
增长的源码:
/* Logarithmically increment a counter. The greater is the current counter value
* the less likely is that it gets really implemented. Saturate it at 255. */
uint8_t LFULogIncr(uint8_t counter) {
// Logistic Counter最大值为255
if (counter == 255) return 255;
// 取一个0~1的随机数r
double r = (double)rand()/RAND_MAX;
// counter减去LFU_INIT_VAL (LFU_INIT_VAL为每个key的Logistic Counter初始值,默认为5)
double baseval = counter - LFU_INIT_VAL;
// 如果衰减之后已经小于5了,那么baseval < 0取0
if (baseval < 0) baseval = 0;
// lfu-log-factor在这里被使用
// 可以看出如果lfu_log_factor的值越大,p越小
// r < p的概率就越小,Logistic Counter增加的概率就越小(因此lfu_log_factor越大增长越缓慢)
double p = 1.0/(baseval*server.lfu_log_factor+1);
if (r < p) counter++;
return counter;
}
衰减的源代码:
/* If the object decrement time is reached decrement the LFU counter but
* do not update LFU fields of the object, we update the access time
* and counter in an explicit way when the object is really accessed.
* And we will times halve the counter according to the times of
* elapsed time than server.lfu_decay_time.
* Return the object frequency counter.
*
* This function is used in order to scan the dataset for the best object
* to fit: as we check for the candidate, we incrementally decrement the
* counter of the scanned objects if needed. */
unsigned long LFUDecrAndReturn(robj *o) {
// 获取lru的高16位,也就是ldt
unsigned long ldt = o->lru >> 8;
// 获取lru的低8位,也就是logc
unsigned long counter = o->lru & 255;
// 根据配置的lfu-decay-time计算Logistic Counter需要衰减的值
unsigned long num_periods = server.lfu_decay_time ? LFUTimeElapsed(ldt) / server.lfu_decay_time : 0;
if (num_periods)
counter = (num_periods > counter) ? 0 : counter - num_periods;
return counter;
}
LFU 与 LRU 有一个共同点,当内存达到max_memory时,选择key是随机抓取的,因此Redis为了使这种随机性更加准确,设计了一个淘汰池,这个淘汰池对于LFU和LRU算的都适应,只是淘汰池的排序算法有区别而已。
扩展
淘汰池的更新策略
这个淘汰池就是使用LRU和LFU时, 需要淘汰key时, 是从淘汰池按时间钟来淘汰, 源码如下:
void evictionPoolPopulate(int dbid, dict *sampledict, dict *keydict, struct evictionPoolEntry *pool) {
int j, k, count;
dictEntry *samples[server.maxmemory_samples];
count = dictGetSomeKeys(sampledict,samples,server.maxmemory_samples);
for (j = 0; j < count; j++) {
unsigned long long idle;
sds key;
robj *o;
dictEntry *de;
de = samples[j];
key = dictGetKey(de);
/* If the dictionary we are sampling from is not the main
* dictionary (but the expires one) we need to lookup the key
* again in the key dictionary to obtain the value object. */
if (server.maxmemory_policy != MAXMEMORY_VOLATILE_TTL) {
if (sampledict != keydict) de = dictFind(keydict, key);
o = dictGetVal(de);
}
/* Calculate the idle time according to the policy. This is called
* idle just because the code initially handled LRU, but is in fact
* just a score where an higher score means better candidate. */
// 空闲时间的计算方式 LRU 、 LFU 、最快过期的可以 三种过期策略下 都是不同的
if (server.maxmemory_policy & MAXMEMORY_FLAG_LRU) {
idle = estimateObjectIdleTime(o);
} else if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
/* When we use an LRU policy, we sort the keys by idle time
* so that we expire keys starting from greater idle time.
* However when the policy is an LFU one, we have a frequency
* estimation, and we want to evict keys with lower frequency
* first. So inside the pool we put objects using the inverted
* frequency subtracting the actual frequency to the maximum
* frequency of 255. */
idle = 255-LFUDecrAndReturn(o);
} else if (server.maxmemory_policy == MAXMEMORY_VOLATILE_TTL) {
/* In this case the sooner the expire the better. */
idle = ULLONG_MAX - (long)dictGetVal(de);
} else {
serverPanic("Unknown eviction policy in evictionPoolPopulate()");
}
/* Insert the element inside the pool.
* First, find the first empty bucket or the first populated
* bucket that has an idle time smaller than our idle time. */
k = 0;
// 在这里判断 池中某一个key的空闲时间是否小于 当前key的空闲时间
while (k < EVPOOL_SIZE &&
pool[k].key &&
pool[k].idle < idle) k++;
if (k == 0 && pool[EVPOOL_SIZE-1].key != NULL) {
/* Can't insert if the element is < the worst element we have
* and there are no empty buckets. */
continue;
} else if (k < EVPOOL_SIZE && pool[k].key == NULL) {
/* Inserting into empty position. No setup needed before insert. */
} else {
/* Inserting in the middle. Now k points to the first element
* greater than the element to insert. */
if (pool[EVPOOL_SIZE-1].key == NULL) {
/* Free space on the right? Insert at k shifting
* all the elements from k to end to the right. */
/* Save SDS before overwriting. */
sds cached = pool[EVPOOL_SIZE-1].cached;
memmove(pool+k+1,pool+k,
sizeof(pool[0])*(EVPOOL_SIZE-k-1));
pool[k].cached = cached;
} else {
/* No free space on right? Insert at k-1 */
k--;
/* Shift all elements on the left of k (included) to the
* left, so we discard the element with smaller idle time. */
sds cached = pool[0].cached; /* Save SDS before overwriting. */
if (pool[0].key != pool[0].cached) sdsfree(pool[0].key);
memmove(pool,pool+1,sizeof(pool[0])*k);
pool[k].cached = cached;
}
}
/* Try to reuse the cached SDS string allocated in the pool entry,
* because allocating and deallocating this object is costly
* (according to the profiler, not my fantasy. Remember:
* premature optimizbla bla bla bla. */
int klen = sdslen(key);
if (klen > EVPOOL_CACHED_SDS_SIZE) {
pool[k].key = sdsdup(key);
} else {
memcpy(pool[k].cached,key,klen+1);
sdssetlen(pool[k].cached,klen);
pool[k].key = pool[k].cached;
}
pool[k].idle = idle;
pool[k].dbid = dbid;
}
}
Redis的LRU缓存淘汰算法实现 - 腾讯云开发者社区-腾讯云 (tencent.com)
Redis中的LFU算法 - 再见紫罗兰 - 博客园 (cnblogs.com)
Redis精通系列——LFU算法详述(Least Frequently Used - 最不经常使用)_李子捌的博客-CSDN博客_lfu算法
Redis的缓存淘汰策略LRU与LFU - 简书 (jianshu.com)
Redis的LRU算法 - 演变历程详解 (cnblogs.com)