0. 前言
既然答疑机器人对写作规范了如指掌,那么能不能试着让它辅助开发教育课程呢?
让我们分析一下技术可行性。你会发现,机器人只能从内部知识库中获取写作规范。它既不能获取最新的研究论文,也无法自动记住课程的开发进度。
这是因为,单纯的大语言模型(LLM)就像一个被隔离在房间里的大脑——它能思考,但没有感官接收实时信息,没有手脚执行具体任务,也缺乏持续学习的能力。
为了突破这些局限,你需要在大模型基础上构建一套完整系统,让它像业务专家一样感知环境、思考规划、执行任务并从经验中学习。这个系统就是 Agent(智能体)
Agent 构建是一门实验科学,目前尚无标准的方法论,因此你需要在实践中不断探索和迭代 Agent 架构。 本节课将深入讲解 Agent 核心模块和评测体系,帮助你掌握:
- 任务分解能力:将复杂需求拆解为可执行步骤
- 原型构建能力:快速搭建业务 Agent 系统
- 评测和迭代能力:量化诊断并持续优化
1 让 Agent 学会使用工具
1.1 你的第一个工具函数
有位同事正在开发一篇“大模型基本原理”的在线课程,他希望机器人可以帮他搜集互联网上最新的教学素材。
你会发现,机器人只能从公司知识库中检索信息,或者用大模型的世界知识回答问题。
1.1.1 硬编码方案:最简单的实现
要让机器人能获取互联网信息,最直接的思路是:为机器人编写一个联网搜索工具函数,它每次都会搜索用户的问题,并把搜索结果和问题一并发送给大模型。
假设你已经写好了一个名为 web_search 的函数,它可以通过搜索引擎查找资料。现在,当用户提出请求时,你希望模型能够利用这个函数。最简单的实现方式是,在收到请求后,程序“硬编码”执行这个函数,然后将执行结果与原始请求一并发送给大模型,让它生成一段总结性的回复。

# 1. 用户的原始请求
user_request = "你好,请帮我搜集一些关于 Transformer 模型的最新资料。"
# 2. “硬编码”执行工具函数
# 这里的 web_search 函数是模拟的,以聚焦于核心逻辑
def web_search(query: str):
"""模拟执行网络搜索并返回JSON格式的结果"""
print(f"--- [工具执行中] 正在搜索: {query} ---")
# 真实场景中,这里会调用一个真正的搜索引擎API
return '''{
"results": [
{"title": "Attention Is All You Need (Transformer 论文原文)", "url": "https://arxiv.org/abs/1706.03762", "snippet": "The dominant sequence transduction models are based on complex recurrent or convolutional neural networks... We propose a new simple network architecture, the Transformer, based solely on attention mechanisms..."},
{"title": "The Illustrated Transformer – Jay Alammar", "url": "https://jalammar.github.io/illustrated-transformer/", "snippet": "A visual and intuitive explanation of the Transformer model."}
]
}'''
tool_result = web_search(query=user_request)
print(f"用户请求: {user_request}")
print(f"工具结果: {tool_result}\n")
# 3. 将用户请求和工具结果拼接成一个提示,发送给大模型
# 目标是让模型基于结构化的工具输出,生成一句人类易于理解的回复。
completion = client.chat.completions.create(
model="qwen-plus",
messages=[
{'role': 'system', 'content': '你是一位课程研究助理,你的任务是根据工具的执行结果,向用户生成一句友好和清晰的回复。'},
{'role': 'user', 'content': f'用户原始请求: "{user_request}"\n工具执行结果: {tool_result}'}
]
)
# 4. 输出模型的最终回复
final_response = completion.choices[0].message.content
print(f"模型生成的最终回复:\n{final_response}")
1.1.2 局限性分析:为什么需要更灵活的方案
这种方式虽然简单有效,但它也有局限性:只适用于“有且仅有一个工具,且每次对话都必须调用它”的场景。随着同事们的需求增长,你的机器人可能还要添加 search_arxiv_paper(在学术网站 Arxiv 搜索论文)、fetch_webpage_content(获取指定网页的全文内容)等更多工具。这时,你会遇到一个更棘手的问题:如何让机器人按需调用工具呢?
1.2 意图识别:让 Agent 决定用什么工具
1.2.1 脆弱的关键词匹配
一个直接的想法是编写一个“路由器”,通过 if/elif 结构和关键字匹配来判断用户的意图。例如
# 伪代码:一个脆弱的、基于关键字的工具路由器
def route_to_tool(user_input):
if "论文" in user_input or "arxiv" in user_input:
return "search_arxiv_paper"
elif "搜索" in user_input or "查找" in user_input or "资料" in user_input:
return "web_search"
elif "总结" in user_input or "内容" in user_input or "http" in user_input:
return "fetch_webpage_content"
# ... 你需要在这里不断添加 elif 判断
else:
return "no_tool_needed"
你立刻能发现这种方式的弊端。它非常脆弱且难以维护。如果用户说“我想看看那篇 Attention is All You Need 讲了什么”,这个简陋的路由器就无法识别出 search_arxiv_paper和fetch_webpage_content 的意图,因为它不包含任何预设的关键词。
1.2.2 基于大模型的意图识别
一个更优的思路是,你可以在提示词中列出所有工具,让大模型帮你决定调用哪个工具,使用什么入参。这就是意图识别的一种简单实现。
def get_tool_decision_from_llm(user_request):
from textwrap import dedent
# 使用 dedent 移除为了代码美观而添加的缩进,
# 避免这些格式化用的tab/空格被传递给大模型
prompt = dedent(f"""
你是一个智能助理的路由模块。你的任务是根据用户的请求,从下面的工具列表中选择最合适的工具来解决问题,并给出入参。
[可用工具列表]
1. web_search: 用于在互联网上搜索通用信息。
2. search_arxiv_paper: 用于在 Arxiv.org 上搜索学术论文。
3. fetch_webpage_content: 用于获取指定URL的网页内容。
[用户请求]
"{user_request}"
[决策]
请告诉用户你的决定。
""")
completion = client.chat.completions.create(
model="qwen-plus",
messages=[
{'role': 'user', 'content': prompt}
],
temperature=0.0 # 使用低 temperature 以获得更确定的决策
)
decision = completion.choices[0].message.content
return decision
# --- 测试用例 ---
request = "帮我找一下那篇经典的 Transformer 论文,标题是 'Attention Is All You Need'"
decision = get_tool_decision_from_llm(request)
print(f"用户请求: \"{request}\"")
print(f"模型决策: {decision}\n")
1.3 确保可靠:结构化输出
1.3.1 为什么需要结构化
现在你解决了“该调用哪个工具”的问题,下一步就是用代码解析和执行大模型的决策结果。然而,你会发现大模型返回的结果夹杂着自然语言,且没有固定的格式:
我将使用 search_arxiv_paper 工具来搜索标题为 "Attention Is All You Need" 的经典 Transformer 论文。好的,工具是 search_arxiv_papersearch_arxiv_paper(query="Attention Is All You Need")
这是因为大模型倾向于生成多样化的文本,而你需要的是一种易于解析的、确定的数据格式。要解决这个问题,你需要反过来,要求模型必须按照你预设的、严格的结构化格式进行输出。
JSON 就是这样一种理想的格式。一份定义清晰的 JSON 输出是无歧义且易于解析的:
{
"tool_name": "search_arxiv_paper",
"parameters": {
"query": "Attention Is All You Need"
}
}
它清晰地定义了“做什么”(tool_name)和“用什么做”(parameters)。这种键值对结构,任何编程语言都能轻松解析。
1.3.2 构建"引导-校验-重试"闭环
接下来的任务,就是如何确保模型能够稳定、严格地按照你定义的 JSON 结构进行输出。要实现这一目标,你需要建立一套清晰的流程。
定义结构:首先,你需要精确地定义你期望的输出结构。你可以使用 JSON Schema(一种用于描述 JSON 数据结构的语言),或是在 Python 代码中通过 Pydantic 等库来定义数据模型。这个 Schema 明确了最终产出物必须包含哪些字段、每个字段的类型,是整个流程的基石。
构建提示词:在你的提示词中,除了要下达任务指令,你还应该附上完整的 Schema 定义,并提供一到两个完全符合该 Schema 的输出范例。通过这种"指令 + 范例"的方式,模型能更透彻地理解你的要求。
校验与重试:程序在收到模型的输出后,须使用相同的 Schema 进行严格验证。如果验证失败,程序应捕获验证的错误信息,并将其连同模型上一次的错误输出,作为修正线索,再次发给模型,要求它重新生成。

import json
from textwrap import dedent
from typing import Union, Literal
from pydantic import BaseModel, Field, ValidationError, TypeAdapter
# 1. 为与课程研究相关的工具定义 Pydantic 参数模型
class WebSearchParams(BaseModel):
query: str = Field(description="用于网络搜索的关键词。")
class SearchArxivParams(BaseModel):
query: str = Field(description="用于在 Arxiv.org 上搜索的论文标题或关键词。")
# 2. 定义工具调用模型,将工具名与对应的参数模型绑定
class WebSearchCall(BaseModel):
tool_name: Literal["web_search"]
parameters: WebSearchParams
class SearchArxivCall(BaseModel):
tool_name: Literal["search_arxiv_paper"]
parameters: SearchArxivParams
# 使用 Union 类型,表示模型最终的决策是这两种调用中的一种
ToolCall = Union[WebSearchCall, SearchArxivCall]
# 3. 构建提示词,包含清晰的指令、工具定义和示例
def build_prompt(user_request: str) -> str:
return dedent(f"""
你的任务是根据用户的请求,从可用工具列表中选择最合适的工具,并以严格的 JSON 格式输出调用信息。
# 可用工具:
- `web_search(query: str)`: 当需要搜索通用信息、新闻或非学术性内容时使用。
- `search_arxiv_paper(query: str)`: 当需要搜索学术论文,特别是来自 Arxiv.org 的论文时使用。
# 输出格式要求:
你必须严格按照以下 JSON 结构输出,不要包含任何额外的自然语言解释。
{{
"tool_name": "工具名称",
"parameters": {{
"参数名": "参数值"
}}
}}
# 示例:
用户请求: "最近AI领域有什么好玩的新闻?"
