[TOC]
前言
Redis目前基本的数据类型有String、List、Set、ZSet、Hash五种,首先Redis是C语言开发的,所以底层就是用C语言封装数据结构或者C语言本身提供的数据结构来存储。
redis内部的主要数据结构主要有简单字符串(SDS)、双端链表、字典、压缩列表、跳跃表、整数集合。
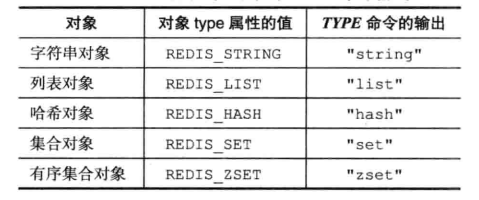
Redis内部并没有直接使用这些数据结构来实现键值对数据库,而是基于这些数据结构创建了一个对象系统-redisObject,这个对象系统包含了我们所熟知的五种基本类型数据,也就是字符串对象、列表对象、哈希对象、集合对象和有序集合对象这五种类型的对象。redisObject 是 Redis 类型系统的核心, 数据库中的每个键、值, 以及 Redis 本身处理的参数, 都表示为这种数据类型。
而它们每一种对象都使用到了至少一种前面所介绍的数据结构。下面介绍一下redis内部的主要几个数据结构简单字符串(SDS)、双端链表、压缩列表、跳跃表的定义。然后再介绍一下redis基本的五种数据类型,也就是五种类型的对象用到了上面的哪些数据结构。
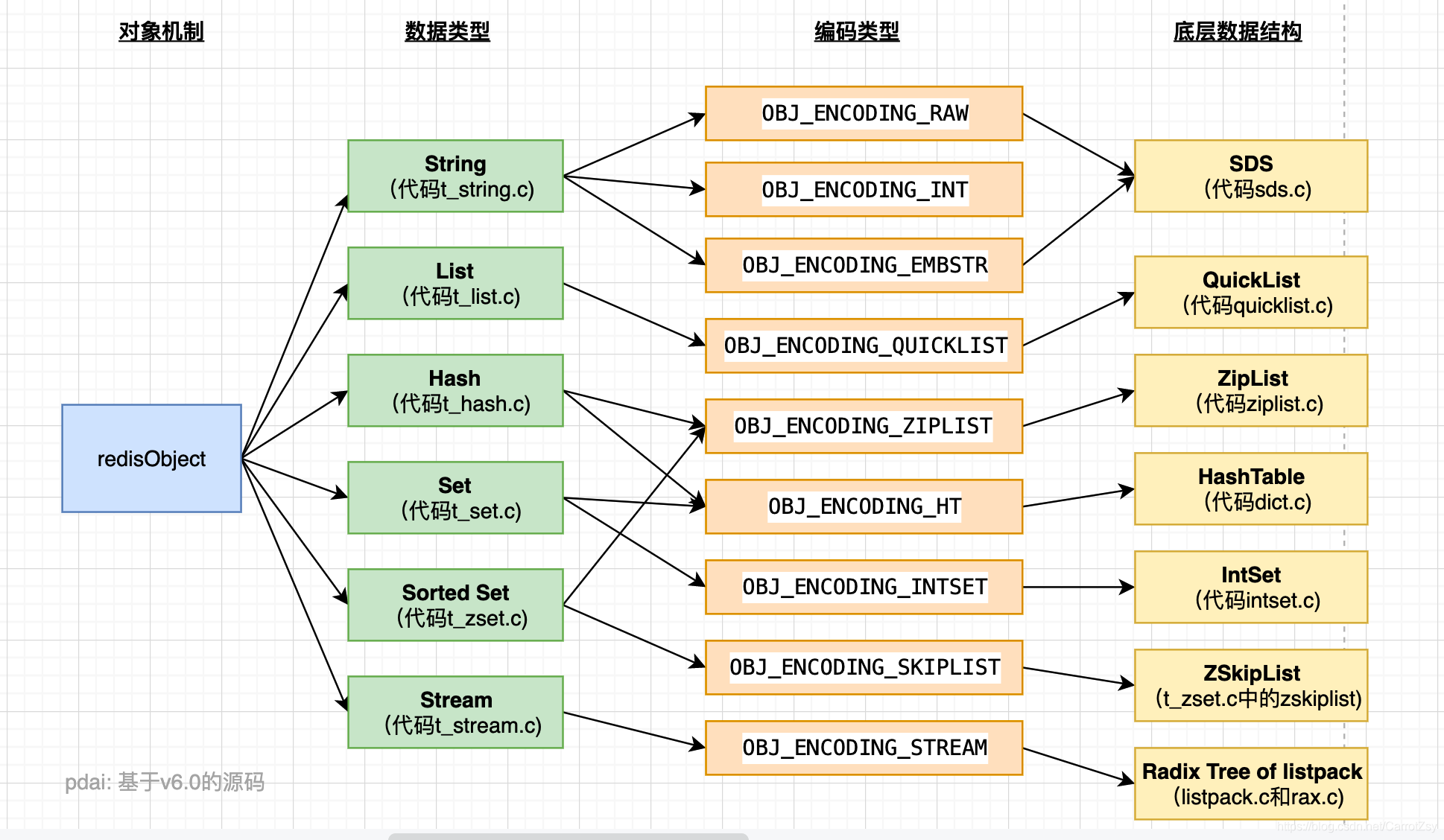
1. redis的底层数据结构
1.1 SDS(Simple Dynamic String)简单字符串
1、redis定义:
//定义了一个char 指针
typedef char *sds;
/* Note: sdshdr5 is never used, we just access the flags byte directly.
* sdshdr5 已经不用了, 在处理时会自动转为 sdshdr8
* However is here to document the layout of type 5 SDS strings. */
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 前 3 位保存类型,后 5 位保存字符串长度 */
