1. 提示词框架
1.1 基本要素
当和大模型在交流时,可以将它想象是一个经过“社会化训练的”人,交流方式应当和人与人之间传递信息的方式一样。你的需求需要清晰明确,不能有歧义。你的提问方式(Prompt)越清晰明确,大模型越能抓住问题的关键点,回复就越符合你的预期。为了系统性地构建高效的上下文,我们可以遵循一个包含多个基本要素的提示词框架:任务目标、上下文、角色、受众、样例、输出格式。这些要素共同构成了一个完整的上下文“蓝图”,能帮助你构建一个完整、有效的提示词。
| 要素 | 含义 |
|---|---|
| 任务目标(Object) | 明确要求大模型完成什么任务,让大模型专注具体目标 |
| 上下文(Context) | 任务的背景信息,比如操作流程、任务场景等,明确大模型理解讨论的范围 |
| 角色(Role) | 大模型扮演的角色,或者强调大模型应该使用的语气、写作风格等,明确大模型回应的预期情感 |
| 受众(Audience) | 明确大模型针对的特定受众,约束大模型的应答风格 |
| 样例(Sample) | 让大模型参考的具体案例,大模型会从中抽象出实现方案、需要注意的具体格式等信息 |
| 输出格式(Output Format) | 明确指定输出的格式、输出类型、枚举值的范围。通常也会明确指出不需要输出的内容和不期望的信息,可以结合样例来进一步明确输出的格式和输出方法 |
当然,除了上面讲的提示词框架,许多问题分析的思维范式都可以用来帮助你描述清晰具体的需求。例如,SWOT分析法、5W2H分析法等。另外,你也可以考虑使用阿里云百炼提供的提示词自动优化工具 ,来帮助你完善提示词。
1.2 提示词模板
在开发大模型应用时,直接让用户根据框架书写提示词并非最佳选择。你可以参考各种提示词框架中的要素,构建一个提示词模板。提示词模板可以预设部分信息,如大模型的角色、注意事项等,以此来约束大模型的行为。开发者只需在模板中配置输入参数,便能创建标准化的大模型的应用。
使用 LlamaIndex 中创建的 RAG应用中,有个默认的提示词模板,如下所示:
- 默认的模板可以使用代码查看,你可以参考LlamaIndex官网的代码。 LlamaIndex原始prompt模板为:
Context information is below.
---------------------
{context_str}
---------------------
Given the context information and not prior knowledge, answer the query.
Query: {query_str}
Answer:
其中,context_str和query_str都表示变量。在进行向量检索和提问过程中,context_str将替换为从向量库中检索到的上下文信息,query_str则替换为用户的问题。
由于原模板是通用模板,不适合用来约束答疑机器人的行为。你可以通过下列示例代码重新调整提示词模板,其中prompt_template_string表示新的提示词模板,你可以根据自己的场景自行修改。
# 构建提示词模板
prompt_template_string = (
"你是公司的客服小蜜,你需要简明扼要的回答用户的问题"
"【注意事项】:\n"
"1. 依据上下文信息来回答用户问题。\n"
"2. 你只需要回答用户的问题,不要输出其他信息\n"
"以下是参考信息。"
"---------------------\n"
"{context_str}\n"
"---------------------\n"
"问题:{query_str}\n。"
"回答:"
)
# 更新提示词模板
rag.update_prompt_template(query_engine,prompt_template_string)
2. 构建有效提示词的技巧
在3.1中列举了一些提示词设计中的要素,接下来将从提示词要素出发,结合具体场景展开讲解提示词技巧。
2.1 清晰表达需求,并使用分隔符
明确的表达需求可以确保大模型生成的内容与任务高度相关。需求包括任务目标、背景及上下文信息,还可以使用分隔符将各种提示词要素隔开。
分隔符可以使大模型抓住具体的目标,避免模糊的理解,也减少对不必要信息的处理。分隔符一般可以选择 “【】”、“« »”、“###”来标识关键要素,用“===”、“—”来分隔段落,或者使用xml标签如<tag> </tag>来对特定段落进行标识。当然,分隔符不止上述提到的几种,只需要起到明确阻隔的作用即可。需要注意的是,如果提示词中已大量使用某种符号(如【】),则应避免用该符号作为分隔符,以防混淆。
在下面的示例中,以答疑机器人的身份帮你完成文档润色。
question = """
把下列【】括起来的文本进行扩写和润色,让文案生动且富有创造力,并且受到公司新员工的喜欢。
【新员工训练营活动】
"""
ask_llm(question,query_engine)
由上述运行结果可以发现,提示词中明确了任务需求:对文本进行扩写和润色,任务主题为“新员工训练营活动”,受众为“公司员工”,并使用了“【】”分隔符分隔了文本。使用这样的提示词,让输出的文本不仅保持了原本的含义,还更加生动有趣。
2.2 限定角色和受众
角色指大模型在特定场景下应扮演的身份,如专家、顾问或助手。受众是使用模型输出的目标用户群体,如普通消费者或学生。这有助于开发者定制内容的风格和深度。以下示例将展示不同的系统角色对输出文本风格和内容的影响,用户的问题为:qwen-vl是什么?
