1. RAG的工作原理
你在考试的时候有可能会因为忘记某个概念或公式而失去分数,但考试如果是开卷形式,那么你只需要找到与考题最相关的知识点,并加上你的理解就可以进行回答了。
对于大模型来说也是如此,在训练过程中由于没有见过某个知识点(比如你们公司的制度文件),因此直接向它提问相关问题会得到不准确的答案;如果在大模型生成内容时,像开卷考试一样将相关知识提供给它作为参考,那么大模型回答的质量也就会大幅提高了。
这引出了之前提到的一个核心理念:上下文工程(Context Engineering),专注于为大模型的“上下文窗口”填充恰到好处的信息,以引导其完成特定任务。如果信息太少,模型会“不知道”;如果信息太多或无关,模型的性能会下降,成本也会增加。
而我们即将学习的 RAG(Retrieval Augmented Generation,检索增强生成),正是上下文工程中最重要、最有效的技术之一,专门解决大模型“知识不足”的问题。RAG应用通常包含建立索引与检索生成两部分。
1.1 建立索引
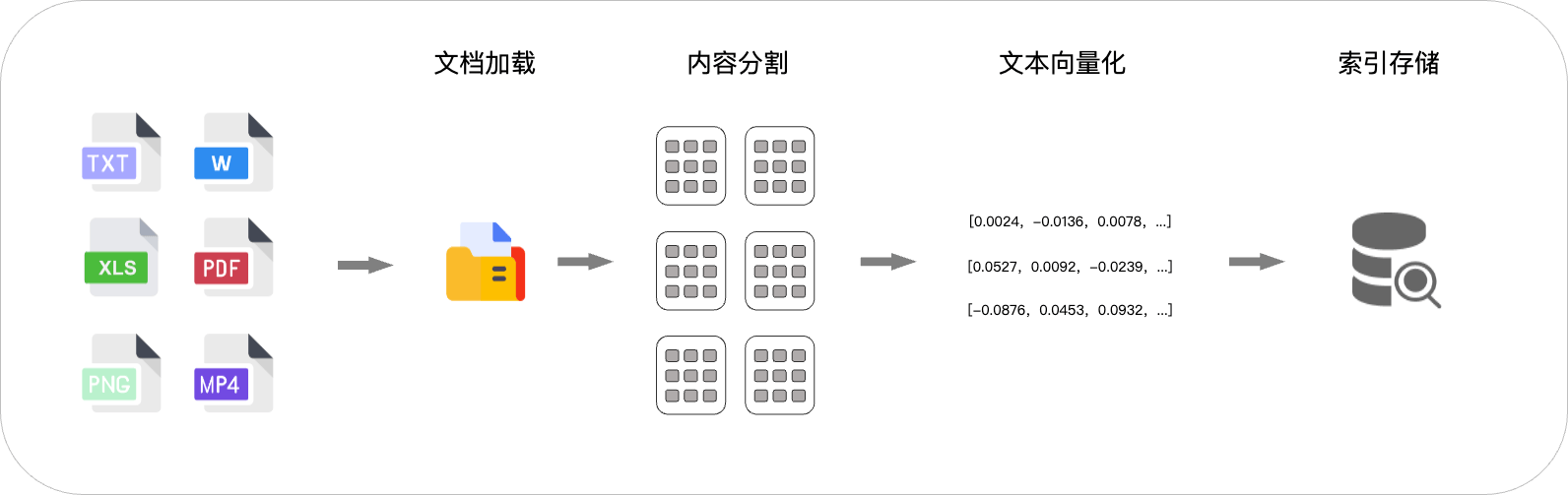
你可能会在考试前对参考资料做标记,来帮助你在考试时更容易地找到相关信息。类似的,RAG应用往往也会在回答前就已经做好了标记,这一过程叫做建立索引,建立索引包括四个步骤:
文档解析
就像你会将书上看到的视觉信息理解为文字信息一样,RAG应用也需要首先将知识库文档进行加载并解析为大模型能够理解的文字形式。
文本分段
你通常不会在做某道题时把整本书都翻阅一遍,而是去查找与问题最相关的几个段落,因此你会先把参考资料做一个大致的分段。类似的,RAG应用也会在文档解析后对文本进行分段,以便于在后续能够快速找到与提问最相关的内容。
文本向量化
在开卷考试时,你通常会先在参考资料中寻找与问题最相关的段落,再去进行作答。在RAG应用中,通常需要借助嵌入(embedding)模型分别对段落与问题进行数字化表示,在进行相似度比较后找出最相关的段落,数字化表示的过程就叫做文本向量化。
存储索引
存储索引将向量化后的段落存储为向量数据库,这样RAG应用就无需在每次进行回复时都重复以上步骤,从而可以增加响应速度。
在建立索引后,RAG应用就可以根据用户的问题检索出相关的文本段了。
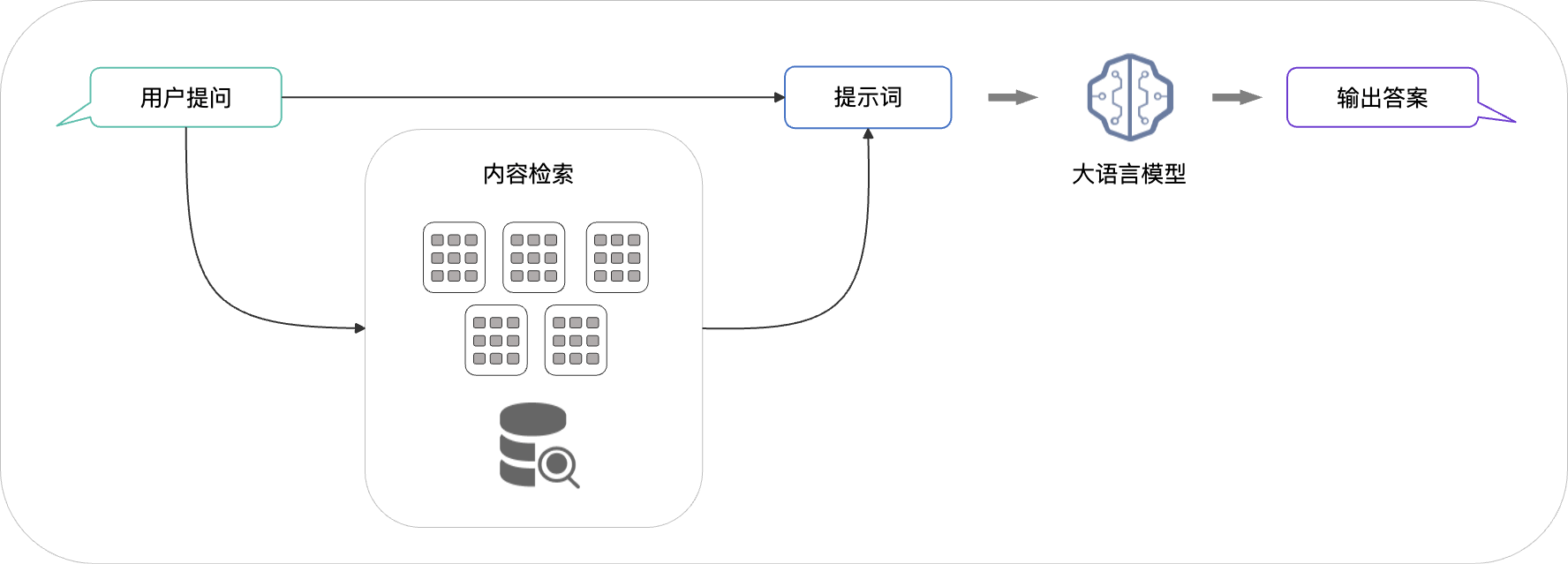
1.2 检索生成
检索、生成分别对应着RAG名字中的Retrieval(检索)与Generation(生成)两阶段。检索就像开卷考试时去查找资料的过程,生成则是在找到资料后,根据参考资料与问题进行作答的过程。