char buf[];
};
//lsb 代表有效位的意思,
//__attribute__ ((__packed__)) 代表structure 采用手动对齐的方式。
struct __attribute__ ((__packed__)) sdshdr8 {
//buf 已经使用的长度
uint8_t len; /* used */
//buf 分配的长度,等于buf[]的总长度-1,因为buf有包括一个/0的结束符
uint8_t alloc; /* excluding the header and null terminator */
//只有3位有效位,因为类型的表示就是0到4,所有这个8位的flags 有5位没有被用到
unsigned char flags; /* 3 lsb of type, 5 unused bits */
//实际的字符串存在这里
char buf[];
};
// 还定义了其他长度的类型, 与上面的变化只有len和alloc, 就是长度不同而已
struct __attribute__ ((__packed__)) sdshdr16 {
};
struct __attribute__ ((__packed__)) sdshdr32 {
};
struct __attribute__ ((__packed__)) sdshdr64 {
};
这么多类型, 是为了针对不同的数据大小, 因为统一用int的话, 就占太多空间了(int 是 4字节)
flags字段用来表示 是sdshdr8类型还是其他类型, 因为总共定义了5种类型, 所以需要8bit , ( 2^2 < 5 < 2^3 )
2、使用范围: 在redis里面,C本身的字符串只会作为字符串字面量(String literal)只用在一些不必对字符串值修改的地方,比如打印日志。 而redis需要使用字符串存储并且会修改的地方,都使用了SDS来存储。例如Key/vaule值。
3、优点: 使用SDS来存储字符串的优点:
SDS的len属性直接记录了长度,获取字符串长度的复杂度为O(1)。
C字符串本身不记录长度容易产生缓存区溢出,而SDS杜绝了缓冲区的溢出。
C字符串本身不记录长度,每次修改都要重新分配内存,SDS减少了重新分配内存次数。
因为有alloc字段, 可以预先分配内存
优化了字符串缩短操作。并且可以保存任意格式的二进制数据,而C字符串必须含有编码。
c语言中, 字符串是用
表示文本结尾的, 而二进制压缩后是会出现的 , SDS是利用len字段来表示真实的数据有多长, 按长度取值
读书笔记:Redis设计之动态字符串SDS - Jefferywang的烂笔头 (wangjunfeng.com)
c++基础之uint8_t_时光机゚的博客-CSDN博客_uint8_t
Redis 源码解析 3:字符串 SDS - 小新是也 - 博客园 (cnblogs.com)
1.2 链表 (list)
1、链表: listNode结构来保存,多个listNode可以形成双向链表,redis定义了list表示头节点来持有链表,下图分别是节点listNode和链表list的定义。
2、redis定义:
- 节点listNode

- 链表list

3、使用范围: 链表在redis中用作了列表键、发布与订阅、慢查询、监视器等
1.3 跳跃表(skiplist)
1、跳跃表: 是一种有序的数据结构,通过在每个节点上维持多个指向其他节点的指针,从而达到快速访问的目的,可以理解为改进版的双端链表,改进的手段是通过空间换取了时间。
在 Redis 中跳表是有序集合(zset)的底层实现之一。
功能一:zset支持快速插入和删除
对应的解决思路:针对快速插入和删除,有没有想到什么?首选肯定是链表,所以,底层基础得有一个value和score组成的node连接起来的链表。
功能二:zset有序且支持范围查询