- 以下仅演示提示词模板和输出的内容,你可以将提示词模板传入到
prompt_template_string中,将用户问题传入到question中,再调用ask_llm函数。
| 角色 | 大模型算法工程师 | 小学老师 |
|---|---|---|
| 提示模板 | “你是资深的大模型算法工程师,请根据用户的问题进行解答\n” "———————\n" "{context_str}\n" "———————\n" “问题:{query_str}\n。" “回答:” | “你是一名小学老师,请根据用户的问题进行解答\n” ”———————\n" "{context_str}\n" "———————\n" “问题:{query_str}\n。" “回答:” |
| 用户问题 | Qwen-VL | Qwen-VL |
| 输出回答 | Qwen-VL是阿里巴巴云推出的一种多模态预训练模型,它结合了文本和图像处理能力,能够理解和生成与图像相关的文本描述。简单来说,Qwen-VL可以看作是一个能够“看图说话”的人工智能助手,它不仅能够理解图片的内容,还能根据图片内容生成相应的文字描述或回答相关问题。这种技术在多个领域都有广泛的应用前景,比如自动图像标注、视觉问答系统、基于内容的图像搜索等。对于新媒体运营而言,Qwen-VL这样的工具可以帮助提高内容创作效率,增强用户体验,为用户提供更加丰富多元的信息展示方式。 | 小朋友们,我们今天来认识一个新朋友,它的名字叫做Qwen-VL! Qwen-VL就像是一个非常聪明的机器人,它拥有“眼睛”👀和“大脑”🧠。它能“看”图片、视频,还能理解它们的意思,就像我们一样! 比如,你给它看一张小猫玩毛线球的图片,它不仅能认出这是一只小猫🐱,还能告诉你它在玩毛线球🧶。 更厉害的是,你还可以问它:“小猫是什么颜色的?”,它就能告诉你小猫的颜色。 它还能理解视频里的内容,比如你给它看一段小朋友们踢足球⚽️的视频,它能告诉你谁在踢球,球踢到了哪里,甚至还能猜到接下来可能会发生什么! Qwen-VL就像一个正在学习的小朋友,它还在不断地学习和进步,将来它会变得更聪明,能做更多的事情,帮助我们更好地了解这个世界! |
2.3 规定输出格式
有时候,开发者在设计大模型应用时,需要采用结构化的数据作为下游系统的输入,才能完成整个应用的开发,但是一般大模型是输出连续的文本。不用担心,大模型有结构化输出的能力。你只需在提示词中指定输出的格式和要求,大模型有很大可能会输出结构化的内容。
在下面的示例中,以答疑机器人的身份帮助公司开发的文档进行文档质量审查,并将结果以json的格式输出:
question_task= """
【任务要求】
你将看到一句话或一段话。你需要审查这段话中有没有错别字。如果出现了错别字,你要指出错误,并给出解释。
“的” 和 “地” 混淆不算错别字,没有错误
---
【输出要求】
请你只输出json格式,不要输出代码段
其中,label只能取0或1,0代表有错误,1代表没有错误
reason是错误的原因
correct是修正后的文档内容
---
【用户输入】
以下是用户输入,请审阅:
"""
question_doc = "分隔符是特殊的符号,它们帮助大语言模形 (LLM) 识别提示中哪些部分应当被视为一个完整的意思单元。"
question = question_task + question_doc
ask_llm(question, query_engine)
由上述示例的结果可知,在提示词question_task中注明了输出格式为json,也规定了输出的内容,大模型成功的输出了格式化的内容。这种稳定的格式化输出,使得在现有的系统中接入大模型这个操作变得具有可行性。
在新闻网站、博客平台或企业内部的知识分享平台上,用户编辑或发布的文章可能会包含错别字、语法错误、甚至是敏感信息。但是传统的人工审核方式很容易出疏漏。这时候可以接入大模型来对内容做审查工作。如果文章被标记为存在严重语法错误或含有高风险敏感词汇,则将其修改的优先级设置为“高”。对于轻微问题的文章,则可以将其修改的优先级设置为“低”。这样会节省人力成本,提高系统的效率与准确性。
当然了,类似于上述场景的应用非常多,开发者可以分析系统中流程的瓶颈或者关注数据密集型的任务,探索更多的大模型应用场景。
2.4 提供少样本示例
如果希望大模型输出的内容不仅格式正确,而且风格和结构也保持一致,可以提供几个样例作为参考。这相当于给大模型提供了一本“参考书”。下面的代码示例中,先观察下没有样例时的大模型的输出吧!
question_task = """
【任务要求】
请你根据用户的主题,创作内容。
---
【输出要求】
最终输出需要以Markdown格式呈现,请注意,在你的回答中包含所有必要的Markdown元素,如标题、列表、链接、图片引用、加粗等,以便于阅读、后续编辑和保存。
---
【用户输入】
以下是用户的要求创作的主题:
"""
question_doc = "手工钥匙扣制作教程"
question = question_task + question_doc
ask_llm(question, query_engine)
上述示例大模型成功了输出了手工钥匙扣制作教程,但是内容不够简洁,如果只想大模型输出特定风格和结构的内容,如只输出主题、材料清单、步骤等内容,可以为大模型添加几个样例,让它去“模仿”!
question_task= """
【任务要求】
请根据用户的主题,结合下面【样例】给的例子,理解和使用一致的风格和结构继续创作内容,不要输出多余的内容。
---
【输出要求】
最终输出需要以Markdown格式呈现,请注意,在你的回答中包含所有必要的Markdown元素,如标题、列表、链接、图片引用、加粗等,以便于阅读、后续编辑和保存。
---
【样例】
### 示例1: 制作简易书签
# 简易书签制作教程
## 材料清单
- 彩色卡纸
- 剪刀
- 装饰贴纸
- 铅笔
## 步骤
1. 选择一张彩色卡纸。
2. 用铅笔在卡纸上画出一个长方形,尺寸约为2英寸 x 6英寸。
3. 沿着铅笔线剪下长方形。
4. 使用装饰贴纸对书签进行个性化装饰。
5. 完成!现在你有了一个独一无二的书签。
## 结束语
希望这个教程能帮助你制作出满意的书签!