检索
检索阶段会召回与问题最相关的文本段。通过embedding模型对问题进行文本向量化,并与向量数据库的段落进行语义相似度的比较,找出最相关的段落。检索是RAG应用中最重要的环节,你可以想象如果考试的时候找到了错误的资料,那么回答一定是不准确的。这个步骤完美诠释了上下文工程的精髓:从海量知识中“精准地选择相关信息”来填充上下文。找到最匹配的内容,是保证后续生成质量的第一步。为了提高检索准确性,除了使用性能强大的embedding模型,也可以做重排(rerank)、句子窗口检索等方法,这些内容你可以在之后的章节进行学习。
生成
在检索到相关的文本段后,RAG应用会将问题与文本段通过提示词模板生成最终的提示词,由大模型生成回复,这个阶段更多是利用大模型的总结能力,而不是大模型本身具有的知识。这个提示词模板的设计,是上下文工程的另一个关键环节。我们不仅要提供检索到的“资料”,还要明确地“指导”模型如何使用这些资料来回答问题。
一个典型的提示词模板为:
请根据以下信息回答用户的问题:{召回文本段}。用户的问题是:{question}。
2. 创建RAG应用
构建一个RAG应用需要实现以上功能,这个过程并不容易。但通过LlamaIndex,你不需要过多代码就可以完成上述功能。
# 导入依赖
from llama_index.embeddings.dashscope import DashScopeEmbedding,DashScopeTextEmbeddingModels
from llama_index.core import SimpleDirectoryReader,VectorStoreIndex
from llama_index.llms.openai_like import OpenAILike
# 跳过NLTK下载,因为LlamaIndex默认使用NLTK进行文本预处理,但在某些环境中可能会因为网络问题导致下载失败,设置环境变量LLAMA_INDEX_DISABLE_NLTK为1可以禁用NLTK的使用。
import os
os.environ["LLAMA_INDEX_DISABLE_NLTK"] = "1"
# 这两行代码是用于消除 WARNING 警告信息,避免干扰阅读学习,生产环境中建议根据需要来设置日志级别
import logging
logging.basicConfig(level=logging.ERROR)
print("正在解析文件...")