对应的解决思路:有序这个条件,我们可以先让链表按照顺序排列,但查找来说,链表的查询时间复杂度为O(n),并不高效,还要满足范围查找,如何解决这个问题?那么这时候就想到,能不能给链表做一个索引,提高它的查找效率的同时,让它也能支持范围查找,构建索引的话,是为了提高效率,如果只构建一层索引,数据量小的时候无所谓,但数据量大的时候呢?好像无法起到根本上提升效率的作用,所以应该给链表添加多级索引,简单示意图如下所示(引用自极客时间王争):
跳表结构:
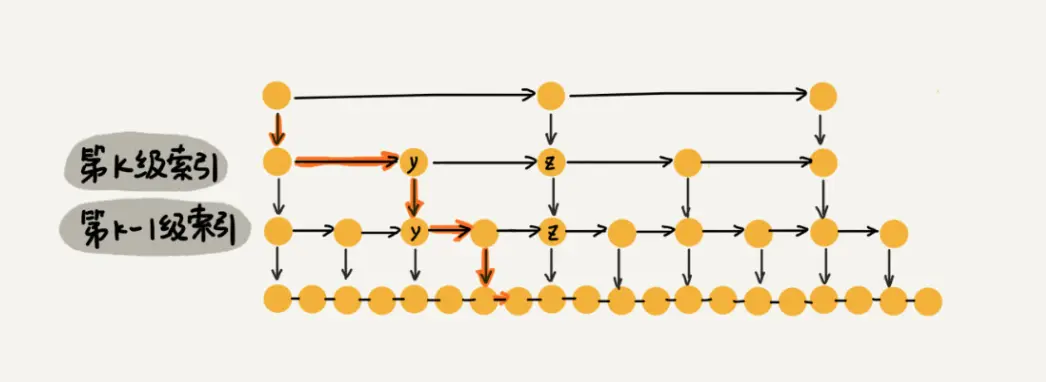
数据结构之Redis-跳表 - 简书 (jianshu.com)
Redis 学习笔记(篇三):跳表 - 风中抚雪 - 博客园 (cnblogs.com)
2、复杂度: 跳跃表支持平均O(logN)、最坏O(N)的查找复杂度,大部分条件下,跳跃表的效率可以和平衡树媲美,并且实现比平衡树简单。
- 跳跃表节点zskiplistNode

- 跳跃表zskiplist

3、跳跃表结构图:
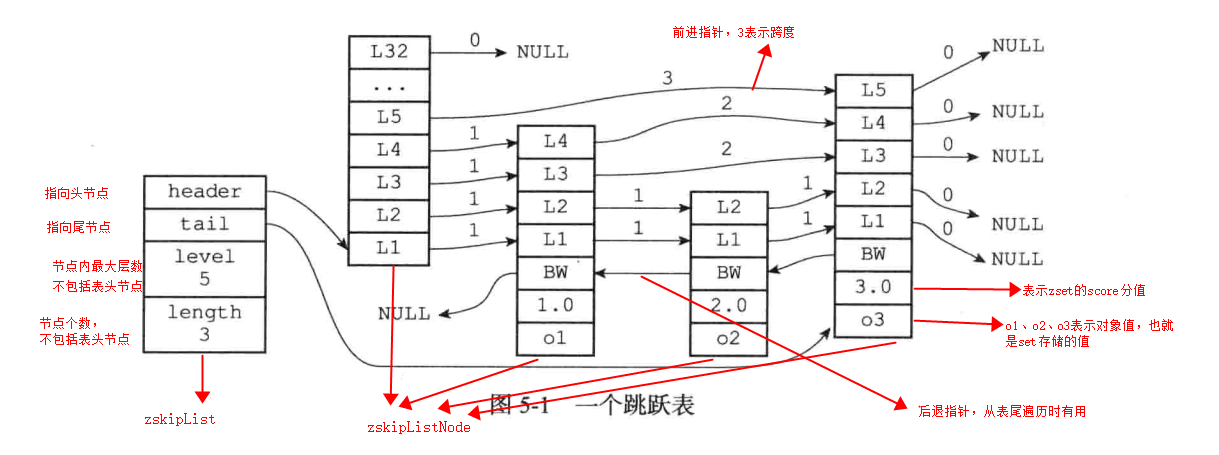
仔细观察上图跳跃表的结构后,发现如果节点的层数越高,那么这个节点访问其他节点的速度就越快。换言之,level越高,代表了这个跳跃表的查找效率可能会比较高。当然并不是绝对的,因为redis每次创建跳跃表节点时,程序是根据幂次定律(越大的数出现概率越小), 生成层数高度。同时,节点的顺序是根据每个节点的分值排序的,如果分值相同,那么根据对象的大小排序。
1.4 压缩列表(ziplist)
1、压缩列表: 是redis为了节省内存而开发的,是由一系列特殊编码的连续内存块组成的顺序型数据结构,一个压缩列表的可以包含多个节点,每个节点可以保存一个字节数组或者一个整数值。
2、压缩列表结构图:
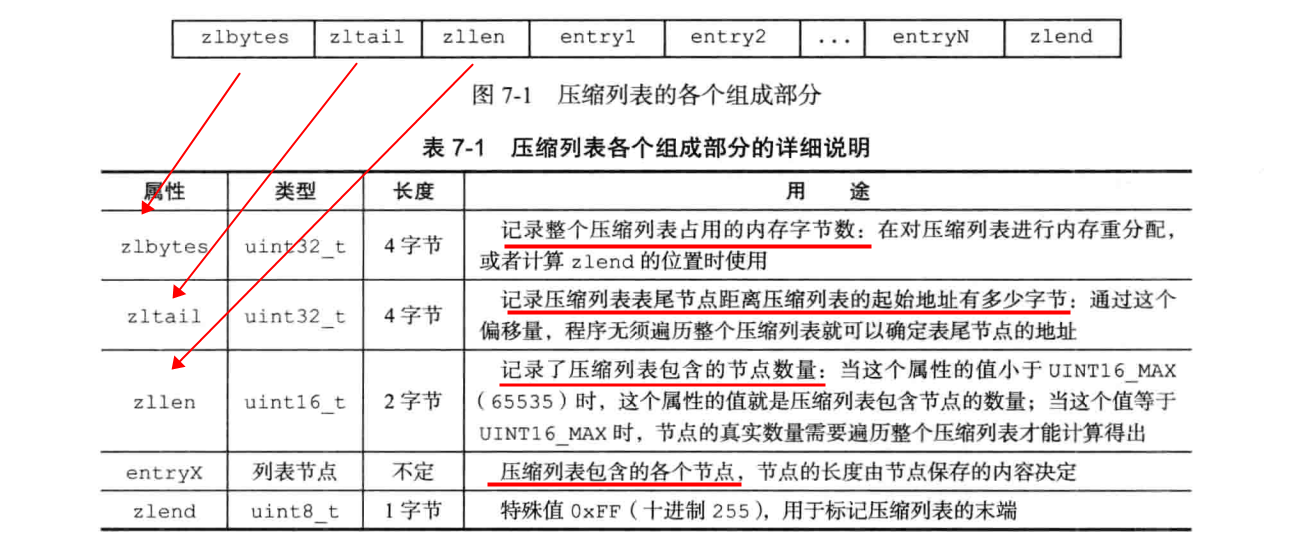
3、压缩列表特点:
- 是一种为节省内存开发的顺序性数据结构
- 可以包含多个节点,每个节点保存一个字节数组或者整数值
- 添加新节点到压缩列表,或者从压缩列表删除节点,可能会引发连锁更新操作,但是机率不高
1.5 字典(dict)