你的输出:
{{
"tool_name": "web_search",
"parameters": {{
"query": "AI领域最新新闻"
}}
}}
# 用户请求:
"{user_request}"
# 你的输出:
""")
# 4. 调用并验证(带重试)
def get_structured_output(user_request: str, max_retries: int = 2):
messages = [{'role': 'user', 'content': build_prompt(user_request)}]
adapter = TypeAdapter(ToolCall)
for attempt in range(max_retries):
# 此处为对大模型服务的API调用,为保证课程的通用性,具体实现已省略
# 你可以替换成自己的代码,例如 client.chat.completions.create(...)
response = client.chat.completions.create(
model="qwen-plus", messages=messages, temperature=0
)
raw_output = response.choices[0].message.content
try:
# 解析并验证
data = json.loads(raw_output.strip('```json').strip('```'))
# 使用Pydantic模型验证解析后的数据
validated_data = adapter.validate_python(data)
return validated_data.model_dump()
except (json.JSONDecodeError, ValidationError) as e:
# 如果失败,则将错误信息和原始输出都加入到对话历史中,以便模型进行修正
messages.extend([
{'role': 'assistant', 'content': raw_output},
{'role': 'user', 'content': f"格式错误: {e},请严格按照JSON格式重新输出"}
])
return None
# 使用
# 假设 client 变量已在别处初始化
user_request = "帮我找一下那篇经典的 Transformer 论文,标题是 'Attention Is All You Need'"
result = get_structured_output(user_request)
if result:
print(json.dumps(result, indent=2, ensure_ascii=False))
通过建立这样一个“引导-校验-重试”的闭环,你可以提升解析的成功率,让你的工具调用代码变得更加健壮可靠。
扩展阅读:受控解码 (Controlled Decoding)
许多模型服务商提供的“JSON 模式 (JSON Mode)”并非单纯依靠“优化训练”,而是采用了一种更精准的技术:受控解码。
在模型生成每一个词元 (Token) 时,它会先计算出所有候选词元的概率分布。此时,系统会根据你提供的 Schema 编译出的语法规则,从这些候选词元中屏蔽掉所有不可能组成合法 JSON 的选项。
这就好比一个语法检查器,但它不是在事后检查,而是在你每次选择下一个字符时,就把所有会导致语法错误的选项从键盘上"隐藏"起来。
这项技术将"输出格式"从一个需要模型去"学习"的模糊任务,变成了一个由语法规则驱动的确定性过程,从根本上保证了输出的可靠性。
1.4 主流方案:函数调用 (Function Calling)
1.4.1 Function Calling 的工作原理
你刚刚手动实现的“意图识别 -> 结构化输出 -> 验证与重试”是一套健壮的工具调用流程,它的完整实现较为复杂。为了简化开发过程,许多大模型服务商(阿里云、OpenAI、Anthropic、Google等)已在 API 中内置了这一能力,这就是函数调用 (Function Calling) 或 工具调用 (Tool Calling)。
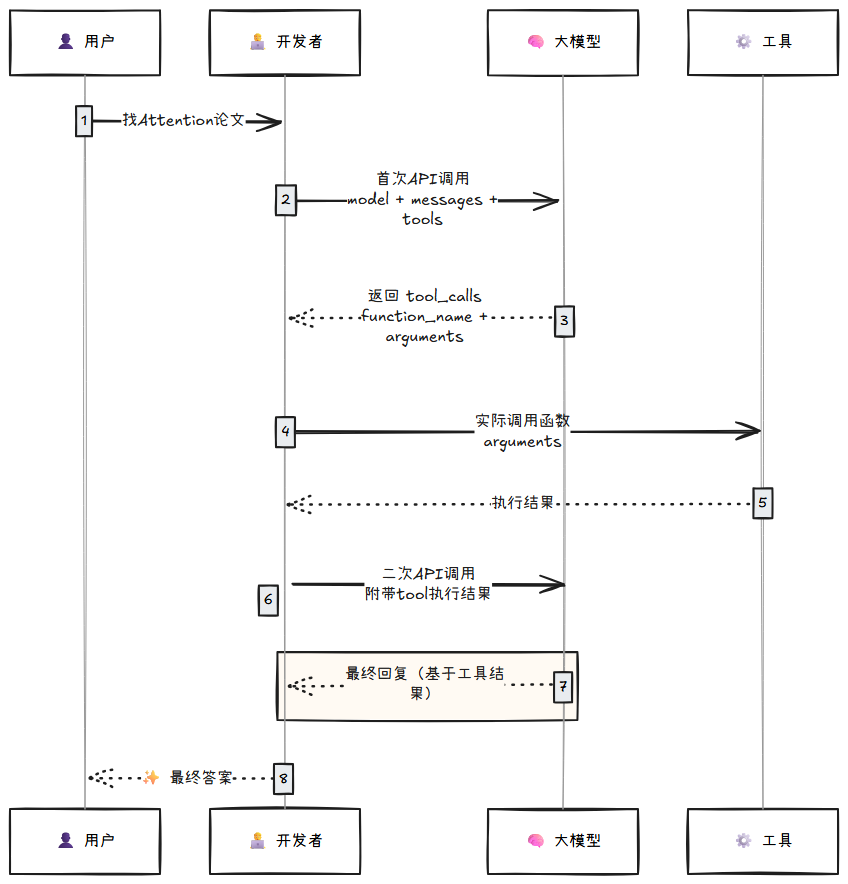
以 OpenAI SDK 的函数调用为例:
工具定义 (Tool Definition): 你需要在 API 的
tools参数中定义可用的工具,使用 JSON Schema 描述每个工具的name、description以及parameters(函数所需的输入参数结构)。调用决策 (Call Decision): 模型根据用户输入和工具定义,自动决策是否需要调用工具。如果需要,模型会在响应中返回
tool_calls字段,包含要调用的函数名和符合 Schema 的参数 JSON。执行与返回 (Execute & Return): 你需要:
- 解析
tool_calls中的函数名和参数 - 在你的代码中实际执行对应的函数
- 将函数执行结果包装成一条
role: "tool"的 message - 再次调用 API,将工具执行结果发送给模型
- 模型基于工具返回的结果,生成最终的用户回复
import json
# 1. 定义工具列表,包含每个函数的JSON Schema描述
tools = [
{
"type": "function",
"function": {
"name": "search_arxiv_paper",
"description": "在 Arxiv.org 上搜索学术论文",
"parameters": {
"type": "object",
"properties": {
"query": {"type": "string", "description": "论文的标题或关键词"},
},
"required": ["query"],
},
}
}
]
# 2. 发起第一次API调用,让模型决策
messages = [{"role": "user", "content": "帮我找一下那篇经典的 Transformer 论文 'Attention Is All You Need'"}]
response = client.chat.completions.create(
model="qwen-plus", messages=messages, tools=tools, tool_choice="auto"
)
response_message = response.choices[0].message
# 3. 检查模型是否决定调用工具并执行
if response_message.tool_calls:
tool_call = response_message.tool_calls[0]
function_name = tool_call.function.name
function_args = json.loads(tool_call.function.arguments)
print(f"模型决定调用工具: `{function_name}`")
print(f"参数: {function_args}")
# 这里我们模拟函数执行结果
tool_result = json.dumps({"paper_id": "1706.03762", "url": "https://arxiv.org/abs/1706.03762", "title": "Attention Is All You Need"})
print(f"工具执行结果: {tool_result}")
# 4. 将模型的决策和工具的执行结果一起传回,让模型生成最终答复
messages.append(response_message)
messages.append(
{"tool_call_id": tool_call.id, "role": "tool", "name": function_name, "content": tool_result}
)
final_response = client.chat.completions.create(model="qwen-plus", messages=messages)
print("\n模型的最终回复:")
print(final_response.choices[0].message.content)
1.4.2 ReAct 模式:思考-行动-观察
你会发现,工具调用的结果是通过又一次调用传递给大模型的,大模型会观察工具调用的结果,然后思考任务是否完成,从而回复你最终答案或继续行动(调用工具)。这和你之前学过的"多轮对话"很相似。
我们把这种思考——行动——观察的循环模式称为 ReAct,按照此模式工作的 Agent 称为 ReAct Agent。
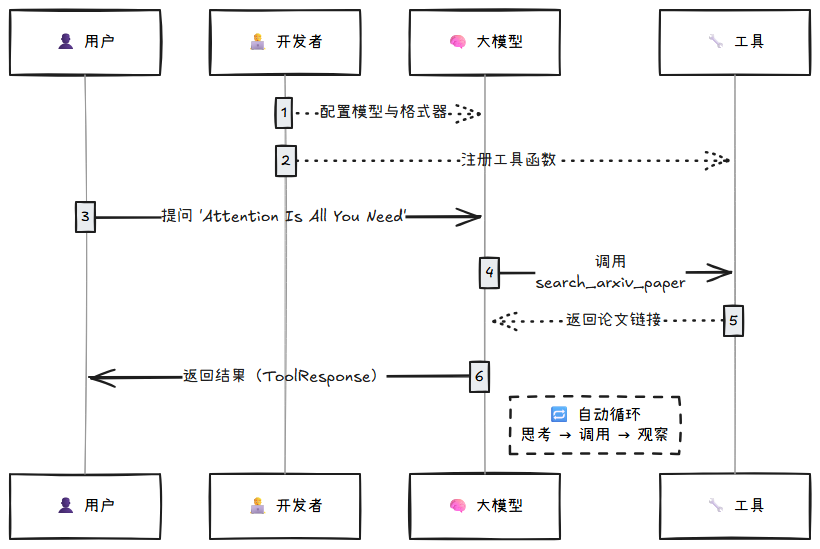
手动实现 ReAct Agent 的逻辑比较复杂。为了简化开发流程,我们将使用 AgentScope 这一生产级 Agent 框架——它已经帮你封装好了 ReAct Agent 和工具调用的完整逻辑。
AgentScope 是一套为开发者设计的、生产级别的 Agent 框架。它通过规范化的方式定义智能体的通信、记忆和工具调用,让你能专注于业务逻辑而非底层实现。AgentScope 的核心优势包括:
- 开箱即用的 ReAct Agent:内置了完整的"思考-行动-观察"循环逻辑
- 灵活的工具管理:通过
Toolkit类统一管理工具函数,支持自动解析工具的 JSON Schema- 多模型支持:兼容 OpenAI、DashScope(千问)、Anthropic 等主流 LLM API
- 状态管理:自动处理对话历史、工具调用记录等状态
- 异步支持:所有核心功能都支持异步调用,提升性能
让我们来看一下 AgentScope 是怎么实现刚才的工具调用的:
import asyncio
from agentscope.agent import ReActAgent
from agentscope.tool import Toolkit, ToolResponse
from agentscope.model import DashScopeChatModel
from agentscope.message import Msg, TextBlock
from agentscope.formatter import DashScopeChatFormatter
# 1. 定义一个工具,使用 ToolResponse 返回结果
def search_arxiv_paper(query: str) -> ToolResponse:
"""在 Arxiv.org 上搜索学术论文。
Args:
query (str): 搜索关键词
"""
print(f"--- [工具执行中] 正在 Arxiv 搜索: {query} ---")
# 此处模拟搜索结果
paper_url = "https://arxiv.org/abs/1706.03762"
return ToolResponse(
content=[
TextBlock(
type="text",
text=f"已成功找到论文 '{query}',你可以在这里访问:{paper_url}",
)
]
)
async def run_agentscope_example():
# 2. 将工具函数注册到工具箱(Toolkit)中
toolkit = Toolkit()
toolkit.register_tool_function(search_arxiv_paper)
# 3. 创建一个 ReActAgent 并为其配备工具箱
agent = ReActAgent(
name="Course Research Agent",
sys_prompt="你是一个课程研究助理,擅长帮人搜集和整理学习资料。",
model=DashScopeChatModel(
model_name="qwen-plus",
api_key=os.environ.get("DASHSCOPE_API_KEY")
),
toolkit=toolkit,
formatter=DashScopeChatFormatter()
)
# 4. 向 Agent 发送消息,它会自动完成所有步骤
user_request = "帮我找一下那篇经典的 Transformer 论文 'Attention Is All You Need'"
msg = Msg(name="user", content=user_request, role="user")
print(f"用户请求: {user_request}\n")
await agent(msg)
# 运行示例
try:
# 在Jupyter Notebook环境中,可以直接await协程
await run_agentscope_example()
except NameError:
# 在普通Python脚本中,需要使用asyncio.run()来运行异步函数
asyncio.run(run_agentscope_example())
与之前手动实现的 OpenAI Function Calling 相比,AgentScope 的优势在于:
- 工具定义更简洁:只需要写带文档字符串的普通 Python 函数,框架会自动解析生成 JSON Schema
- 无需手动解析:
ReActAgent内部自动处理tool_calls的解析、函数执行、结果包装等繁琐步骤 - 自动管理对话历史:框架会自动记录用户消息、工具调用、工具结果等,无需手动维护
- 支持多轮工具调用:如果一次工具调用不够,Agent 会自动继续思考并调用更多工具,直到完成任务
看到 AgentScope 的简洁实现,你可能会疑惑:既然有现成框架,为什么还要学习前面那套繁琐的手动实现?