# LlamaIndex提供了SimpleDirectoryReader方法,可以直接将指定文件夹中的文件加载为document对象,对应着解析过程
documents = SimpleDirectoryReader('./docs').load_data()
print("正在创建索引...")
# from_documents方法包含切片与建立索引步骤
index = VectorStoreIndex.from_documents(
documents,
# 指定embedding 模型
embed_model=DashScopeEmbedding(
# 你也可以使用阿里云提供的其它embedding模型:https://help.aliyun.com/zh/model-studio/getting-started/models#3383780daf8hw
model_name=DashScopeTextEmbeddingModels.TEXT_EMBEDDING_V2
))
print("正在创建提问引擎...")
query_engine = index.as_query_engine(
# 设置为流式输出
streaming=True,
# 此处使用qwen-plus模型,你也可以使用阿里云提供的其它qwen的文本生成模型:https://help.aliyun.com/zh/model-studio/getting-started/models#9f8890ce29g5u
llm=OpenAILike(
model="qwen-plus",
api_base="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key=os.getenv("DASHSCOPE_API_KEY"),
is_chat_model=True
))
print("正在生成回复...")
streaming_response = query_engine.query('我们公司项目管理应该用什么工具')
print("回答是:")
# 采用流式输出
streaming_response.print_response_stream()
2.1 保存与加载索引
你可能会发现,创建索引消耗的时间比较长。如果能够将索引保存到本地,并在需要使用的时候直接加载,而不是重新建立索引,那就可以大幅提升回复的速度,LlamaIndex提供了简单易实现的保存与加载索引的方法。
# 将索引保存为本地文件
index.storage_context.persist("knowledge_base/test")
print("索引文件保存到了knowledge_base/test")
# 将本地索引文件加载为索引
from llama_index.core import StorageContext,load_index_from_storage
storage_context = StorageContext.from_defaults(persist_dir="knowledge_base/test")
index = load_index_from_storage(storage_context,embed_model=DashScopeEmbedding(
model_name=DashScopeTextEmbeddingModels.TEXT_EMBEDDING_V2
))
print("成功从knowledge_base/test路径加载索引")
print("正在创建提问引擎...")
query_engine = index.as_query_engine(
# 设置为流式输出
streaming=True,
# 此处使用qwen-plus模型,你也可以使用阿里云提供的其它qwen的文本生成模型:https://help.aliyun.com/zh/model-studio/getting-started/models#9f8890ce29g5u
llm=OpenAILike(
model="qwen-plus",
api_base="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key=os.getenv("DASHSCOPE_API_KEY"),
is_chat_model=True
))
print("正在生成回复...")
streaming_response = query_engine.query('我们公司项目管理应该用什么工具')
print("回答是:")
streaming_response.print_response_stream()
from chatbot import rag
# 引文在前面的步骤中已经建立了索引,因此这里可以直接加载索引。如果需要重建索引,可以增加一行代码:rag.indexing()
index = rag.load_index(persist_path='./knowledge_base/test')
query_engine = rag.create_query_engine(index=index)
rag.ask('我们公司项目管理应该用什么工具', query_engine=query_engine)
2.2 RAG 多轮对话
在之前的课程中,你已经学习了如何通过维护 messages 列表来实现与大模型的多轮对话。然而,在RAG应用中实现多轮对话会面临一个独特的挑战。
RAG多轮对话的挑战
回想一下RAG的检索阶段:系统会将用户的问题与知识库中的文本段进行语义相似度比较,找出最相关的内容。但如果用户的问题依赖于对话历史中的上下文,会发生什么呢?