dict(字典) 是 Redis 中哈希键和有序集合键的底层实现之一。
可以看到图中,当我给一个 哈希结构中放了两个短的值,此时 哈希的编码方式是 ziplist, 而当我插入一个比较长的值,哈希的编码方式成为了 hashtable.

typedef struct dict{
// 类型特定函数
dictType *type;
// 私有数据
void *private;
// 哈希表
dictht ht[2];
// rehash 索引,当当前的字典不在 rehash 时,值为-1
int trehashidx;
}
type 和 private
这两个属性是为了实现字典多态而设置的,当字典中存放着不同类型的值,对应的一些复制,比较函数也不一样,这两个属性配合起来可以实现多态的方法调用。
ht[2] 这是一个长度为 2 的 dictht结构的数组,dictht就是哈希表。
trehashidx 这是一个辅助变量,用于记录 rehash 过程的进度,以及是否正在进行 rehash 等信息。
看完字段介绍,我们发现,字典这个数据结构,本质上是对 hashtable的一个简单封装,因此字典的实现细节主要就来到了 哈希表上。
哈希表
哈希表的定义如下:
typedef struct dictht{
// 哈希表的数组
dictEntry **table;
// 哈希表的大小
unsigned long size;
// 哈希表的大小的掩码,用于计算索引值,总是等于 size-1
unsigned long sizemasky;
// 哈希表中已有的节点数量
unsigned long used;
}
其中哈希表中的节点的定义如下:
typedef struct dictEntry{
// 键
void *key;
// 值
union {
void *val;
uint64_tu64;
int64_ts64;
}v;
// 指向下一个节点的指针
struct dictEntry *next;
} dictEntry;
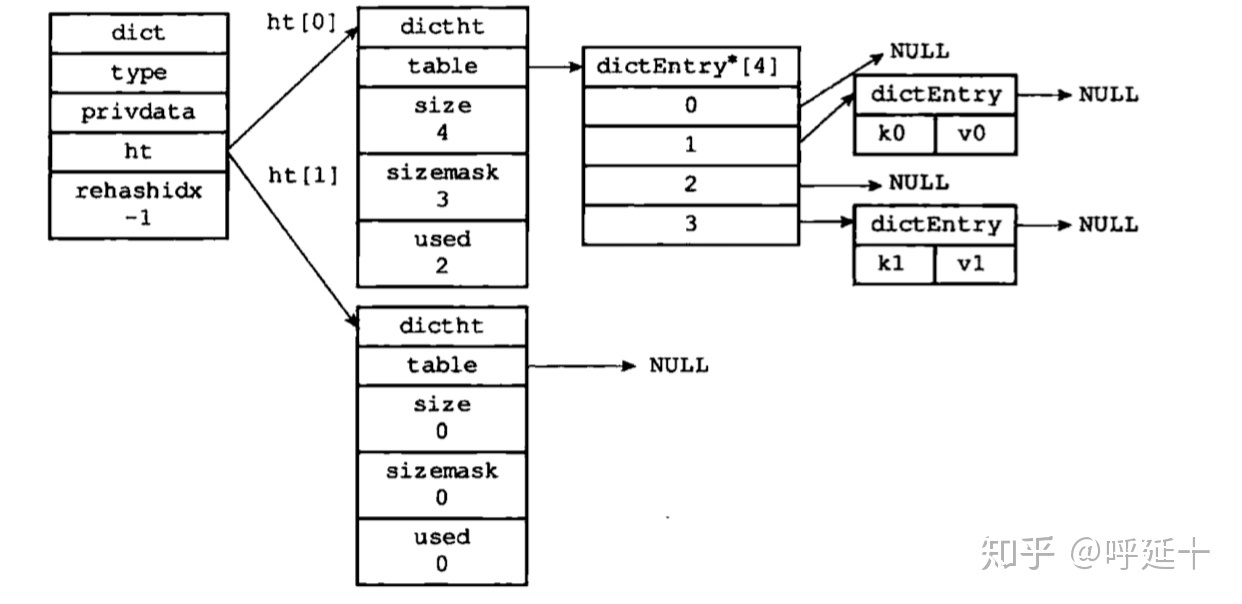