这是因为:
理解底层原理:框架内部就是在执行"调用模型 → 解析 tool_calls → 执行函数 → 再次调用模型"这套流程。了解机制才能调试问题。
自定义需求:生产环境常需实现权限验证、缓存、重试、日志监控等特殊逻辑,理解底层才能扩展框架。
兼容性保障:部分模型或平台不支持标准 Function Calling 格式时,手动实现可作为降级方案。
1.5 规模化管理:MCP 协议 (Model Context Protocol)
1.5.1 工具复用的挑战
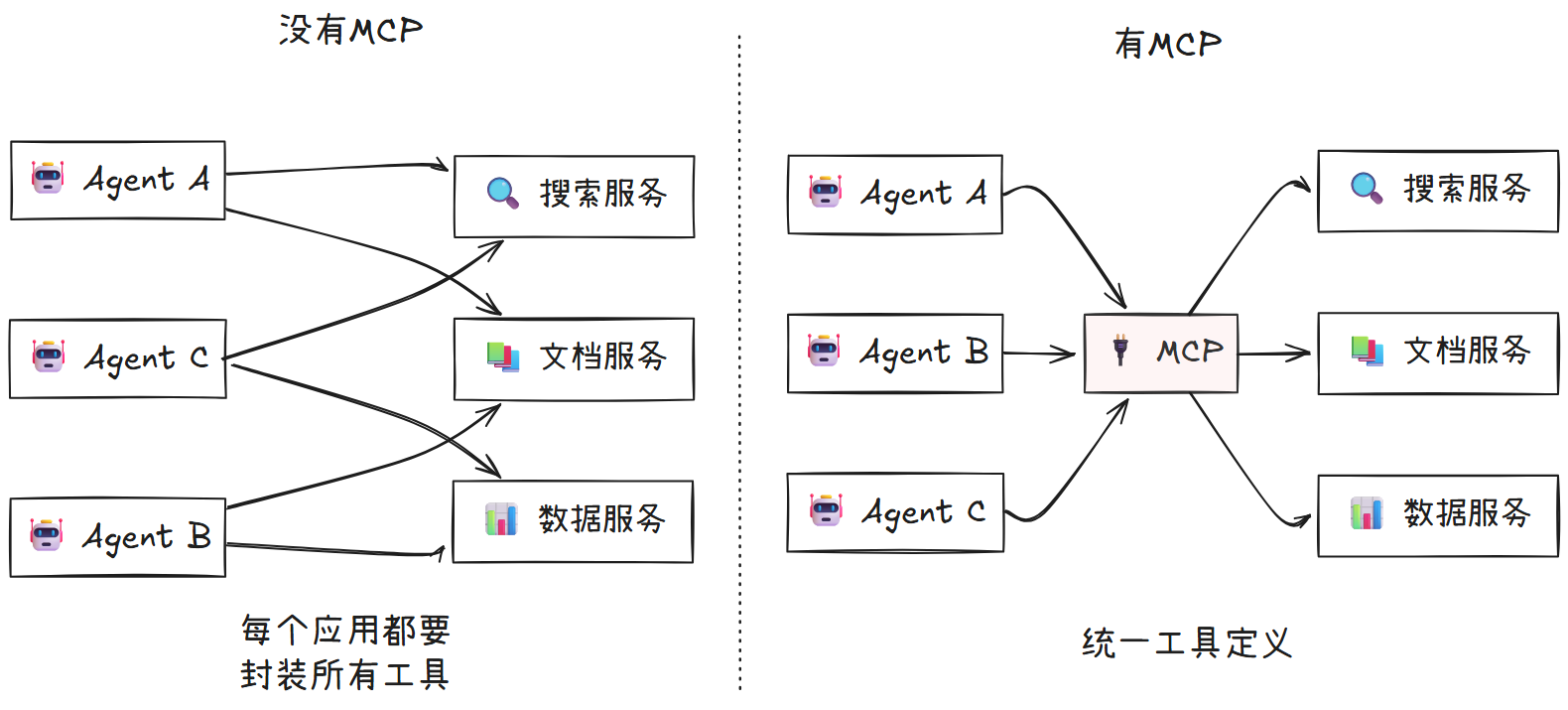
Function Calling 模式解决了单个应用如何调用工具的问题,但当工具需要在多个 Agent 应用中复用时,也引入了规模化维护的难题。
设想你的团队有多个 Agent,它们都需要调用互联网搜索、公司内部文档搜索等工具。如果工具的某个 API 参数发生变化,你需要修改所有依赖它的 Agent,这会产生高昂的维护成本。问题的根源在于,工具的定义被硬编码在了每个“消费方”(Agent 应用)的代码中。
1.5.2 MCP 的解耦思想
为解决此问题,Anthropic 公司提出了模型上下文协议 (Model Context Protocol, MCP)。其核心思想是将定义工具的职责从“消费方”转移到“提供方”。
- 没有 MCP:每个 AI 应用都需要自行封装所有工具的定义。工具升级时,所有应用都需修改。
- 使用 MCP:工具服务方(如搜索服务)自行“广播”其能力定义。AI 应用只需通过 MCP 协议连接到服务方,就能自动获取最新的工具定义,无需硬编码。
1.5.3 实践:连接远程 MCP 服务
AgentScope 提供了对 MCP 协议的直接支持。下面是一个简单示例:
import asyncio
import os
from agentscope.agent import ReActAgent
from agentscope.mcp import HttpStatelessClient
from agentscope.tool import Toolkit
from agentscope.model import DashScopeChatModel
from agentscope.message import Msg
from agentscope.formatter import DashScopeChatFormatter
async def run_mcp_example():
# 1. 配置 MCP 客户端,指向远程工具服务
# 这里连接的是阿里云DashScope公开的联网搜索MCP服务
web_search_client = HttpStatelessClient(
name="web_search_service", # 为这个客户端起一个名字
transport="sse",
url="https://dashscope.aliyuncs.com/api/v1/mcps/WebSearch/sse",
headers={"Authorization": "Bearer " + os.environ.get("DASHSCOPE_API_KEY")},
)
# 2. 将 MCP 客户端注册到工具箱
# Agent在启动时会自动通过客户端“发现”远程服务提供的所有工具
toolkit = Toolkit()
await toolkit.register_mcp_client(web_search_client)
# 3. 创建 Agent,并配备包含 MCP 工具的工具箱
agent = ReActAgent(
name="Research Assistant Agent",
sys_prompt="你是一个课程研究助理,擅长使用工具搜集和整理最新的教学素材。",
model=DashScopeChatModel(
model_name="qwen-plus", api_key=os.environ.get("DASHSCOPE_API_KEY")
),
toolkit=toolkit,
formatter=DashScopeChatFormatter()
)
# 4. 提出一个需要远程工具才能回答的问题
user_request = "我正在为'大模型原理'课程搜集素材,需要一个调用外部实时数据的例子,比如帮我搜索一下最近关于'大型语言模型'的最新进展。"
msg = Msg(name="user", content=user_request, role="user")
print(f"用户请求: {user_request}\n")
response_msg = await agent(msg)
try:
# 在Jupyter Notebook环境中,可以直接await协程
await run_mcp_example()
except NameError:
# 在普通Python脚本中,需要使用asyncio.run()来运行异步函数
asyncio.run(run_mcp_example())
在这个例子中,Agent 代码无需定义 WebSearch 工具,通过 MCP 协议在运行时动态地从 web_search_service 服务发现工具及其用法,从而实现了完全解耦。
MCP 通过解耦工具的定义与使用,致力于解决工具“如何被发现和管理”的规模化问题。
关联思考:USB 协议
你可以将 MCP 类比为现实世界中的 USB 协议。在 USB 出现之前,每种外设(鼠标、键盘、打印机)都有自己独特的接口,计算机需要为每一种接口都做适配。而 USB 协议统一了这一切,任何符合该协议的设备都可以即插即用。
- Function Calling 就像是计算机主板上的一个内部总线,它定义了 CPU 如何与某个特定组件通信。
- MCP 则像是外部的 USB 接口,它定义了一个开放标准,让无数第三方设备能够轻松地接入这个生态系统。
至此,你已掌握从单工具函数、可靠意图识别到规模化工具管理的完整链路。你的 Agent 现在可以稳定高效地与外部世界交互。
1.6 总结
让我们回顾一下你在本节学到的知识:
- 为模型连接外部世界:你学会了如何为 Agent 编写工具函数来获取外部信息,并从脆弱的
if/else规则判断,升级到利用大模型自身的理解能力来决定调用哪个工具。 - 手动实现可靠的工具调用:你掌握了通过构建“引导-校验-重试”的闭环,让模型稳定输出结构化的 JSON 指令,并理解了这是实现健壮工具调用的底层逻辑。
- 函数调用与工具发现:你学习了“函数调用”这一行业标准,它将工具调用的复杂流程封装成简单的 API。更进一步,你也了解了 MCP 协议如何将工具的定义与使用解耦,解决了规模化复用与维护的难题。
- ReAct 循环与开发框架:你认识到工具调用是实现 ReAct (思考-行动-观察) 循环模式的关键,并学会使用 AgentScope 这样的开发框架,将你从手动实现的繁琐流程中解放出来,更专注于业务逻辑。
2 让 Agent 学会反思
2.1 课程被意外修改
有一位同事写了一篇 notebook 格式的交互式课程,里面有一些可执行的 Python 代码。为了让课程的语言更生动,你让机器人帮忙润色整篇文档的语言风格。
经过润色后,课程的语言更加流畅、结构更加清晰了。但当他尝试运行课程里的代码示例时,却发现了一个关键问题:
# 课程的原始代码
def get_user_data(usr_id: str):
# ... some logic ...
return f"Data for {usr_id}"
# 正常执行
print(get_user_data(usr_id="u-123"))
机器人在“优化”语言风格时,悄悄地“修正”了代码:
# Agent 润色后的代码
def get_user_data(user_id: str):
# ... some logic ...
return f"Data for {user_id}"