---
【用户输入】
以下是用户的要求创作的主题:
"""
question_doc = "制作手工贺卡"
question = question_task + question_doc
ask_llm(question, query_engine)
由上述示例结果可知,大模型完全按照了样例输出了相同结构和风格的内容。在提示词中规定输出格式的同时,建议提供几个样例供大模型参考,这样可以使得大模型的输出更加稳定和一致。
2.5 给模型“思考”的时间
对于一些复杂的任务来说,使用上面提到的提示词也许还不能帮助大模型完成任务。但是你可以通过让大模型一步步“思考”,引导大模型输出任务的中间步骤,允许大模型在进行推理之前,得到更多的依据,从而提升在复杂任务的表现能力。思维链(COT)方法是让模型进行思考的一种方法。它通过让模型处理中间步骤,逐步将复杂问题分解为子问题,最终推导出正确答案。
假设有这样的场景,让大模型计算下面这道数学题,在此先提示一下,这道题的正确答案为10500元。先使用简单的提示词:
question = """
【背景信息】
某教育培训机构(以下简称“公司”)在2023年度发生了以下主要支出:
为了给不同城市的学校学生上课,公司的老师全年共出差了5次,每次出差时间为一周,具体费用如下:
- 交通费及住宿费:平均1600元/次
- 教学用具采购费用:公司在年初一次性购买了一批教学用具,总价为10000元,预计可以使用4年。
【问题描述】
请根据上述背景信息,完成以下任务:
计算全年因教师出差而产生的差旅总费用,包括摊销的教学用具。
【输出要求】
直接给出总差旅费用,不要其他信息"""
ask_llm(question, query_engine)
由上面的实验结果来看,大模型计算结果不正确。下面将使用COT方法,让大模型逐步进行思考。
question = """某教育培训机构(以下简称“公司”)在2023年度发生了以下主要支出:
为了给不同城市的学校学生上课,公司的老师全年共出差了5次,每次出差时间为一周,具体费用如下:
- 交通费及住宿费:平均1600元/次
- 教学用具采购费用:公司在年初一次性购买了一批教学用具,总价为10000元,预计可以使用4年。
### 问题描述
请根据上述背景信息,完成以下任务:
计算全年因教师出差而产生的差旅总费用,包括摊销的教学用具。
### 输出要求
请你一步步推导,计算总差旅费用"""
ask_llm(question, query_engine)
经过优化后的提示词,大模型能够准确计算出结果。因此在开发大模型应用时,可以在提示词中添加思维链的方法,可以确保一些推理任务能正确执行。
使大模型进行 “思考”的方法还有很多种,比如:思维树(ToT)、思维图(GOT) 等。但是就目前大模型的发展来说,仅靠引导大模型“思考”还是无法完成更复杂的工作。大模型也逐渐从COT的提示方法向多智能体(Agent)方向进行发展。
2.6 Meta Prompting: 让大模型成为你的提示词教练
一次性就写好一个完美的提示词,往往非常困难。更常见的工作流是:
- 写出第一版提示词。
- 运行它,并分析输出结果中有哪些不符合预期的地方。
- 总结问题,思考如何改进,然后修改提示词。
- 不断重复这个迭代过程,直到满意为止。
你可以回想一下,这是否也是你优化提示词的常规路径?这个过程虽然有效,但非常依赖经验,也颇为耗时。
这时,你可能会想到:既然大模型这么强大,这个分析、总结、改进的迭代过程,是否能让大模型自己来做呢? 让它扮演“提示词评审专家”的角色,帮助我们分析和优化提示词,无疑会更高效。
答案是肯定的。这种让你和模型一起“讨论”如何优化提示词本身的方法,就叫做 Meta Prompting。
为了进一步理解这个强大的技巧,你可以来亲手实践一下。
步骤 1:一个不甚理想的初始提示词
假设你的任务是优化答疑机器人的回答,让它在回答新员工关于“公司福利”的问题时,输出更友好、结构更清晰的内容。你可能会从一个简单的提示词开始:
# 在真实的 RAG 应用中,这段文本会由你的向量数据库检索而来。
# 这里用一个字符串来模拟它,方便你进行实验。
retrieved_text = """
关于公司的福利政策,我们提供全面的健康保险,覆盖员工及其直系家属。
年度体检是标配。此外,每年有15天的带薪年假,以及5天的带薪病假。
我们还提供每月500元的交通补贴和300元的餐饮补贴。
为了鼓励员工成长,公司设有每年高达8000元的教育培训基金,员工可以申请用于课程学习或购买专业书籍。
健身方面,公司与多家健身房有合作,员工可享受折扣价。
"""
# 这是一个非常基础的提示词,只是简单地将任务和信息拼接起来。
initial_prompt = f"""
根据以下信息,回答新员工关于公司福利的问题。
【参考信息】
{retrieved_text}
"""
# 看看这个“朴素”的提示词会产生什么样的效果。
response = llm.invoke(initial_prompt)
print("--- 初始回答 ---")
print(response)
这个回答虽然包含了所有信息,但你可能会觉得,对于一个刚入职的新员工来说,它显得有些平淡和杂乱。它只是简单地复述了文本,没有重点,也缺乏热情的欢迎语气。
显然,这个效果没有达到你的预期。现在,你无需自己苦思冥想如何修改,而是可以尝试一种更高效的方法:让大模型来帮你优化。
步骤 2:构建 Meta Prompt,让大模型提供优化建议
现在,你对这个平淡的回答不满意。你可以构建一个“Meta Prompt”,清晰地向模型描述你的目标(友好、结构化、重点突出),并将你那不甚理想的初始提示词和它产出的回答一并“喂”给大模型,请求它以“提示词工程专家”的身份,帮你改进。
# 你需要将你的不满和期望清晰地表达出来,这是让AI教练理解你意图的关键。
meta_prompt = f"""
我正在为公司的新员工答疑机器人优化一个提示词,目标是回答关于“公司福利”的问题。
这是我的第一个尝试:
---
{initial_prompt}
---
这是它生成的输出:
---
{response}
---
这个输出不够好。我希望机器人的回答更具吸引力,并且结构清晰,能让新员工快速抓住重点。具体要求如下:
1. **语气**:友好、热情,有欢迎新同事的感觉。
2. **结构**:使用清晰的要点(比如用表情符号开头的列表)来组织内容。
3. **内容**:将福利分为几个类别,如“健康与假期”、“补贴与激励”等。
请你扮演一位提示词工程专家,帮我重写这个提示词,以实现上述目标。
"""
# 现在,让AI教练开始工作,为你生成一个优化版的提示词。
optimization_suggestion = llm.invoke(meta_prompt)
print("--- 来自AI教练的优化建议 --")
print(optimization_suggestion)
观察AI教练给出的建议,你会发现,它给出的优化后提示词,很可能应用了你在前面章节学到的多种技巧,例如:
- 明确角色 (例如,“你是一位热情、友好的入职伙伴”)