上图是一个没有处在 rehash 状态下的字典。可以看到,字典持有两张哈希表,其中一个的值为 null, 另外一个哈希表的 size=4, 其中两个位置上已经存放了具体的键值对,而且没有发生 hash 冲突。
哈希冲突
Redis 的哈希表处理 Hash 冲突的方式和 Java 中的 HashMap 一样,选择了分桶的方式,也就是常说的链地址法。Hash 表有两维,第一维度是个数组,第二维度是个链表,当发生了 Hash 冲突的时候,将冲突的节点使用链表连接起来,放在同一个桶内。
由于第二维度是链表,我们都知道链表的查找效率相比于数组的查找效率是比较差的。那么如果 hash 冲突比较严重,导致单个链表过长,那么此时 hash 表的查询效率就会急速下降。
因为有冲突所以需要扩容
扩容与缩容
当哈希表过于拥挤,查找效率就会下降,当 hash 表过于稀疏,对内存就有点太浪费了,此时就需要进行相应的扩容与缩容操作。
想要进行扩容缩容,那么就需要描述当前 hasd 表的一个填充程度,总不能靠感觉。这就有了 负载因子 这个概念。
负载因子是用来描述哈希表当前被填充的程度。计算公式是:负载因子=哈希表以保存节点数量 / 哈希表的大小.
在 Redis 的实现里,扩容缩容有三条规则:
当 Redis 没有进行 BGSAVE 相关操作,且 负载因子>1的时候进行扩容。
负载因子>5的时候,强行进行扩容。
当负载因子<0.1的时候,进行缩容。
根据程序当前是否在进行 BGSAVE 相关操作,扩容需要的负载因子条件不相同。
这是因为在进行 BGSAVE 操作时,存在子进程,操作系统会使用 写时复制 (Copy On Write) 来优化子进程的效率。Redis 尽量避免在存在子进程的时候进行扩容,尽量的节省内存。
熟悉 hash 表的读者们应该知道,扩容期间涉及到到 rehash 的问题。
因为需要将当前的所有节点挪到一个大小不一致的哈希表中,且需要尽量保持均匀,因此需要将当前哈希表中的所有节点,重新进行一次 hash. 也就是 rehash.