# 运行时报错!
# print(get_user_data(usr_id="u-123"))
# TypeError: get_user_data() got an unexpected keyword argument 'usr_id'
机器人认为 user_id 比 usr_id 更规范,于是帮忙“优化”了函数定义,但这却导致调用函数的代码报错了,因为调用处的参数名没有一起改。
2.2 大模型的幻觉
你该如何解决这个问题呢?一个最直接的想法,就是告诉机器人要“小心一点”。试着在它的指令(System Prompt)里加上一句警告:
你是一位顶尖的课程作家,负责润色 Jupyter Notebook 格式的课程。
请优化文本,使其更具吸引力。
**重要:请绝对不要修改任何代码块中的内容,包括变量名、参数名和函数调用。**
但这样做效果不佳,因为你无法通过罗列禁止事项来覆盖所有可能的场景,即使你明确禁止了某些修改,大模型仍然有一定概率把原本正确的内容"顺手"改错。
其原因是,由于大模型存在幻觉,它的每一次生成都可能引入新的错误,而且缺乏验证和修正的内在机制。这种"优化"不仅限于变量名,还可能发生在
- 命令行参数(将
-p 8080改为--port 8080) - API 版本号(将
v1/users更新为v2/users) - 示例值(将演示用的 IP 地址
192.168.1.10替换为127.0.0.1)
等任何它认为"不够规范"的地方。最终,一篇经过"优化"却混杂了错误的课程,会让学员陷入无尽的调试循环。
因此,你自然会想到另一种思路:让大模型输出前自己检查一遍,就像在考试时,人类在交卷前会检查一遍答案。这正是目前业界解决此类问题的一种方法,我们称之为反思(Reflection)。
2.3 反思的两种模式
2.3.1 模式一:自我反馈 (Self Review)
要实现反思,最直接的思路是让模型自己审视输出结果。这里有两种实现方式,一种简单但效果有限,另一种更复杂但效果显著。
2.3.1.1 方法一:单步指令式反思
这是一种最容易想到的方法,你尝试在一次模型调用中,通过 Prompt 指示模型在生成答案的同时进行反思。
## 角色
你是一位顶尖的课程作家。
## 任务
1. 润色课程的语言表达,输出润色后的全文内容。
2. 反思润色后的内容:
⁃ 是否符合写作规范。
⁃ 除了语言表达,其他内容是否被意外修改。
输出反思的结果和修改建议。
3. 对照建议修改课程,输出修改后的全文内容。
## 课程初稿
{original_notebook_content}

这种方法有其优势:模型可以在生成过程中及时发现问题并纠错,同时上下文保持连贯,减少了多轮往返的开销。
但也存在明显的缺陷:反思和生成绑定在一起时,模型容易带着相同的思维偏差进行自我验证,陷入"自证正确"的怪圈。例如,如果它在第一步就把 usr_id 改成了 user_id,那么在第二步反思时,它很可能会认为这是一次"规范化改进"而非错误。
2.3.1.2 方法二:两步式"生成-反馈"
你也可以将反思过程独立出来,把任务拆分成两次模型调用,一次负责生成,另一次负责审查。
# 第一次调用 (写作 Agent)
你是一位顶尖的课程作家,负责润色 Jupyter Notebook 格式的课程。请优化文本,使其更具吸引力。
【课程初稿】:
{original_notebook_content}
# 第二次调用 (技术审查 Agent)
你是一个严苛的技术审查员。你的任务是审查润色后的课程内容,确保:
1. 润色后的课程符合写作规范。
2. 代码、配置、数据等技术内容没有被意外修改。
请比对【原始内容】和【润色后内容】:
- 如果只修改了文案表达,代码等技术内容完全一致(或只有注释、格式等非功能性变化),就回答"通过"。
- 如果发现任何技术内容被修改(如代码逻辑、变量名、参数、配置项等),就回答"不通过",并指出具体是哪处内容被意外修改了。
【原始内容】:
{original_notebook_content}
【润色后内容】:
{draft_content}
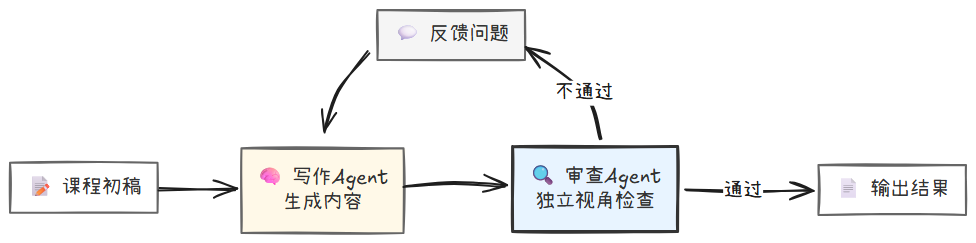
由于审查 Agent 的视角与写作 Agent 不同,这种方法能有效避免大部分角色偏见。你甚至可以设置多个专项审查 Agent——事实审查、逻辑审查、风格审查、安全审查,这不仅提高了审查的全面性,还便于后期进行 A/B 测试和指标统计。
但这种方法也有明显的成本:每增加一个审查 Agent 就多一轮模型调用,token 消耗更高。
扩展阅读:成本与优化
这笔成本值得吗?
“生成-反馈"循环看似增加了调用次数,但我们不能简单地将"一次高质量输出"与"一次低质量输出"的成本进行比较。更公平的比较是:为获得一个"可用"的答案,两种路径的总成本是多少?
如果单次调用无法有效解决问题,那么它的成本无论多低,都是一种浪费。相反,通过"生成-反馈"的两步调用,让中端模型达到顶级模型 95% 的效果,就能用更低的成本实现几乎相同的业务价值。
如何进一步降低成本?
在"生成-反馈"循环中,原始课程文档会在多次模型调用中重复传递——写作 Agent 需要它,审查 Agent 也需要它,修正阶段可能还要再用一次。如果文档很长(比如包含几十个代码示例的完整课程),这种重复会带来显著的 token 消耗。
有些模型会采用缓存机制: 首次调用时缓存共享内容(如原始文档),后续调用检测到相同前缀就直接复用
需要注意的是,应该让审查 Agent 只负责"发现问题"而不是"直接重写”。如果让它直接修改内容,可能会破坏原文的表达意图或引入新的错误。
所以,你最好将审查结果 (review_result) 反馈给写作Agent,让它根据反馈继续修改回答。这就形成了一个“生成—反馈”循环,机器人的回答忠实度得到了显著提升。
2.3.1.3 自我反馈的缺陷
自我反馈更适合静态文本层面的比对(如检查代码是否被意外修改),但当你需要验证代码是否能正常运行时,这种模式的效果比较差。
这是因为大模型擅长判断代码"看起来是否合理",但无法像编译器那样进行精确的语义验证。更关键的是,模型无法真正执行代码——它看不到运行日志、捕捉不到异常报错、也感知不到依赖库版本冲突或环境配置问题。
要解决这个问题,我们需要引入外部反馈机制。
2.3.2 模式二:外部反馈 (External Feedback)
2.3.2.1 使用工具验证结果
外部反馈的核心思路是:把大模型的生成结果放到真实环境中执行,再把执行结果(成功/失败、错误信息、测试报告等)反馈给模型,让它根据这些落地的事实进行迭代修正。
如果说自我反馈是“我认为我做得对不对”,那么外部反馈就是“事实证明我做得对不对”。
回到我们的 Jupyter Notebook 课程润色场景。假设课程中包含一些代码示例,我们希望在润色文案的同时,确保代码仍然能够正常运行。
这要求我们将上一章学习的工具使用 (Tool Use) 与反思机制结合起来。在这里,最直接的外部反馈来源,就是一个代码执行工具。AgentScope 内置了一个强大的 execute_python_code 工具,它为 Agent 提供了一个安全的代码解释器环境,使其能够真实地执行 Python 代码并获取结果或错误信息。
具体的工作流程如下:
- 生成:写作 Agent 润色文档,输出了包含代码的 notebook 内容。
- 与外部工具交互:系统自动提取出代码块,并调用
execute_python_code工具尝试执行它。 - 获取外部反馈:工具返回执行结果,假设遇到了错误:
TypeError: get_user_data() got an unexpected keyword argument 'usr_id'。 - 修正:Agent 接收到这份错误反馈,它现在明确地知道代码出现了什么问题。基于这份反馈,它会生成修正后的代码。

2.3.2.2 其他验证方法
除了代码执行,这种模式还能应用于其他需要客观事实的场景:
场景:优化科研论文中的 Matplotlib 图表
- 问题:你要求 Agent 为一篇科研论文生成数据可视化代码。Agent 生成了一段看起来"合理"的 Matplotlib 代码,包含了正确的数据处理逻辑和绘图函数调用。但代码能运行不代表图表效果好——实际渲染出来的图可能存在坐标轴标签重叠、图例遮挡数据点、字体过小难以辨认、配色不适合打印等问题。
- 外部反馈解法:系统调用代码解释器工具执行 Matplotlib 代码,并返回生成的图片文件。Agent 通过视觉输入接收到实际渲染的图表,能够直观地发现视觉问题(例如"x 轴标签重叠了"“图例挡住了关键数据点”),然后针对性地调整代码参数(如
plt.xticks(rotation=45)旋转标签、bbox_to_anchor调整图例位置、增大fontsize等)。这个"生成-渲染-调整"的循环,确保最终图表符合学术出版的质量要求。
场景:核对复杂计算题的答案
- 问题:在一节量子力学课程中,你需要出一道练习题:“计算一个电子(质量 ≈ 9.11e-31 kg)被限制在长度为 1 纳米(1e-9 m)的一维无限深势阱中时,其基态能量是多少焦耳?(普朗克常数 h ≈ 6.626e-34 J·s)” Agent 在解题步骤中可能由于复杂的指数运算而出错。
- 外部反馈解法:系统识别出需要计算的表达式
(1**2 * (6.626e-34)**2) / (8 * 9.11e-31 * (1e-9)**2),并将其交给代码解释器或计算器工具执行。工具返回精确的数值结果。这份客观的计算结果会作为反馈,让 Agent 修正最终的答案。
场景:结构化输出校验
- 问题:你要求 Agent 生成符合特定 JSON Schema 的配置文件,但它可能遗漏必填字段或使用错误的数据类型。
- 外部反馈解法:系统使用 Pydantic 等库对生成的 JSON 进行校验。当输出不符合 Schema 时,校验器返回详细的错误报告(如"字段 ’timeout’ 应为整数而非字符串")。这份客观、精准的反馈让 Agent 能够修正输出,直到完全符合预定义的结构。这个"生成-校验-反馈"的循环,是反思机制在实践中最常见、最基础的应用之一。
最后,如何选择这两种反馈模式呢?这取决于你的具体需求、预算和可接受的错误率。比如,如果只是润色一篇没有代码的博客文章,那么可能根本不需要反思。但如果是修改一份包含几十个代码示例的交互式课程,那么引入一个基于代码解释器的“外部反馈”循环,就是确保文档质量、避免发布事故的必要投资。
2.4 总结
让我们回顾一下你在本节学到的知识:
- 直接指令的局限性:直接在 Prompt 中要求大模型“更小心”或“不许改代码”通常效果不佳,因为模型以生成“更合理”的文本为目标,有时会“好心办坏事”。
- “反思”的核心思路:模仿人类的“元认知”,让模型有机会审视和评估自己已经生成的完整内容,从而发现并修正错误。这比简单的指令更可靠。
- 自我反馈 vs. 外部反馈:“自我反馈”是让另一个 Agent 检查初稿,适合主观评估;“外部反馈”是借助工具(如代码解释器)来验证结果,适合需要客观事实的场景。
- 工程实现:“生成-反馈”循环:实现“反思”的有效方法是采用多次调用:第一次生成初稿,后续调用则负责评估初稿、提供反馈,并基于反馈进行修改。
3 构建工作流
3.1 单个 Agent 处理复杂流程
周一早上,你收到了这样一条消息:
“上周五提交的《Python数据分析入门》课程需要尽快上线。能不能用你那个AI助手跑一遍标准审核流程?就是:1)所有代码示例要能运行 2)技术概念不能有硬伤 3)难度梯度适合零基础 4)语言风格符合我们的规范。下午3点前要结果。”
你心想,这个任务挺简单的。你的机器人已经能验证代码了,处理这个"组合任务"应该不难。于是你把所有要求塞进一个prompt里:
prompt = """请完成以下课程审核任务:
1. 验证所有Python代码能正确运行
2. 检查技术概念的准确性(特别是pandas和numpy的用法说明)
3. 评估难度曲线是否适合编程新手
4. 按照我们的风格指南调整用词(避免"很简单""超级"等口语)
请给出完整的审核报告。"""
response = agent.run(prompt + course_content)
几分钟后,你打开返回的结果:
- Agent确实验证了代码,但在"优化语言"时,它把代码里的
super()也改成了parent(),因为它觉得"super太口语化"。 - 它发现第 3 章对DataFrame的解释有误,改正后却引入了更严重的错误:说"DataFrame是Python内置的数据结构"。
- 至于难度评估?它在处理到第 50 个问题时似乎已经忘了这回事。
你试图让它重来,这次它记住了评估难度,却漏掉了一半的代码验证。第三次,它所有任务都做了,但把原本正确的概念"改错了"。
问题很明显:让单个Agent同时接管多个复杂任务,就像让一个实习生同时接四个电话——总有一个会出问题。
3.2 失败原因分析
3.2.1 注意力机制的遗忘效应
大语言模型在生成回复时,对不同位置信息的"注意力"是不均等的。当Agent处理到第四个任务(润色语言)时,第一个任务(代码验证)的细节已经被大量中间信息稀释。
具体表现:模型在后期修改时"忘记"了前期验证的约束。比如你已经验证super()是正确的Python语法,但在语言润色阶段,模型可能因为"super"这个词看起来口语化而将其替换,导致代码出错。
这不是简单的"记忆力差",而是Transformer架构中self-attention机制的固有限制——token之间的注意力权重会随着序列长度增加而被稀释。
3.2.2 错误的级联放大
在顺序执行多个任务时,早期的错误会成为后续处理的"事实基础"。假设Agent在事实检查阶段错误地"纠正"了DataFrame的定义(比如说它是Python内置的),这个错误会进入后续的上下文。
更糟的是,模型会基于这个错误的"事实"继续推理:
- 既然DataFrame是"内置的",那么就不需要import pandas
- 教学案例中就会删除导入语句
- 代码示例全部失效
这种错误传播不是线性的,而是指数级的——一个小错误会触发一连串的错误决策。
3.2.3 扁平化理解 vs 结构化需求
你的复杂需求其实是一个有内在结构的任务图:
- 有些任务可以并行(代码检查和风格检查互不干扰)
- 有些任务有依赖(必须先理解概念才能评估难度)
- 有些任务需要全局视角(评估整体难度曲线)
但对模型来说,你的prompt只是一个扁平的token序列。它无法自动识别出这种结构关系,而是试图用一个线性的生成过程去解决一个本质上是图结构的问题。