- 清晰的任务描述 (例如,“根据提供的参考信息,生成一段关于公司福利的介绍”)
- 规定输出格式和风格 (例如,“使用热情的欢迎语”、“用表情符号开头的列表”)
这证明,让模型扮演专家来优化提示词是完全可行的。
步骤 3:使用优化后的提示词
现在,你可以直接将这位“AI教练”为你量身定做的提示词用于你的任务,看看效果如何。
# 这是一个假设的、由AI教练建议的优化版提示词
# 在实际应用中,你可以直接使用 `optimization_suggestion` 的输出
# 这里为了演示,我们手动构建一个符合建议的提示词
optimized_prompt = f"""
【角色】
你是一位热情、友好的入职伙伴(Onboarding Buddy),你的任务是欢迎新同事,并清晰地介绍公司的福利政策。
【任务】
根据提供的【参考信息】,生成一段关于公司福利的介绍。
【输出要求】
1. 开头使用热情洋溢的欢迎语。
2. 将福利信息分类整理,例如分为“健康与假期”、“补贴与激励”等。
3. 每个福利项目前使用一个相关的表情符号,使其更生动。
4. 结尾表达对新同事的美好祝愿。
【参考信息】
{retrieved_text}
"""
# 使用优化后的提示词再次调用模型
final_response = llm.invoke(optimized_prompt)
print("--- 使用优化版提示词的回答 ---")
print(final_response)
通过这个迭代过程,你将得到一个语气热情、结构清晰的回答,这无疑会给新员工留下更好的第一印象。
这个例子展示了 Meta Prompting 在提升用户体验方面的巨大价值。它不仅仅是提取信息,更是关于如何更好地呈现信息。当你遇到一个棘手的提示词难题时,不要忘记,你的模型本身就是最好的教练。通过清晰地描述你的目标和困难,你可以引导它为你构建出更强大、更精确、也更有“人情味”的提示词。
在刚才的初步方案中,我们是向“AI教练”描述了我们期望的定性目标(如“友好”、“结构更清晰”),然后由它直接为我们生成一个优化后的提示词。这个方法很便捷,但它有一个关键的局限性:AI教练对这些定性目标的理解可能不够精确,你描述的需求也可能不够具体,这导致优化结果的好坏存在不确定性。
为了解决这个问题,让优化过程变得更可控、更精确,我们需要从“定性指导”升级到“量化对齐”。与其给出一个模糊的目标,不如直接给出一个完美的 “参考答案” 作为精确的靶子。接下来的进阶方案将向你展示如何利用这个“参考答案”,让大模型通过自动化的差距分析和迭代,逐步地、精确地向着最优结果逼近。这才是更具工程化的改进思路。
多轮迭代:引入参考答案进行差距分析
在前面的例子中,你扮演了主导角色,接收“AI教练”的建议并手动应用它。但这个过程还可以进一步自动化和精确化。与其让评估者给出一个模糊的“好”或“不好”的判断,一个更高级的方法是引入一个 “参考答案”(Reference Answer)。
这个“参考答案”是你心目中最完美的理想答案,可以由人类专家撰写,也可以用一个非常详尽的提示词让最强大的模型生成。迭代优化的目标就变成了:不断修改提示词,使其生成的回答与这个“参考答案”之间的差距越来越小。
这个过程就像一个拥有精确制导系统的自我修正流程:
- 设定参考答案 (Set Reference Answer):首先,定义一个高质量的、理想的“参考答案”。
- 生成 (Generate):使用当前待优化的提示词,生成一个回答。
- 分析差距 (Analyze Gap):让一个“评估者”大模型(Critic)来比较“生成的回答”和“参考答案”,并输出一份详细的“差距分析报告”,指出两者在语气、结构、内容、格式等方面的具体差异。
- 优化 (Optimize):将“差距分析报告”连同原始提示词、生成的回答一起,交给一个“优化者”大模型(Optimizer)。它的任务是根据这份报告,重写提示词,以专门解决其中指出的问题,从而缩小差距。
- 重复 (Repeat):用优化后的新提示词替换旧的,然后回到第2步,直到“评估者”认为两者差距足够小,或达到最大迭代次数。
# 1. 设定参考答案
reference_answer = """
👋 欢迎加入我们的大家庭!很高兴能为你介绍我们超棒的福利政策:
**🏥 健康与假期,我们为你保驾护航:**
- **全面健康保险**:覆盖你和你的家人,安心工作无烦忧。
- **年度体检**:你的健康,我们时刻关心。
- **带薪年假**:每年足足15天,去探索诗和远方吧!
- **带薪病假**:5天时间,让你安心休养,快速恢复活力。
**💰 补贴与激励,为你加油打气:**
- **交通补贴**:每月500元,通勤路上更轻松。
- **餐饮补贴**:每月300元,午餐加个鸡腿!
- **教育培训基金**:每年高达8000元,投资自己,未来可期。
- **健身折扣**:与多家健身房合作,工作再忙也别忘了锻炼哦!
希望这些福利能让你感受到公司的关怀!期待与你一起创造更多价值!🎉
"""
# 2. 定义差距分析和优化函数
def analyze_gap(generated_response, reference):
gap_analysis_prompt = f"""
【角色】你是一位文本比较专家。
【任务】请详细比较【生成回答】与【参考答案】之间的差距。
【参考答案】
{reference}
---
【生成回答】
{generated_response}
---
【要求】
请从语气、结构、内容细节、格式(如表情符号使用)等方面,输出一份详细的差距分析报告。如果两者几乎没有差距,请直接回答“差距很小”。
"""
return llm.invoke(gap_analysis_prompt)
def optimize_prompt_with_gap_analysis(current_prompt, generated_response, gap_report):
optimization_prompt = f"""
【角色】你是一位顶级的提示词工程师。
【任务】根据提供的“差距分析报告”,优化“当前提示词”,使其能够生成更接近“参考答案”的输出。
---
【当前提示词】
{current_prompt}
---
【生成回答】
{generated_response}
---
【差距分析报告】
{gap_report}
---
【要求】
请只返回优化后的新提示词,不要包含任何其他解释。
"""
return llm.invoke(optimization_prompt)
# 3. 迭代优化循环
current_prompt = initial_prompt # 复用4.6节的initial_prompt
for i in range(3): # 最多迭代3次
print(f"--- 第 {i+1} 轮迭代 ---")
generated_response = llm.invoke(current_prompt.format(retrieved_text=retrieved_text))
print(f"生成的回答 (部分):\\n{generated_response[:100]}...")