渐进式 hash
原理
在 Java 的 HashMap 中,实现方式是 新建一个哈希表,一次性的将当前所有节点 rehash 完成,之后释放掉原有的 hash 表,而持有新的表。
而 Redis 不是,Redis 使用了一种名为渐进式 hash 的方式来满足自己的性能需求。对于单线程的 Redis 来说,表示很难接受这样的延时,因此 Redis 选择使用 一点一点搬的策略。
Redis 实现了渐进式 hash. 过程如下:
- 假如当前数据在 ht[0] 中,那么首先为 ht[1] 分配足够的空间。
- 在字典中维护一个变量,rehashindex = 0. 用来指示当前 rehash 的进度。
- 在 rehash 期间,每次对 字典进行 增删改查操作,在完成实际操作之后,都会进行 一次 rehash 操作,将 ht[0] 在rehashindex 位置上的值 rehash 到 ht[1] 上。将 rehashindex 递增一位。
- 随着不断的执行,原来的 ht[0] 上的数值总会全部 rehash 完成,此时结束 rehash 过程。 将 rehashindex 置为-1.
在上面的过程中有两个问题没有提到:
假如这个服务器很空余呢?中间几小时都没有请求进来,那么同时保持两个 table, 岂不是很浪费内存? 解决办法是:在 redis 的定时函数里,也加入帮助 rehash 的操作,这样子如果服务器空闲,就会比较快的完成 rehash.
迁移时不是一个一个的移动, 而是按hash桶的维度, 一次一百个的移动
在保持两个 table 期间,该哈希表怎么对外提供服务呢? 解决办法:对于添加操作,直接添加到 ht[1] 上,因此这样才能保证 ht[0] 的数量只会减少不会增加,才能保证 rehash 过程可以完结。而删除,修改,查询等操作会在 ht[0] 上进行,如果得不到结果,会去 ht[1] 再执行一遍。
与此同时,渐进式 hash 也带来了一个问题,那就是 在 rehash 的时间内,需要保存两个 hash 表,对内存的占用稍大,而且如果在 redis 服务器本来内存满了的时候,突然进行 rehash 会造成大量的 key 被抛弃。
小应用
假设有两张表,一张工作量表,一张积分表,积分=工作量*系数。 系数是有可能改变的,当系数发生变化之后,需要重新计算所有过往工作量的对应新系数的积分情况。 而工作量表的数据量比较大,如果在系数发生变化的一瞬间开始重新计算,可以会导致系统卡死,或者系统负载上升,影响到在线服务。 怎么解决这个问题?
我们只需要额外记录一个标志着正在进行重新计算过程中的变量即可。之后的思路就完全和 Redis 一致了。
- 首先我们可以在某个用户请求自己的积分的时候,再帮他计算新的积分。来分散系统压力。
- 如果系统压力并不大,可以在系统定时任务里重算一小部分(一个 batch), 具体多少可以由数据量决定。
2. Redis五种基本数据类型
上面提到过,redis并没有使用上面的数据结构直接用来实现键值对数据库,也就是常说的五种基本数据类型,而是创建了一个对象系统,这个系统包含了字符串对象,列表对象、哈希对象、集合对象、和有序集合对象这五种基本数据类型。这样做有一个好处是,我们可以针对不同的场景,对相同的数据类型对象使用不同的数据结构,来优化提高效率
也就是说每种基本类型都是使用好几种对象来实现的
redisObject对象