就像让某人同时玩四个不同规则的游戏,还不告诉他哪些可以轮流玩,哪些必须同时进行。
最终,依赖单个 Agent 执行复杂审阅,就像在没有施工蓝图的情况下建造一栋房子,每砌一块砖都可能影响整栋建筑的结构稳定。
3.3 工作流的几种模式
既然让一个 Agent 包办所有事情行不通,那你自然会想到另一种思路:就像你在管理一个项目时,你会把项目拆分成几个子任务,分配给不同的人或在不同时间点完成。这种“分而治之”(Divide and Conquer)的思想,正是解决此类问题的核心。
我们将这种把复杂任务拆解成多个节点,并定义它们之间执行关系的模式,称为工作流 (Workflow)。
构建工作流的关键,是理解业务并做出最合适的任务拆解。下面,我们将从最简单的模式开始,一步步构建出能够处理复杂课程审阅的强大工作流。
3.3.1 模式一:流水线 (Pipeline)
这是最基础、最直观的工作流。它将一个任务分解为多个固定的、按顺序执行的步骤。前一个步骤的输出,严格作为后一个步骤的输入,整个过程像工厂的流水线一样,单向且不可变。你在本课程早期构建的 RAG 问答机器人,就是这种模式的完美体现。

"""
模式一:流水线(Pipeline) - 场景:课程快速检查流程
目标:用户提交一篇课程初稿,系统按顺序完成
1) 提取课程中的代码 -> 2) 验证代码可执行性 -> 3) 生成代码检查报告
"""
import asyncio
from agentscope.message import Msg
from agentscope.pipeline import sequential_pipeline
from chatbot.agent import create_agent, disable_console_output
async def run_pipeline() -> None:
# 节点A:代码提取 Agent
# multi_agent=True 是 AgentScope 中的一个配置,用于确保 Agent 之间的通信格式兼容,
# 是构建工作流和多智能体系统的推荐设置。
code_extractor = create_agent(
name="代码提取器",
sys_prompt=(
"你是代码提取专家。请从用户提供的课程文本中,精确地提取出所有 Python 代码块。"
"只输出代码,不要有任何其他解释。"
),
model_name="qwen-flash",
multi_agent=True,
)
# 节点B:代码验证 Agent (可调用外部工具)
code_validator = create_agent(
name="代码验证器",
sys_prompt=(
"你是代码执行与验证专家。你将接收到代码文本。请使用代码解释器来执行它。"
"报告代码是否能成功运行,如果不能,请指出错误。"
),
# 此处可以配置 code_validator 使用你在第二节学过的代码解释器工具
model_name="qwen-plus",
multi_agent=True,
)
# 节点C:报告生成 Agent
report_generator = create_agent(
name="报告生成器",
sys_prompt=(
"你是审阅报告撰写助理。根据上一步的代码验证结果,为课程设计师生成一份简洁明了的检查报告。"
),
model_name="qwen-max",
multi_agent=True,
)
agents = [code_extractor, code_validator, report_generator]
disable_console_output(agents)
course_draft = (
"这是我们的新课程。第一部分是`print('Hello, World!')`。"
"第二部分是一个有问题的代码`x = 1 / 0`。"
)
result = await sequential_pipeline(
agents=agents,
msg=Msg("user", course_draft, "user"),
)
print("=" * 50)
print("流水线输出:")
print(result.content)
print("=" * 50)
async def main() -> None:
await run_pipeline()
await main()
它的核心优势在于简单、可预测且易于调试。因为流程是固定的,所以当出现问题时,你可以很容易地定位到是哪个环节(提取、验证还是报告)出了问题。这种确定性在许多企业级应用中至关重要。
它适用于业务流程非常固定、逻辑单一的任务。例如:
- 代码初步检查:先提取代码,再运行验证。
- 文档翻译:先提取文本,再进行翻译,最后格式化输出。
- 新员工入职材料分发:先生成欢迎邮件,再附上公司文档,最后发送。
流水线的刚性是它最大的优点,也是最致命的缺点。它无法处理流程之外的任何变化。面对“帮我评估一下这篇课程的趣味性”这样的请求,这条为“代码检查”设计的流水线会完全不知所措,因为它没有处理这种意图的能力。它假设所有输入都应遵循同一套处理逻辑。
3.3.2 模式二:分支选择 (Branching)
为了克服流水线的僵化,你需要引入决策能力。分支选择模式的核心是在工作流的开始或关键节点设置一个“路由器”或“调度中心”。这个决策节点会分析输入(例如,用户的审阅要求),然后像一个交通警察一样,将任务引导到不同的、预设好的处理路径(即不同的流水线或专家)上去。
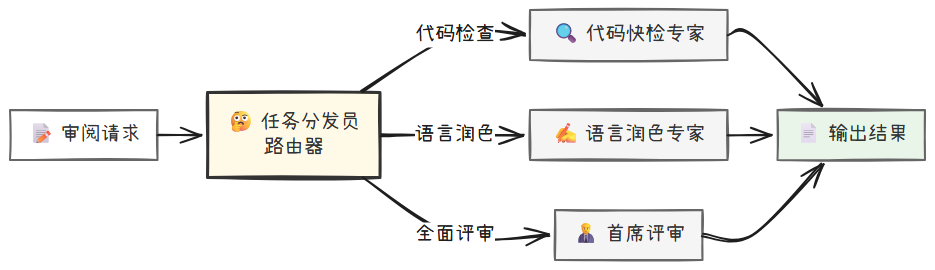
"""
模式二:分支选择(Branching) - 场景:课程审阅任务分发
路由 Agent 读取审阅请求,选择以下分支之一:
1) code_check: 仅快速检查代码
2) style_guide: 按风格指南润色语言
3) full_review: 进行全面的多维度评审
"""
import asyncio
from typing import Literal
from pydantic import BaseModel, Field
from agentscope.message import Msg
from chatbot.agent import create_agent, disable_console_output
class RouteChoice(BaseModel):
choice: Literal["code_check", "style_guide", "full_review", None] = Field(
description="根据用户意图选择分支:code_check/style_guide/full_review/None"
)
extra: str | None = Field(default=None, description="对任务的简要说明")
async def branch_code_check(user_msg: Msg) -> Msg:
agent = create_agent(
name="代码快检专家",
sys_prompt="你是代码快检专家。根据用户需求,快速验证课程中的代码片段是否能运行。",
model_name="qwen-plus",
multi_agent=True,
)
disable_console_output([agent])
return await agent(user_msg)
async def branch_style_guide(user_msg: Msg) -> Msg:
agent = create_agent(
name="语言润色专家",
sys_prompt="你是语言润色专家。请根据公司风格指南,改写和润色用户提供的课程文本。",
model_name="qwen-max",
multi_agent=True,
)
disable_console_output([agent])
return await agent(user_msg)
async def branch_full_review(user_msg: Msg) -> Msg:
agent = create_agent(
name="首席评审",
sys_prompt="你是首席评审。告知用户,你将启动一个包含代码、事实和教学法在内的全面评审流程。",
model_name="qwen-flash", # 使用轻量模型模拟启动流程的告知动作
multi_agent=True,
)
disable_console_output([agent])
return await agent(user_msg)
async def run_branching() -> None:
router = create_agent(
name="审阅任务分发员",
sys_prompt=(
"你是课程审阅任务的分发员,根据用户输入选择分支:\n"
"- 如果只是想检查代码,输出 code_check\n"
"- 如果是想润色文笔,输出 style_guide\n"
"- 如果是需要完整、全面的评审,输出 full_review\n"
"仅通过结构化输出来表达你的选择,不要正文回答。"
),
model_name="qwen-plus",
multi_agent=False,
)
user_text = "这篇课程写的差不多了,帮我全面检查一下,特别是代码和难度。"
res = await router(
Msg("user", user_text, "user"),
structured_model=RouteChoice,
)
choice = res.metadata.get("choice")
if choice == "code_check":
out = await branch_code_check(Msg("user", user_text, "user"))
elif choice == "style_guide":
out = await branch_style_guide(Msg("user", user_text, "user"))
elif choice == "full_review":
out = await branch_full_review(Msg("user", user_text, "user"))
else:
# 默认走全面评审,保证示例可运行
out = await branch_full_review(Msg("user", user_text, "user"))
print("=" * 50)
print(f"分支选择:{choice}")
print(out.content)
print("=" * 50)
async def main() -> None:
await run_branching()
await main()
与单一流水线相比,分支选择让系统变得更灵活、更智能。它使得一个应用能够处理多种不同类型的任务,极大地扩展了其适用范围,提升了用户体验。
常见的应用场景有:
- 智能客服:根据用户问题类型(课程内容咨询、平台技术支持、购买建议)转接到不同的处理流程。
- 多工具 Agent:Agent 根据任务需求,决定是调用代码解释器、搜索引擎还是内部知识库。
- 内容处理系统:根据内容类型(视频、文本、交互式 Notebook)调用不同的审核流程。
分支选择本质上是“多选一”,它依然是串行的。它能处理“代码检查”或“语言润色”,但无法处理“一边检查代码,一边润色语言”的复合请求。对于我们最初那个包含四个审核维度的复杂请求,它一次只能走一条分支,需要用户与机器人进行多次独立的对话才能完成,效率极低。
3.3.3 模式三:并行执行 (Parallel Execution)
当一个请求可以被分解为多个互不依赖的子任务时,让它们排队等待是极大的浪费。并行执行模式的核心思想是“同时进行”。它首先将一个复杂任务拆解成多个子任务,然后将这些子任务分发到不同的执行单元(Agent或工具)同时处理,最后再将所有结果汇集起来,形成最终的输出。
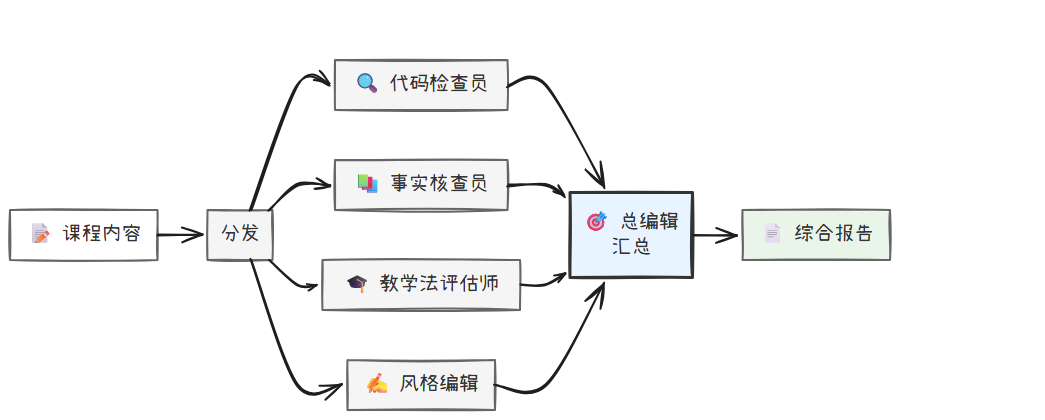
"""
模式三:并行执行(Parallel Execution) - 场景:课程完整审阅
将独立的审阅子任务并行执行:代码检查、事实核对、教学法评估、语言风格检查。
示例使用 fanout_pipeline 并行收集报告,再由合成 Agent 汇总。
"""
import asyncio
from typing import List
from agentscope.message import Msg
from agentscope.pipeline import fanout_pipeline
from chatbot.agent import create_agent, disable_console_output
async def run_parallel() -> None:
# 四个独立子任务的“专家”Agent
code_checker = create_agent(
name="代码检查员",
sys_prompt="验证课程中的代码是否正确无误,并给出修复建议。",
model_name="qwen-plus",
multi_agent=True,
)
fact_checker = create_agent(
name="事实核查员",
sys_prompt="核对课程中的技术概念、函数解释是否准确,引用是否规范。",
model_name="qwen-plus",
multi_agent=True,
)
pedagogy_evaluator = create_agent(
name="教学法评估师",
sys_prompt="评估课程的难度曲线、案例趣味性和练习有效性。",
model_name="qwen-flash",
multi_agent=True,
)
style_editor = create_agent(
name="风格编辑",
sys_prompt="根据公司风格指南,检查并报告语言风格、术语一致性问题。",
model_name="qwen-flash",
multi_agent=True,
)
experts = [code_checker, fact_checker, pedagogy_evaluator, style_editor]
disable_console_output(experts)
course_content = "这是我们新开发的 Python 数据分析入门课..."