gap_report = analyze_gap(generated_response, reference_answer)
print(f"差距分析报告:\\n{gap_report}")
if "差距很小" in gap_report:
print("\\n评估通过,优化完成!")
break
print("\\n评估未通过,根据差距分析报告优化提示词...")
current_prompt = optimize_prompt_with_gap_analysis(current_prompt, generated_response, gap_report)
else:
print("\\n达到最大迭代次数,停止优化。")
final_prompt_based_on_reference = current_prompt
这个自动化的迭代过程展示了 Meta Prompting 的真正效果。它将你从繁琐的手动调整中解放出来,让模型自己去探索和发现最佳的表达方式,也为更复杂的 AI 自我改进(Self-Improvment) 系统的设计提供了基础思路。
是不是就像我们让AI自动进化, 不需要人类干预, 实现了自我进化!
效果评测:量化你的优化成果
当你有多个版本的提示词(例如,初始版本 vs. 单次优化版 vs. 多轮迭代最终版),你如何客观地证明哪个更好呢?除了直观感受,更科学的方法是进行量化评估。
你可以再次利用大模型,让它扮演一个“评分员”(Grader)的角色,根据一系列标准对不同提示词生成的回答进行打分。
例如,你可以定义一个评分标准:
- 友好度 (Friendliness): 1-5分
- 结构清晰度 (Clarity): 1-5分
- 信息准确性 (Accuracy): 1-5分
然后,构建一个“Grader Prompt”,将评分标准和待评估的回答一起交给大模型,让它输出一个结构化的评分结果(如 JSON)。
import json
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
import pandas as pd
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 三个质量差异明显的典型回答样本
# 差:只是简单罗列信息,没有结构和感情
poor_response = "公司福利:健康保险,家属可用。15天年假,5天病假。交通补贴500,餐饮补贴300。培训基金8000。健身房有折扣。"
# 中:有基本结构和分类,但语气平淡
medium_response = """
公司福利:
1. 💦健康和假期:
- 健康保险(含家属)
- 年度体检
- 15天年假和5天病假
2. 💰补贴和激励:
- 每月500交通补贴和300餐饮补贴
- 8000元/年的教育培训基金
- 合作健身房折扣
"""
# 优:结构清晰、语气友好、视觉吸引力强(直接使用我们的参考答案)
good_response = reference_answer
# 设计更细化的评估维度
def grade_response_detailed(response_to_grade):
grader_prompt = f"""
【角色】你是一位经验丰富的内部沟通和员工体验评测官。
【任务】请根据以下四个维度,对提供的“公司福利介绍”文本进行1-5分的量化评分。
【评分维度】
1. **欢迎语气 (welcoming_tone)**: 1分表示语气冰冷生硬,5分表示非常热情、有感染力。
2. **内容结构化 (structuring)**: 1分表示信息混乱无序,5分表示分类清晰、逻辑性强。
3. **视觉吸引力 (visual_appeal)**: 1分表示枯燥乏味,5分表示善用表情符号、粗体等元素,非常吸引眼球。
4. **信息完整性 (completeness)**: 1分表示信息缺失严重,5分表示关键福利信息完整无缺。
【待评估文本】
{response_to_grade}
---
【输出要求】
请严格以JSON格式返回你的评分,不要包含任何解释。例如:
{{"welcoming_tone": 5, "structuring": 4, "visual_appeal": 5, "completeness": 5}}
"""
try:
raw_output = llm.invoke(grader_prompt)
# 提取JSON部分
json_str = raw_output[raw_output.find('{'):raw_output.rfind('}')+1]
return json.loads(json_str)
except (json.JSONDecodeError, IndexError):