举个例子:
- 第一轮:用户问「张三的工位在哪里?」
- 第二轮:用户接着问「他的主管是谁?」
如果检索系统只用第二轮的问题「他的主管是谁?」去匹配文本段,它根本不知道「他」指的是谁,很可能召回错误的内容,导致回答不准确。
解决方案:问题改写
如果把完整的对话历史和问题一起输入检索系统,由于文本过长,embedding模型的效果会下降。业界通用的解决方案是:
- 问题改写:利用大模型根据对话历史对当前问题进行改写,将上下文信息融入问题中
- 正常检索:使用改写后的问题进行检索和生成
例如,上面的例子中,大模型会将「他的主管是谁?」改写为「张三的主管是谁?」,这样检索系统就能准确地找到相关信息了。
LlamaIndex 提供了便捷的工具来实现RAG应用中的多轮对话功能。
from llama_index.core import PromptTemplate
from llama_index.core.llms import ChatMessage, MessageRole
from llama_index.core.chat_engine import CondenseQuestionChatEngine
# 定义问题改写的提示词模板
custom_prompt = PromptTemplate(
"""
给定一段对话历史(人类与助手之间)和人类的后续问题,
请将该问题改写为一个独立的问题,包含对话中所有相关的上下文信息。
<对话历史>
{chat_history}
<后续问题>
{question}
<改写后的独立问题>
"""
)
# 模拟历史对话信息
custom_chat_history = [
ChatMessage(role=MessageRole.USER, content="内容开发工程师有哪些细分类型?"),
ChatMessage(role=MessageRole.ASSISTANT, content="内容开发工程师是综合性技术岗位。"),
]
# 创建查询引擎
query_engine = index.as_query_engine(
streaming=True,
llm=OpenAILike(
model="qwen-plus",
api_base="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key=os.getenv("DASHSCOPE_API_KEY"),
is_chat_model=True
))
# 创建支持多轮对话的聊天引擎
chat_engine = CondenseQuestionChatEngine.from_defaults(
query_engine=query_engine,
condense_question_prompt=custom_prompt,
chat_history=custom_chat_history,
llm=OpenAILike(
model="qwen-plus",
api_base="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key=os.getenv("DASHSCOPE_API_KEY"),
is_chat_model=True
),
verbose=True # 开启详细输出,可以看到改写后的问题
)
# 提问时只说「核心职责是什么」,不提及「内容开发工程师」
streaming_response = chat_engine.stream_chat("核心职责是什么?")
for token in streaming_response.response_gen:
print(token, end="")
运行上面的代码,你会发现虽然最后一个问题没有提及「内容开发工程师」,但大模型根据对话历史将问题改写为「内容开发工程师的核心职责是什么?」,从而检索到了正确的信息并给出了准确的回答。
💡 小贴士:
CondenseQuestionChatEngine会自动管理对话历史,你也可以通过chat_engine.chat_history查看当前的对话记录。- 设置
verbose=True可以看到改写后的问题,便于调试和理解系统的工作过程。- 问题改写的质量直接影响检索效果,你可以根据实际场景调整改写提示词模板。
3.本节小结
在本节课程中,你学习了RAG的工作原理,并动手构建了一个完整的RAG应用。
我们来回顾一下:
理解了RAG的工作原理
一个完整的RAG应用通常包含两个阶段:建立索引与检索生成。建立索引阶段包括文档解析、文本分段、文本向量化、存储索引四个步骤。通过理解RAG的工作原理,你可以更好地对RAG应用进行优化和改进。
创建了RAG应用
通过LlamaIndex提供的高度集成工具,你快速地创建了一个RAG应用,并学习了如何保存和加载索引。
掌握了RAG中的多轮对话
你了解了RAG多轮对话面临的独特挑战(检索时上下文丢失),以及业界通用的解决方案(问题改写)。通过LlamaIndex的CondenseQuestionChatEngine,你实现了能够理解对话上下文的RAG应用。
虽然RAG应用已经能够较好地回答「我们公司项目管理应该用什么工具」这样的问题,但目前的功能还比较基础。在后续教程中,我们将探索更多提升RAG应用能力的方法。下一节将着重介绍如何通过优化提示词来提升RAG应用的回答质量。
拓展阅读
文本向量化
计算机并不能直接理解“我喜欢吃苹果”与“我爱吃苹果”这两句话到底有多相似,但它能理解两个相同维度的向量的相似度(通常使用余弦相似度来衡量)。文本向量化通过embedding模型,将自然语言转化为计算机能够理解的数字形式。
embedding模型的训练通常会包含对比学习的环节,输入数据是许多已标记为是否相关的文本对(s1,s2),模型的训练目标是尽可能让相关的文本对生成的向量相似度变高,不相关的文本对生成的向量相似度变低。
在建立索引阶段,假设已经通过文本分段获得了n个chunk:[c1,c2,c3,…,cn],那么embedding模型会将这n个chunk分别转化为向量:[v1,v2,v3,…,vn],并存储为向量数据库。
在检索阶段,假设用户的问题为q,那么embedding模型会将问题q转化为向量vq,并在向量数据库中找出与vq最相似的n个向量(这个值你可以自己设定),通过向量与文本段的索引关系得到文本段,作为检索结果。