msgs = await fanout_pipeline(
agents=experts,
msg=Msg("user", course_content, "user"),
enable_gather=True,
)
# 汇总 Agent
summarizer = create_agent(
name="总编辑",
sys_prompt="将来自多位专家的审阅意见汇总成一份结构清晰、条理分明的总审阅报告。",
model_name="qwen-max",
multi_agent=True,
)
disable_console_output([summarizer])
merged_text: List[str] = [m.content for m in msgs]
prompt = "\n\n".join(merged_text)
summary = await summarizer(Msg("user", prompt, "user"))
print("=" * 50)
print("并行执行输出:")
print(summary.content)
print("=" * 50)
async def main() -> None:
await run_parallel()
await main()
最显著的优势是效率的大幅提升。工作流的总耗时不再是所有子任务耗时之和,而是取决于耗时最长的那个子任务。这使得 Agent 能够快速响应包含多个步骤的复杂请求。
常见的应用场景有:
- 处理复杂审阅请求:如我们的课程审阅场景,同时处理代码、事实、教学法、风格等多个维度。
- 生成综合报告:同时从不同数据源(用户反馈、市场趋势、竞品分析)拉取信息,并分别进行分析,最后汇总成一份新课程立项报告。
- 批量数据处理:同时对多个课程单元执行相同的格式化或检查操作。
此模式的前提是子任务之间相互独立。如果任务之间存在依赖关系(例如,必须先确认课程的核心知识点,才能评估其案例是否贴切),则无法简单地并行。此外,它假设每个执行单元都能给出“正确”的答案,不适用于需要多方比较、权衡才能得出最佳方案的创造性或决策性任务。
3.3.4 模式四:混合专家 (Mixture-of-Agents, MoA)
与并行执行旨在提升效率不同,混合专家模式的核心目标是追求极致的质量、鲁棒性和创造性。MoA 的核心理念基于一个关键发现:不同的大语言模型具有各自独特的优势和专长,而当一个模型能够参考其他模型的输出时,往往能生成质量更高的响应——这种现象称为模型的"协作性"(Collaborativeness)。MoA 的做法是,让多个不同的大语言模型同时处理同一个任务,然后由一个聚合模型对所有输出进行综合、分析和融合,从而产生一个远超任何单个模型水平的最终结果。
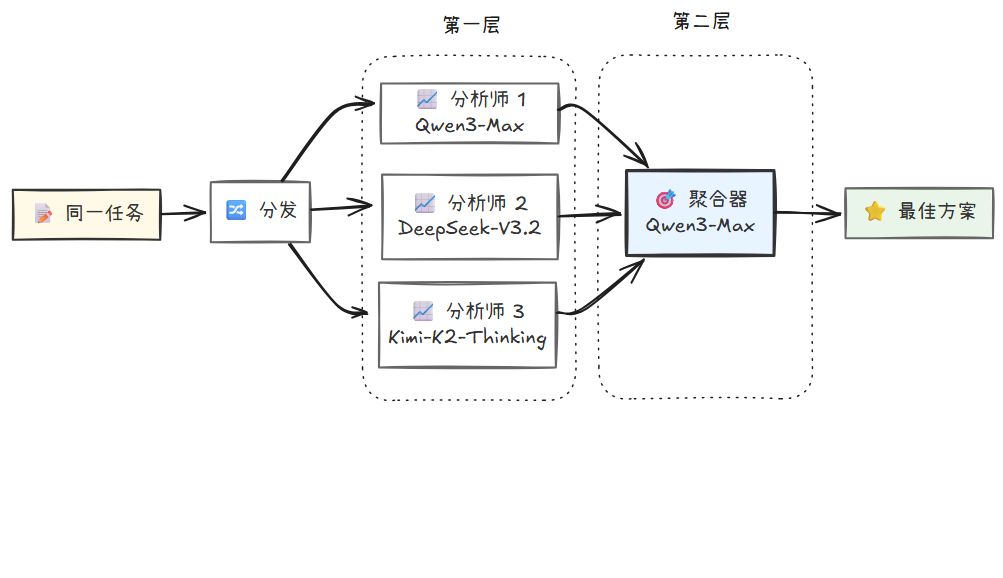
"""
模式四:混合专家(Mixture-of-Agents, MoA) - 场景:课程核心卖点提炼
使用三个不同的大语言模型并行处理同一任务,通过聚合模型融合它们的输出,
利用模型间的协作性(Collaborativeness)产生更高质量的结果。
"""
import asyncio
from agentscope.message import Msg
from agentscope.pipeline import fanout_pipeline
from chatbot.agent import create_agent, disable_console_output
async def run_moa() -> None:
# 使用三个不同的模型作为提议者(Proposer)
# 每个模型有其独特的优势,但处理相同的任务
proposer1 = create_agent(
name="Qwen3-Max",
sys_prompt="你是一个专业的课程分析师,请为给定的课程提炼核心卖点和宣传文案。",
model_name="qwen3-max",
multi_agent=True,
)
proposer2 = create_agent(
name="DeepSeek-V3.2",
sys_prompt="你是一个专业的课程分析师,请为给定的课程提炼核心卖点和宣传文案。",
model_name="deepseek-v3.2-exp",
multi_agent=True,
)
proposer3 = create_agent(
name="Kimi-K2",
sys_prompt="你是一个专业的课程分析师,请为给定的课程提炼核心卖点和宣传文案。",
model_name="kimi-k2-thinking",
multi_agent=True,
)
proposers = [proposer1, proposer2, proposer3]
disable_console_output(proposers)
task = (
"这是一门新的'面向Web开发者的AI大模型应用'课程,请为其提炼核心卖点和宣传文案。"
)
msgs = await fanout_pipeline(
agents=proposers,
msg=Msg("user", task, "user"),
enable_gather=True,
)
# 聚合器(Aggregator)接收所有模型的输出,综合产生最佳结果
aggregator = create_agent(
name="聚合器",
sys_prompt=(
"你的任务是综合多个大语言模型对同一问题的回答。"
"这些回答来自不同的模型,各有优劣。请批判性地评估这些回答,"
"识别其中的优点和不足,然后融合这些信息,生成一个高质量、准确、全面的最终回答。"
"确保你的回答结构清晰、逻辑连贯,并达到最高的准确性和可靠性标准。"
),
model_name="qwen3-max",
multi_agent=True,
)
disable_console_output([aggregator])
# 将所有提议者的输出合并,传递给聚合器
merged = "\n\n".join([
f"模型 {i+1} 的回答:\n{m.content}"
for i, m in enumerate(msgs)
])
final = await aggregator(Msg("user", merged, "user"))
print("=" * 50)
print("MoA 聚合输出:")
print(final.content)
print("=" * 50)
async def main() -> None:
await run_moa()
await main()
Mixture-of-Agents(MoA) 工作原理:
MoA 将参与的模型分为两类角色:
- 提议者(Proposers):多个不同的模型并行处理同一任务,各自生成响应。这些模型可能在某些方面表现出色(如逻辑推理、创意表达、事实准确性等)。
- 聚合器(Aggregator):接收所有提议者的输出,通过批判性评估、比较和融合,生成一个质量更高的最终响应。
关键的是,聚合器并非简单地选择最好的答案,而是能够从多个响应中提取各自的优点,综合产生一个超越任何单一模型的结果。
MoA 的优势:
- 利用模型多样性:不同模型有不同的训练数据、架构和优化目标,导致它们在不同任务上表现各异。MoA 能够同时利用多个模型的长处。
- 增强鲁棒性:即使某个模型在特定输入上表现不佳,其他模型的高质量输出也能保证最终结果的质量下限。
- 质量的涌现效应:研究表明,即使提议者模型的单独输出质量较低,聚合后的结果仍可能超越任何单一模型——这是"模型协作性"的直接体现。
MOA 适用于那些没有唯一标准答案、对结果质量要求极高、价值巨大的开放性或创造性任务。
- 核心文案撰写:如课程Slogan、推广文案、品牌故事。
- 复杂决策分析:综合不同模型的分析报告,形成更全面的新课程方向决策建议。
- 代码生成与优化:让不同模型生成一段示例代码,再由评审 Agent 择优或进行融合重构,以达到最佳的教学效果。
进阶:多层 MoA (Multi-Layer MoA)
前面展示的 MoA 是一个"2层结构":第一层有多个专家并行处理任务,第二层由一个聚合器综合所有专家的输出。然而,MoA 也可以扩展到 3 层或更多层,通过多轮迭代不断提炼和优化结果,从而获得比单层 MoA 更卓越的输出质量。
多层 MoA 的核心思想是:将上一层的聚合输出作为下一层的输入,再次交给多个专家进行审视、批判和改进,然后由新的聚合器进行更高层次的综合。这种"迭代提炼"的过程,类似于人类团队中的多轮评审和打磨,每一轮都能发现前一轮遗漏的问题,激发新的创意,最终达到单轮难以企及的质量水平。
多层 MoA 的优势:
- 质量的进一步提升:第二层、第三层的专家可以站在第一层结果的基础上,进行更深入的分析和优化,就像编辑团队对初稿进行多轮润色一样。
- 纠错能力增强:即使第一层的某些专家犯了错误,后续层次的专家有机会发现并纠正这些错误,使最终结果更加可靠。
- 创意的涌现:多层交互可能产生"1+1>2"的效果,不同层次专家的思想碰撞可能激发出任何单层都无法产生的创新方案。
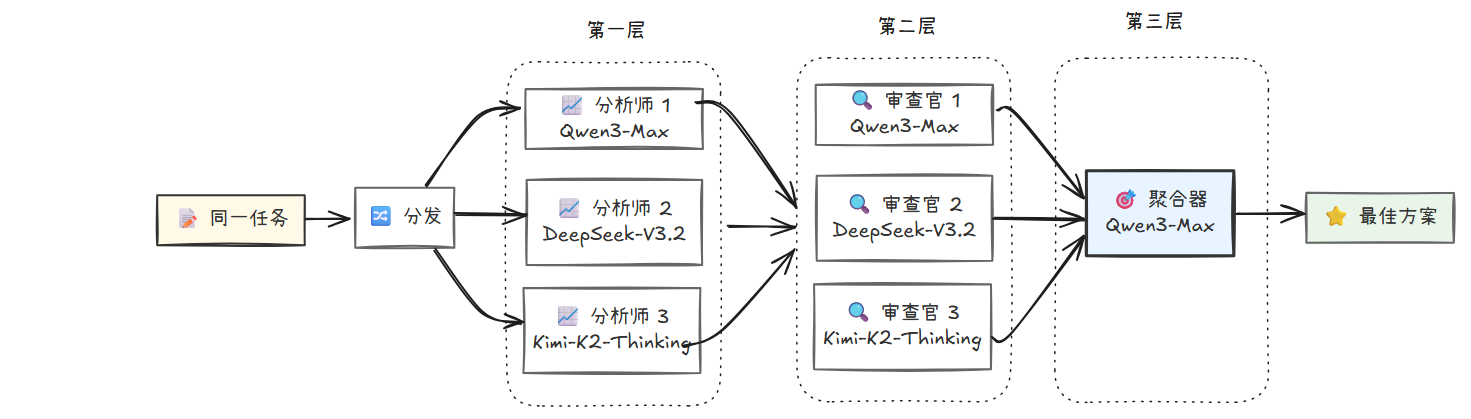
async def run_multi_layer_moa() -> None:
"""
多层 MoA 示例:3层架构提炼课程营销方案
Layer 1: 3个不同模型作为提议者并行生成方案
Layer 2: 3个不同模型对第一层的聚合输出进行优化和改进
Layer 3: 最终聚合器综合所有信息,输出最佳方案
"""
# 通用的聚合提示词
aggregate_prompt = (
"你的任务是综合多个大语言模型对同一问题的回答。"
"请批判性地评估这些回答,识别其中的优点和不足,"
"然后融合这些信息,生成一个高质量、准确、全面的最终回答。"
)
# Layer 1: 初始提议者层(3个不同模型)
layer1_proposers = [
create_agent(
name="Proposer-L1-1",
sys_prompt="你是一个专业的课程分析师,请为给定的课程提炼核心卖点和宣传文案。",
model_name="qwen3-max",
multi_agent=True
),
create_agent(
name="Proposer-L1-2",
sys_prompt="你是一个专业的课程分析师,请为给定的课程提炼核心卖点和宣传文案。",
model_name="deepseek-v3.2-exp",
multi_agent=True
),
create_agent(
name="Proposer-L1-3",
sys_prompt="你是一个专业的课程分析师,请为给定的课程提炼核心卖点和宣传文案。",