# 容错处理,在无法解析时返回一个默认的低分
return {{"welcoming_tone": 1, "structuring": 1, "visual_appeal": 1, "completeness": 1}}
# 对三个典型样本进行评分
# 注意:这里的 key 将作为图表中的标签,我们使用新视觉方案中提供的名称
scores = {
"Original Answer": grade_response_detailed(poor_response),
"Single Iteration Optimize": grade_response_detailed(medium_response),
"Multi-turn Iteration Optimize": grade_response_detailed(good_response)
}
# 将 scores 转换为 DataFrame
df = pd.DataFrame(scores)
df = df.reset_index().rename(columns={'index': 'Dim'})
df_long = df.melt(id_vars='Dim', var_name='Version', value_name='Score')
# --- 单幅分组柱状图 ---
plt.figure(figsize=(10, 6))
ax = sns.barplot(
data=df_long,
x="Dim", # 每个维度一组
y="Score",
hue="Version", # 3 个版本并排
palette="viridis"
)
# 为每根柱子添加数值标签
for p in ax.patches:
height = p.get_height()
if height == 0: # 跳过高度为 0 的占位 patch
continue
ax.annotate(
f"{height}",
(p.get_x() + p.get_width() / 2., height),
ha='center', va='center',
xytext=(0, 5),
textcoords='offset points',
fontsize=11
)
# 轴和标题美化
ax.set_ylim(0, 6)
ax.set_ylabel('Score (1-5)', fontsize=12)
ax.set_xlabel('') # 隐藏 X 轴标题
ax.set_title('Evaluation', fontsize=20)
ax.tick_params(axis='x', labelsize=12)
plt.legend() # 显示图例
plt.tight_layout()
plt.show()
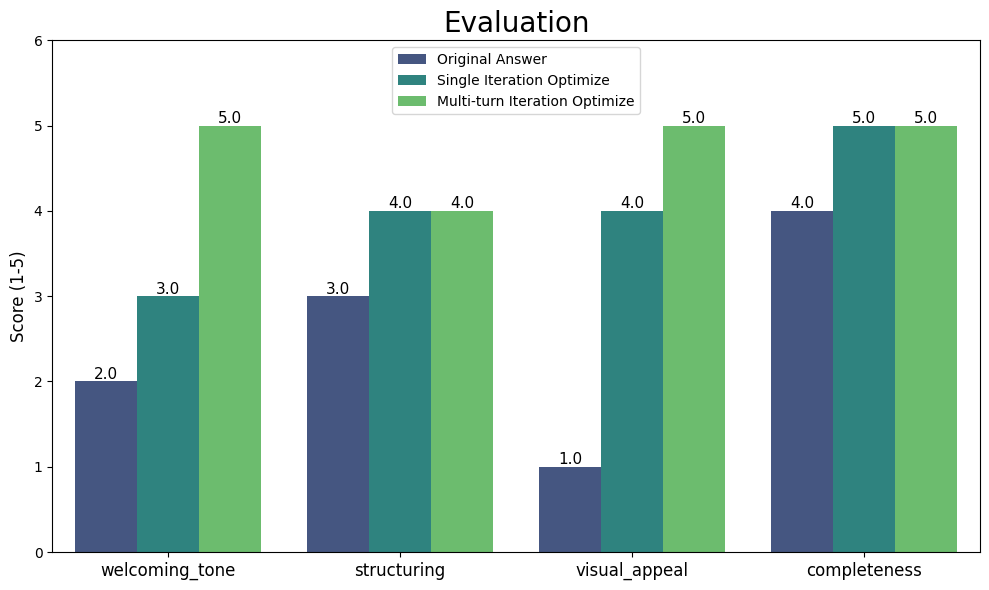
你可以看到,每次迭代的大模型的回复效果都有不同程度的提升。通过这种量化评估,你不仅能直观地看到每次优化带来的提升,还能将“好”或“不好”这种模糊的感觉,转化为清晰、可衡量的数据。这为你提供了一种科学的方法来验证和迭代你的提示词策略,确保每一步改进都有据可依,最终交付出真正高质量的用户体验。
2.7 让大模型帮你打造专属“AI 裁判”
上一节的自动化优化循环非常强大,但它引出了一个关键的工程问题:这个循环何时停止? 问题的关键在于,依赖“差距大不大”这种模糊的评价是不可靠的。你需要一个“AI裁判”,它能依据预设的量化标准,对每次优化结果给出明确的“✅通过”或“❌不通过”结论,从而为你的自动化流程提供一个清晰、可靠的停止条件。
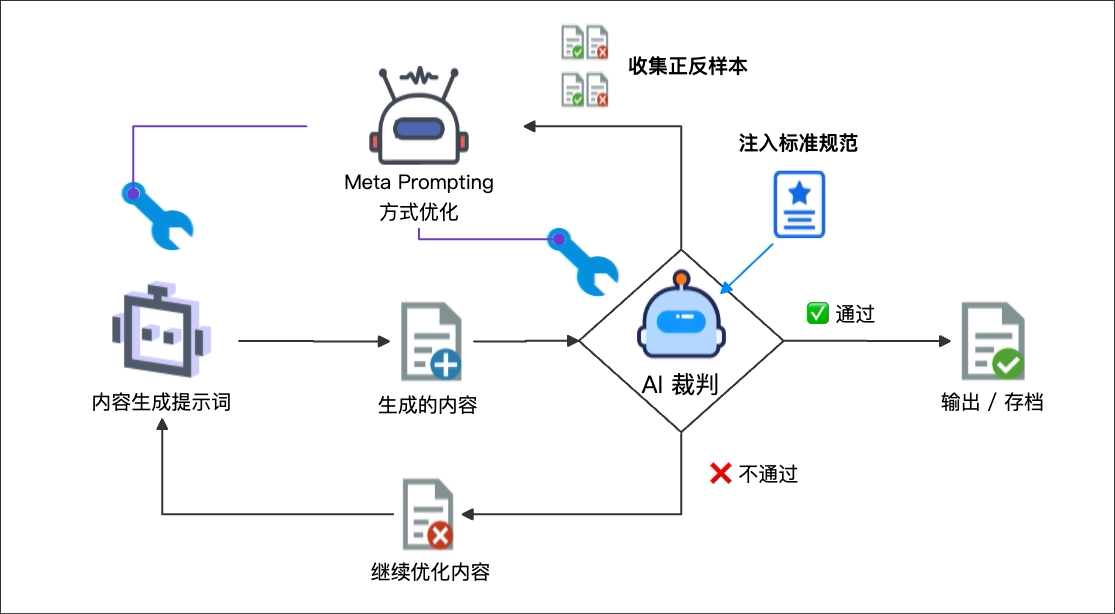
图: 通过Meta-Prompting构造一个 “AI 裁判”,替代 analyze_gap() 方法,提升“判别”准确率。
“AI 裁判” 的训练流程
打造“AI 裁判”的过程可以看作是在训练一个机器学习的分类器。你要打造的“AI裁判”提示词就是待训练的“模型”,而你准备的标准样本就是“数据集”。整个流程就是通过数据来“训练”你的“模型”。
准备数据集:首先创建一批高质量的标注样本(包含“好答案”与“坏答案”)。
迭代“训练”:
- a. 将这批数据自动按比例(如 7:3)拆分为“训练集”和“评估集”。
- b. 使用当前的“裁判提示词”,分别在训练集和评估集上进行“预测”,并记录下各自的准确率分数。 为什么要监控两个分数? 关注这两个分数的变化,能帮你判断“模型”是否出现了“过拟合”——即它只是“背会”了训练题,而对新题(评估集)的判断能力没有真正提升。
- c. 找出在训练集上判断错误的“错题”。
- d. 将这些“错题”连同你的分析,通过 Meta Prompting 的方式,让大模型帮你优化“裁判提示词”,生成一个新版本。
- e. 重复 b-d 的步骤。你可以随时停止“训练”。
停止“训练”: 在每一轮迭代中,你需要介入分析:
- 训练准确率和评估准确率是否都在稳步提升?