1、对象: redis的键值对都是一个redisObject结构,该结构中有三个属性,type类型属性、encoding编码属性、ptr指向底层数据结构属性。
- redisObject对象定义

- 数据库的key值都是一个string字符串对象
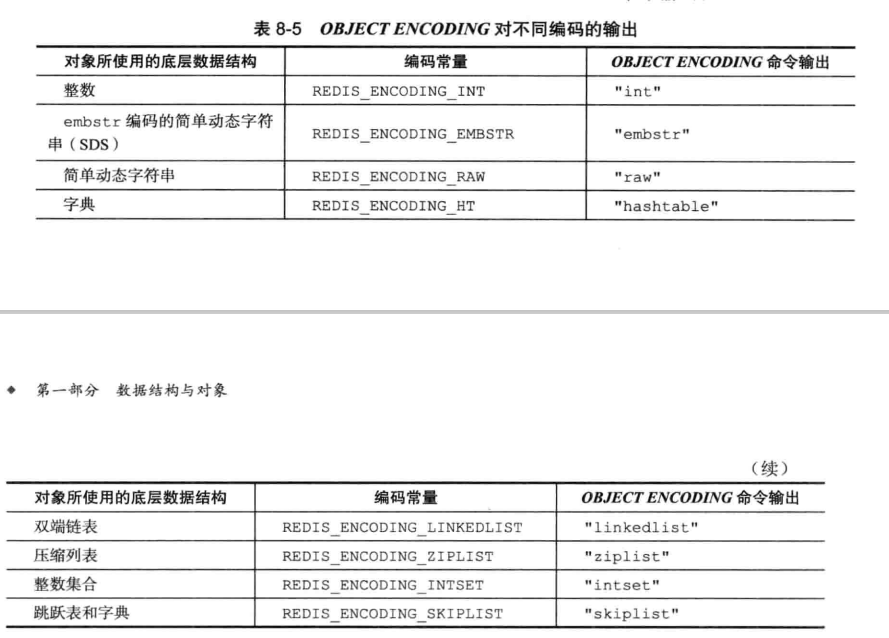
2、编码常量:
2.1 String类型
字符串对象的编码是int、raw、embstr。参考上面的编码常量表,也就是说字符串类型的数据底层的数据结构使用的是整数、SDS、embstr编码的SDS。
1、编码转换
即上述几种编码会在何时转换,也就是redis底层决定用什么存储字符串数据?。
当int类型的编码通过操作存储的是字符串值,那么字符串对象的编码将从int变为raw。
2.2 List类型
列表对象的编码可以是zipList压缩列表和linkedlist双端链表。
1、编码转换
即上述两种编码会在何时转换,也就是redis底层什么时候会用压缩列表存储列表数据?什么时候会使用双端链表存储列表数据。 当列表同时满足以下两个条件时,列表对象会使用zipList编码,也就是压缩列表
- 列表对象保存的所有字符串元素的长度都小于64字节
- 列表保存的元素少于512个,
2、配置
上述两个条件是支持配置的,也就是说我们可以redis直接读取我们的配置,来决定列表list类型底层使用什么样的数据结构来存储数据
- list-max-ziplist-value
- list-max-ziplist-entries
2.3 Set类型
集合对象使用的是intset整数集合(intset底层使用的是整数集合数据结构)或者hashtable哈希表(hashtable底层使用的是字典数据结构)
1、编码转换
当集合对象同时满足下面两个条件,会使用intset编码
- 集合对象保存的所有对象都是整数值
- 集合对象保存的元素数量小于512个;
2、配置
上述第二个条件是支持配置的。
- set-max-intset-entries
2.4 ZSet类型
有序集合的编码使用的是ziplist压缩列表和skiplist跳跃表。
**注意:**上面介绍skiplist的时候我们可以从结构图中明显看到存储集合元素的时候,score在每个节点中式如何存储的。那么如果ZSet使用的式ziplist压缩列表,redis怎么存储score和value值呢?其实很简单,每个集合的元素都使用两个节点来存储,第一个节点保存的是成员(member),第二个元素保存的是元素的分值(score)
1、编码转换
当有序集合对象可以同时满足以下两个条件时,使用ziplist编码
- 有序集合的所有元素长度都小于64字节
- 有序集合的元素数量小于128个;
2、配置
上述两个条件是支持配置的。
- zset-max-ziplist-value
- zset-max-ziplist-entries
2.5 Hash类型
哈希对象使用的是ziplist压缩列表或hashtable哈希表。(hashtable底层使用的是字典数据结构,我们并没有在本文做详细介绍,有需要可以自己了解)
1、编码转换
当哈希对象同时满足下面两个条件,使用ziplist压缩列表
- 哈希对象保存的所有键值对的键和值的字符串长度都小于64字节
- 哈希对象保存的键值对的数量小于512个;
2、配置
上述两个条件是支持配置的。
- hash-max-ziplist-value
- hash-max-ziplist-entries