model_name="kimi-k2-thinking",
multi_agent=True
),
]
task = "这是一门新的'面向Web开发者的AI大模型应用'课程,请为其提炼核心卖点和宣传文案。"
layer1_outputs = await fanout_pipeline(
agents=layer1_proposers,
msg=Msg("user", task, "user"),
enable_gather=True,
)
# Layer 1 聚合器
layer1_aggregator = create_agent(
name="Aggregator-L1",
sys_prompt=aggregate_prompt,
model_name="qwen3-max",
multi_agent=True,
)
layer1_merged = "\n\n".join([f"模型 {i+1}:\n{m.content}" for i, m in enumerate(layer1_outputs)])
layer1_result = await layer1_aggregator(Msg("user", layer1_merged, "user"))
# Layer 2: 第二轮提议者层(3个不同模型,基于第一层的聚合结果进行优化)
layer2_proposers = [
create_agent(
name="Proposer-L2-1",
sys_prompt="你是一个专业的课程分析师。请审视给定的营销方案,并提出改进建议或优化版本。",
model_name="qwen3-max",
multi_agent=True
),
create_agent(
name="Proposer-L2-2",
sys_prompt="你是一个专业的课程分析师。请审视给定的营销方案,并提出改进建议或优化版本。",
model_name="deepseek-v3.2-exp",
multi_agent=True
),
create_agent(
name="Proposer-L2-3",
sys_prompt="你是一个专业的课程分析师。请审视给定的营销方案,并提出改进建议或优化版本。",
model_name="kimi-k2-thinking",
multi_agent=True
),
]
layer2_prompt = f"以下是第一轮分析生成的营销方案:\n\n{layer1_result.content}\n\n请在此基础上提出改进建议或优化版本。"
layer2_outputs = await fanout_pipeline(
agents=layer2_proposers,
msg=Msg("user", layer2_prompt, "user"),
enable_gather=True,
)
# Layer 3: 最终聚合层
final_aggregator = create_agent(
name="Final-Aggregator",
sys_prompt=aggregate_prompt,
model_name="qwen3-max",
multi_agent=True,
)
layer2_merged = "\n\n".join([f"模型 {i+1}:\n{m.content}" for i, m in enumerate(layer2_outputs)])
final_output = await final_aggregator(Msg("user", layer2_merged, "user"))
print("多层 MoA 最终输出:")
print(final_output.content)
await run_multi_layer_moa()
何时使用多层 MoA:
- 极高价值任务:如公司年度战略报告、重要产品发布文案、核心课程体系设计等,这些任务的成败可能直接影响业务结果,值得投入更多资源。
- 创造性要求极高:如品牌故事创作、教学方法创新设计等,需要多轮思想碰撞才能激发出最佳创意的场景。
- 容错要求极高:如法律文书、技术白皮书等,任何错误都可能带来严重后果,需要多层审核来确保准确性。
成本权衡:
多层 MoA 的成本随层数线性增长。以上面的 3 层架构为例:每层 3 个提议者模型 + 1 个聚合器,意味着至少调用 (3+1) + (3+1) + 1 = 9 次模型,相比单层的 3+1=4 次,成本增加了一倍多。因此,只有在任务的价值明显高于成本时,才应考虑使用多层 MoA。
你可以通过以下策略来平衡成本和质量:
- 减少提议者数量:第一层使用 3-4 个不同模型以获得多样性,后续层可以减少到 2-3 个模型进行精炼。
- 减少层数:对于大多数任务,2 层 MoA(提议者层 + 聚合层)已经能带来显著的质量提升,3 层或更多层通常只在极高价值任务中才值得使用。
- 混合模型配置:在提议者中混合使用不同性能和成本的模型,而聚合器使用质量最高的模型以确保最终输出的质量。
何时使用多层 MoA:
- 极高价值任务:如公司年度战略报告、重要产品发布文案、核心课程体系设计等,这些任务的成败可能直接影响业务结果,值得投入更多资源。
- 创造性要求极高:如品牌故事创作、教学方法创新设计等,需要多轮思想碰撞才能激发出最佳创意的场景。
- 容错要求极高:如法律文书、技术白皮书等,任何错误都可能带来严重后果,需要多层审核来确保准确性。
成本权衡:
多层 MoA 的成本随层数线性增长。以上面的 3 层架构为例:每层 3 个提议者模型 + 1 个聚合器,意味着至少调用 (3+1) + (3+1) + 1 = 9 次模型,相比单层的 3+1=4 次,成本增加了一倍多。因此,只有在任务的价值明显高于成本时,才应考虑使用多层 MoA。
你可以通过以下策略来平衡成本和质量:
- 减少提议者数量:第一层使用 3-4 个不同模型以获得多样性,后续层可以减少到 2-3 个模型进行精炼。
- 减少层数:对于大多数任务,2 层 MoA(提议者层 + 聚合层)已经能带来显著的质量提升,3 层或更多层通常只在极高价值任务中才值得使用。
- 混合模型配置:在提议者中混合使用不同性能和成本的模型,而聚合器使用质量最高的模型以确保最终输出的质量。
扩展阅读:工作流的成本优化与资源管理
你已经意识到,像混合专家(MoA)这样的高级模式会带来显著的成本增加。这引出了一个在将任何工作流投入生产前都必须面对的关键问题:如何管理资源和优化成本?幸运的是,你可以通过一系列精细化的工程策略,在不牺牲过多质量的前提下,显著降低工作流的运行成本。
- 差异化模型分配:工作流中的不同节点,其任务复杂度和重要性天差地别。你可以为简单的任务(如意图识别、格式转换)分配轻量、廉价的模型,而只为最关键的核心任务(如最终决策、文案生成)保留昂贵的高级模型。研究表明,通过合理的优化策略,根据具体实施情况,企业可以节省 40-70% 的 Token 成本。
- 系统性缓存:仔细观察你的工作流,你会发现许多节点的计算是可重复的。例如,对同一份公司风格指南的检索、对同一篇课程的审阅请求解析等。通过为这些节点增加缓存机制,你可以存储中间结果。当下次遇到相同的输入时,系统可以直接返回缓存的结果,完全绕过模型调用,从而大幅降低成本和延迟。
- 智能批处理 (Batching):并非所有任务都需要立即响应。对于课程质量报告生成、用户反馈分析等非实时性任务,你可以设计工作流来智能地聚合一批相似的请求,然后通过一次模型调用进行“批量处理”,而不是为每个请求都单独调用一次。这能在成本和响应时间之间找到一个更优的平衡点。
3.3.5 模式五:人机协作 (Human-in-the-Loop, HITL)
至此,你设计的所有工作流都是全自动的。然而,在现实世界中,将所有决策权完全交给 AI 存在风险,尤其是在处理模糊不清的教学概念或高价值的课程内容时。人机协作模式不再追求完全的自动化,而是有意地在工作流中设计一个或多个“暂停节点”,将控制权交还给人类,由人类进行决策、审批或质量把关后,再将任务交还给工作流继续执行。这是一种构建可信、安全 AI 系统的关键模式。
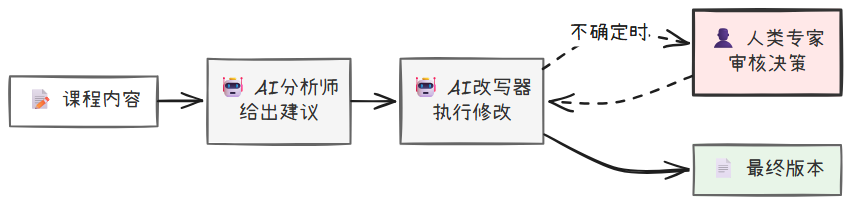
"""
模式五:人机协作(HITL) - 场景:课程疑难点审核(Human as a Tool)
AI 先对课程中的一个潜在疑难点给出修改建议;随后由具备“人类咨询”工具的改写 Agent 自主决定何时调用该工具向人类请示,最终完成修改。
"""
import asyncio
import os
from agentscope.agent import ReActAgent, UserAgent
from agentscope.message import Msg, TextBlock
from agentscope.model import DashScopeChatModel
from agentscope.formatter import DashScopeMultiAgentFormatter
from agentscope.tool import Toolkit, ToolResponse
from chatbot.agent import create_agent, disable_console_output
# 将人类介入封装为一个工具:ask_human_decision
async def ask_human_decision(question: str) -> ToolResponse:
"""向人类专家征求决策或意见。
Args:
question (str): 想要请人类确认或补充的具体问题。
"""
human_expert = UserAgent(name="教学专家")
reply = await human_expert(
Msg(
"assistant",
question,
"assistant",
)
)
return ToolResponse(
content=[
TextBlock(type="text", text=reply.get_text_content()),
]
)
async def run_hitl() -> None:
# AI:给出修改建议
suggester = create_agent(
name="疑难点分析师",
sys_prompt=(
"你是一名资深教学设计师。请找出课程中对初学者可能最难理解的一个概念,"
"并提供一个更通俗易懂的解释作为修改建议。"
),
model_name="qwen-plus",
multi_agent=True,
)
disable_console_output([suggester])
course_content = "在Python中,装饰器本质上是一个接收函数作为参数并返回一个新函数的函数..."