- 评估准确率是否停滞或突然下降(可能过拟合)
- 新产生的“错题”是否暴露了样本本身的模糊性或矛盾?(样本质量不好)
注意:如果样本质量不好,导致评价标准不一致或对同类问题给出模棱两可的判断,大模型可能永远也无法构造出一个性能优秀的“AI裁判”。这时,你可以停止迭代,先去优化你的样本数据。
最终,由你来决定何时停止“训练”,并采纳在评估集上表现最好的那个版本的提示词,作为你最终的“AI 裁判”。
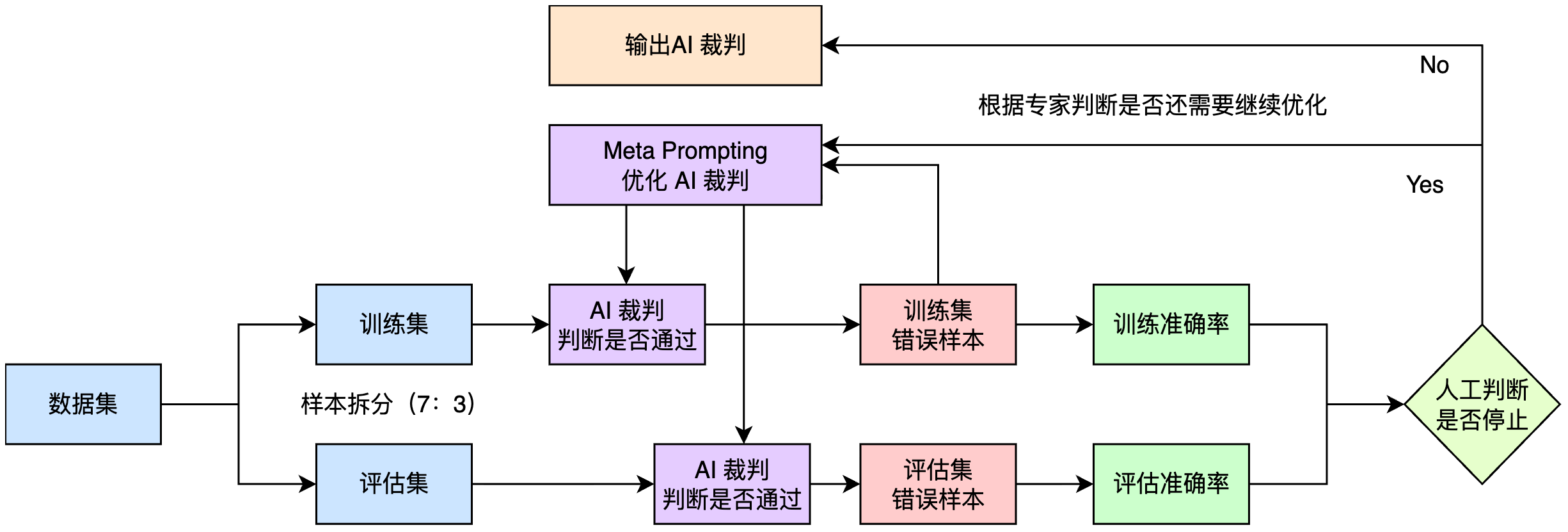
图: 采用机器学习训练模型的思路来迭代 “AI 裁判”,并根据训练和评估阶段的准确率、召回率等指标的对比,决定是否结束训练。
3. 推理大模型
前面所讲的提示词技巧和提示词框架可以广泛适用于通用大模型(如Qwen2.5-max、GPT-4、DeepSeek-V3),这类模型面向通用对话、知识问答、文本生成等广泛的场景。除了通用大模型,目前还有一类专门为“推理”设计的大模型——推理大模型。
3.1 什么是推理大模型?
from openai import OpenAI
import os
def reasoning_model_response(user_prompt, system_prompt="你是一个编程助手。", model="qwen3-235b-a22b-thinking-2507"):
"""
prompt: 用户输入的提示词
model: 此处以 qwen3-235b-a22b-thinking-2507 为例,可按需更换推理模型名称,如:deepseek-r1
"""
# 初始化客户端
client = OpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url=os.getenv("BASE_URL")
)
# 初始化状态变量
is_answering = False
# 发起流式请求
completion = client.chat.completions.create(
model=model,
# messages=[{"role": "user", "content": prompt}],
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
],
stream=True,
)
# 打印思考过程标题
print("\n" + "=" * 20 + "思考过程" + "=" * 20 + "\n")
# 处理流式响应
for chunk in completion:
if chunk.choices:
delta = chunk.choices[0].delta
if hasattr(delta, 'reasoning_content') and delta.reasoning_content is not None:
# 处理思考过程内容
print(delta.reasoning_content, end='', flush=True)
else:
# 切换到答案输出模式
if delta.content != "" and not is_answering:
print("\n" + "=" * 20 + "完整回复" + "=" * 20 + "\n")
is_answering = True
# 处理答案内容
if delta.content:
print(delta.content, end='', flush=True)
reasoning_model_response(user_prompt="你是谁?")
通过例子可以看到,推理模型相较于通用大模型多出了“思考过程”,就像解数学题时有人会先在草稿纸上一步步推导,而不是直接报答案,减少模型出现“拍脑袋”的错误,同时在分步思考过程中,如果某一步骤发现矛盾,还可以回头检查并重新调整思路,展示推理步骤还可以方便人们理解,顺着模型的思考路线验证逻辑。
相较于通用大模型,推理大模型通常在解决复杂问题时更可靠,比如在数学解题、代码编写、法律案件分析等需要严谨推理的场景。并不是说推理模型一定更好,两种模型都有各自的应用场景,下表从一些典型维度对这两类模型进行了对比:
| 维度 | 推理模型 | 通用模型 |
|---|---|---|
| 设计目标 | 专注于逻辑推理、多步问题求解、数学计算等需要深度分析的任务 | 面向通用对话、知识问答、文本生成等广泛场景 |
| 训练数据侧重 | 大量数学题解、代码逻辑、科学推理数据集增强推理能力 | 覆盖百科、文学、对话等多领域海量数据 |
| 典型输出特征 | 输出包含完整推导步骤,注重逻辑链条的完整性 | 输出简洁直接,侧重结果的自然语言表达 |
| 响应速度 | 复杂推理任务响应较慢(需多步计算) | 常规任务响应更快(单步生成为主) |
推理模型还是通用模型?如何选择?以下是一些推荐:
- 明确的通用任务:对于明确定义的问题,通用模型一般能够很好地处理。
- 复杂任务:对于非常复杂的任务,且需要给出相对更精确和可靠的答案,推荐使用推理模型。这些任务可能有:
- 模糊的任务:任务相关信息很少,你无法提供模型相对明确的指引。
- 大海捞针:传递大量非结构化数据,提取最相关的信息或寻找关联/差别。
- 调试和改进代码:需要审查并进一步调试、改进大量代码。
- 速度和成本:一般来说推理模型的推理时间较长,如果你对于时间和成本敏感,且任务复杂度不高,通用模型可能是更好的选择。
当然你还可以在你的应用中结合使用两种模型:使用推理模型完成Agent的规划和决策,使用通用模型完成任务执行。
3.2 适用于推理大模型的提示词技巧
推理模型在面对相对模糊的任务也能给出详尽且格式良好的响应。你依然可以通过提示词技巧保证推理大模型的推理质量的下限:
技巧一:保持任务提示简洁清晰,提供足够的背景信息
前面介绍的清晰表达需求同样适用于推理模型,虽然推理模型能力很强,但却不能“看穿人的想法”,你需要保持提示简洁、清晰,从而让推理大模型专注于核心任务。
可以在结合本节** 限定角色和受众**、规定输出格式等技巧进一步限定范围,确保结果符合你的预期。
同时,如果提示词比较复杂,你可以通过分隔符帮助模型理解你的意图。
prompt_B="""
<audience>初级Python开发者</audience>
<task>函数性能优化,优化code中的代码。</task>
<format>
如有多种优化方案请按照如下格式进行输出:
【优化方案X】
问题描述:[描述]
优化方案:[描述]
示例代码:[代码块]
</format>
<code>
def example(a):
b = []
for i in range(len(a)):
b.append(a[i]*2)
return sum(b)
</code>
"""
reasoning_model_response(user_prompt=prompt_B)
技巧二:避免思维链提示
你了解到通过思维链(COT)技术让大模型深入思考提升回复效果。 一般来说,你无需提示推理模型“逐步思考”或“解释你的推理”,因为它们本身会进行深入的思考,你的提示可能反而限制推理模型的发挥。除非你需要大模型严格按照固定的思路去推理,这种情况很少发生。
技巧三:根据模型响应调整提示词
推理模型因其回复形式(包含思考过程),天然适合你分析它的思考推理结论的过程,便于你调整提示词。 因此,你不需要纠结提示词是否足够完善,只需要不断与推理模型对话,过程中补充信息,完善提示词即可。 比如当你的描述太抽象或无法准确描述时,你可以用本节4.4讲到的增加示例的技巧来明确这些信息,这些示例有时可以从与模型的对话历史中挑选出来。 这个过程可以是重复多次的,不断尝试调整提示,让模型不断推理迭代,直到符合你的要求。
技巧四:让推理模型成为你的“提示词教练”
你学习了 Meta Prompting,即让大模型帮助你优化提示词。那么,哪种模型最适合扮演这位“教练”的角色呢?
答案是推理模型。
由于推理模型擅长分步思考和逻辑推导,它们在分析一个提示词的优缺点、并系统性地提出改进建议方面表现得尤为出色。它们不仅能给你一个更好的提示词,还能清晰地展示出“为什么”这样改会更好,让你在优化过程中也能学到提示词工程的精髓。
这充分展示了将合适的工具用在合适的任务上的重要性,这背后是 任务复杂性 与 执行成本(时间与费用) 之间的权衡:
通用模型(非推理模型):
- 优势:执行速度快,成本较低。
- 适用场景:适合执行相对直接、明确的任务,例如根据一个已经优化好的提示词进行信息提取、格式转换或简单问答。
推理模型:
- 优势:擅长处理复杂、模糊或需要深度逻辑推导的任务。
- 适用场景:更适合执行“元任务”(meta-task),例如分析和优化另一个任务(即提示词本身)的定义、进行复杂的规划或调试代码。
- 成本:由于需要进行多步思考,其响应时间通常更长,成本也相对更高。
在你构建自己的大模型应用时,混合使用这两种模型往往是实现最佳性价比的策略。你可以借鉴这种思路,构建一个“分工明确”的智能系统: 当任务需要深度思考或规划时,引入推理模型来充当“规划师”或“分析师”的角色,让它来分解复杂任务或优化流程;然后,将拆解后的、更简单的子任务交由通用模型或其他工具来高效、低成本地执行。这种协作模式,能让你在保证高质量输出的同时,有效控制应用的响应时间和运行成本。
本节小结
通过学习本节课程,你掌握了更多上下文工程(Context Engineering) 的高级技巧,从设计精细的提示词到实现智能的意图路由。回顾过去两节课,我们已经为答疑机器人装备了两大核心能力:
- 知识填充 (通过 RAG):解决了模型“不知道”私有信息的问题。
- 行为引导 (通过提示词与控制流):解决了模型“如何做”、“做什么”的问题。 这些技巧的共同核心,正是上下文工程的精髓:
通过精心设计和填充模型的上下文窗口,来引导和控制其生成期望的输出——这对于你用好大模型至关重要。
实际落地大模型应用的过程中,提示词部分经常让领域专家来共同设计。因此,在你的工程代码中硬编码提示词,应该考虑调整成可配置的,甚至应用流程也可配置,这样能更方便领域专家参与提示词和整个流程的设计。