suggestion = await suggester(Msg("user", course_content, "user"))
print("AI 建议如下:\n")
print(suggestion.content)
# 将“人类介入”作为工具交给改写 Agent,自主决定是否调用
toolkit = Toolkit()
toolkit.register_tool_function(ask_human_decision)
rewriter = ReActAgent(
name="内容改写器",
sys_prompt=(
"你是课程内容改写器。基于提供的 AI 建议完成最终修改。\n"
"- 若你有把握,请直接完成修改并给出确认信息;\n"
"- 若存在不确定、歧义或高风险,请调用工具 ask_human_decision 先向人类专家请示,"
"再据此完成修改;\n"
"- 在最终结果中简要说明是否咨询了人类及原因。"
),
model=DashScopeChatModel(
model_name="qwen-max",
api_key=os.environ.get("DASHSCOPE_API_KEY", "your-api-key"),
stream=False,
),
formatter=DashScopeMultiAgentFormatter(),
toolkit=toolkit,
)
disable_console_output([rewriter])
# 将课程内容与 AI 建议一并提供给改写 Agent
task = (
"下面是课程摘录与 AI 的修改建议。根据系统提示完成最终修改:\n\n"
f"[课程内容]\n{course_content}\n\n"
f"[AI 建议]\n{suggestion.get_text_content()}\n"
)
final_action = await rewriter(Msg("user", task, "user"))
print("=" * 50)
print("HITL 最终输出:")
print(final_action.content)
print("=" * 50)
async def main() -> None:
await run_hitl()
await main()
人类介入工作流的优势在于:
- 提升准确性:通过引入人类的常识和领域知识来处理 AI 难以判断的教学模糊性(如一个比喻是否恰当),确保最终内容的正确性。
- 增强安全性:对于直接发布课程、修改核心代码库等高风险操作,人类的最终审批是防止 AI 误操作导致严重后果的最后一道防线。
- 建立信任:让课程设计师参与到 AI 的审阅和修改过程中,使其对系统的行为有更强的控制感和信任感。
常见的应用场景有:
- 处理模糊需求:当需求不明确时(如“让课程更有趣”),由 AI 提供多个教学设计方案,人类做出选择。
- 高价值操作审批:在执行任何涉及课程内容发布、删除旧版本等操作前,必须由课程负责人进行审批。
- 关键产出质量审核:在“混合专家”生成一份重要的课程大纲初稿后,工作流的最后一步应是将其发送给教学总监进行最终审核,而不是直接投入开发。
引入人类会显著降低工作流的自动化程度和执行速度。因此,它不适用于追求高吞吐量和毫秒级响应的全自动化场景。HITL 节点的设计需要精心考虑,只在绝对必要的环节介入,避免过多的人工干预拖慢整个流程。
扩展阅读:生产级框架
你无需从零开始实现这些复杂的模式。业界已经有成熟的框架来帮助你构建和管理 Agent 工作流,也内置了异常处理和状态管理工具。
- 代码框架:AgentScope、LangGraph 等库允许你用 Python 代码灵活地定义节点和边,构建任意复杂的图结构工作流,提供了最高的定制化能力。
- 可视化编排平台:阿里云百炼、Dify 等低代码/无代码平台,允许你通过拖拽组件、连接线条的方式,像绘制流程图一样构建工作流。这极大地降低了开发门槛,适合快速原型验证和业务流程相对固定的场景。
3.3.6 选择合适的模式
你已经了解了五种功能各异的工作流模式。一个很自然的问题是:在面对一个具体的业务问题时,我应该如何选择,甚至组合这些模式呢?
记住一个核心原则:没有“最好”的模式,只有“最适合”的模式。你的选择应该由任务的内在属性决定,例如任务的复杂度、子任务间的依赖关系、对成本和效率的要求,以及对结果质量和风险的容忍度。
3.4 总结
让我们回顾一下你在本节学到的知识:
- 单一 Agent 的局限性:面对包含多个步骤的复杂任务,单个 Agent 难以维持稳定的执行计划,容易因“注意力涣散”或“错误累积”而导致任务失败。
- 工作流的核心思想:借鉴“分而治之”的理念,将复杂任务拆解为多个独立的、可管理的节点,并定义它们之间的执行关系,从而确保流程的可靠性。
- 五种核心编排模式:你学习了流水线、分支选择、并行执行、混合专家和人机协作这五种模式,它们分别用于处理固定流程、多选一决策、并行提效、追求质量和引入人工审核的场景。
4 从固定流程到自主规划
4.1 固定工作流的局限性
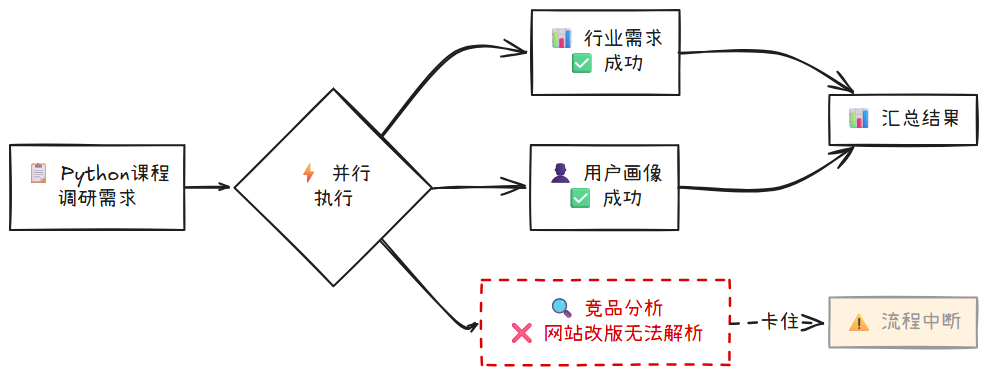
在上一章,你学习了如何为重复性工作构建固定的工作流。假设你为公司开发了一个“课程前期调研”机器人,它有一个固定的流程:当收到调研需求时,并行分析用户画像、竞品课程和行业需求。
现在,一位课程设计师向机器人发出了指令:“请帮我完成一门新的 Python 入门课程的前期调研。”
机器人忠实地启动了你预设的工作流:
- 行业需求分析子任务:调用工具,成功。
- 用户画像定义子任务:调用工具,成功。
- 竞品课程分析子任务:调用
analyze_competitor_course工具,却收到了一个错误:“错误:因竞品网站布局更新,无法解析课程大纲。”
这时,你的机器人将无法继续执行。因为它被设计的流程里,没有处理“竞品分析工具失效”这个意外情况的步骤。
4.2 朴素解法:增加新的分支
你会想,只要为工作流添加异常处理分支就可以了。你可以在原有的固定流程里增加一个分支:如果analyze_competitor_course失败,那就执行一个新的步骤,比如提醒课程设计师人工处理。
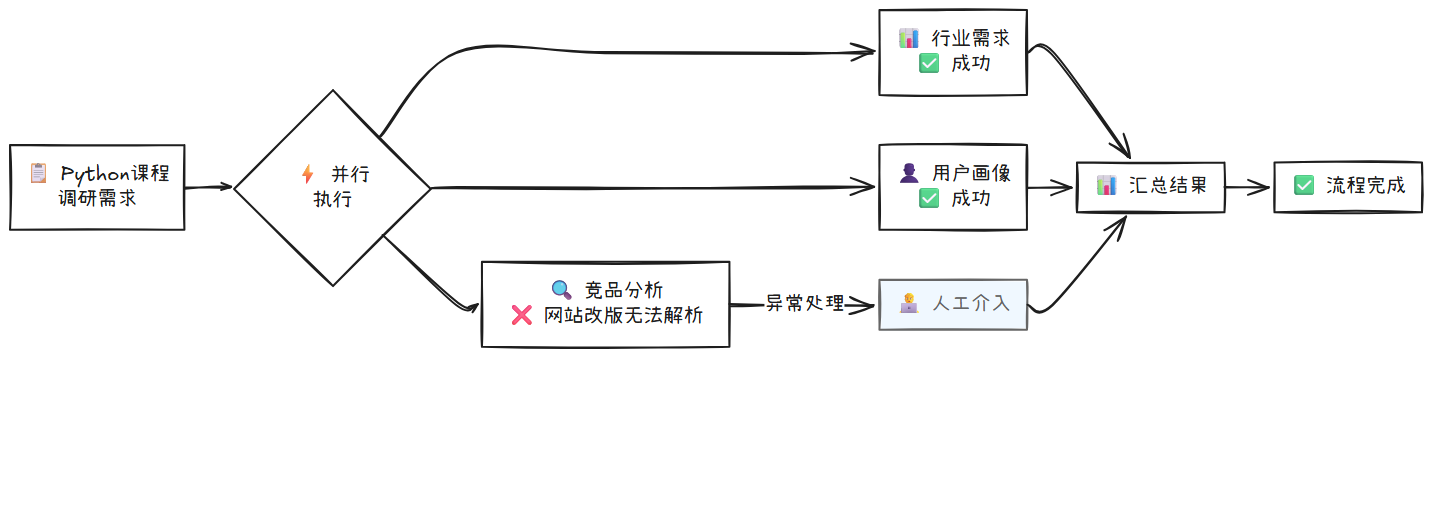
这种“打补丁”的方案看似有效,但如果下一次是行业需求分析的API接口临时维护失败了呢?你是不是又要加一个新的分支?如果定义用户画像时,需要的数据源格式变更了呢?还要再加一个分支吗?
你会发现,你永远无法预知所有可能的意外。试图为每一种异常都预设一个处理流程,会让你的工作流变得无比复杂和臃肿,难以维护。更重要的是,一旦出现你没有预料到的新问题,整个系统依然会“卡住”。
根本原因在于,这个 Agent 只是一个流程的忠实执行者,而不是一个问题的解决者。它并不“理解”用户的最终目标是“完成课程前期调研”,它只知道要严格按照你画好的流程图一步步往下走。当其中一条路被堵死时,它不知道如何像人一样,为了达成最终目标而主动寻找别的路。
扩展阅读:目标 (Goal) vs. 任务 (Task)
理解“目标”和“任务”的区别,是理解 Agent 自主规划能力的关键。
- 目标 (Goal):是用户希望达成的最终状态。它是高层次的、有时甚至是模糊的。例如:“帮我完成Python入门课程的调研”。
- 任务 (Task):是为了达成目标而需要执行的具体、明确的动作。例如:“调用
analyze_competitor_course工具,参数为 {url: ‘some-site.com’ }”。一个只有固定工作流的 Agent,它处理的是“任务”。当任务执行失败时,它无能为力。而一个更智能的 Agent,应该能聚焦于用户的“目标”。当一个具体的任务失败时,它应该能意识到这只是达成目标的一条路走不通了,然后主动规划出新的任务来继续逼近目标。
4.3 让 Agent 学会自主规划任务
这个过程启发了我们:能否将这种“规划”的权力也赋予 Agent,让它在面对未知挑战时,能自主地设计和调整自己的工作流?
这正是业界解决此类问题的核心理论:规划 (Planning)。
引入规划能力后,Agent 的工作模式发生了根本性转变。开发者的角色从“流程设计师”转变为“目标设定者”与“能力(工具)提供者”,而 Agent 则从“任务执行者”升级为“解决方案规划师”。
它的工作流程变成了这样:
- 接收目标:Agent 接收一个高阶的用户目标(例如:“完成Python课程的前期调研”)。
- 动态规划:Agent 的“大脑”(LLM)首先进行思考,将目标分解,动态地生成一份包含多个步骤的行动计划 (Plan)。
- 执行计划:一个执行程序接收这份计划,然后像执行一份普通工作流一样,按顺序调用工具,完成每个步骤。

在这个新模式下,“计划”本身成了一种可被生成和执行的数据。大模型不再是流程中的一个固定环节,而是流程的创造者。
为了让你更直观地理解 Agent 的自主规划能力,我们提供了一个基于 AgentScope 框架的完整示例。这个示例模拟了文章开头的场景:当竞品分析工具失效时,Agent 如何自主规划并找到解决方案。
"""AgentScope - Agent自主规划与执行示例(简化版)"""
import asyncio
import os
from agentscope.agent import ReActAgent
from agentscope.formatter import DashScopeChatFormatter
from agentscope.message import Msg, TextBlock
from agentscope.model import DashScopeChatModel
from agentscope.tool import Toolkit, ToolResponse
from agentscope.plan import PlanNotebook
# 模拟业务工具
async def analyze_competitor_course(url: str) -> ToolResponse:
"""分析竞品课程页面的大纲"""
# 模拟因网站改版导致解析失败
return ToolResponse(content=[
TextBlock(type="text", text=f"❌ 错误:因 {url} 网站布局更新,无法解析课程大纲。")
])
async def search_industry_demand(topic: str) -> ToolResponse:
"""查询行业的技能需求"""
return ToolResponse(content=[
TextBlock(type="text", text=f"✅ 报告:关于“{topic}”的行业需求分析已完成。")
])
async def google_search(query: str) -> ToolResponse:
"""谷歌网页搜索"""
if "syllabus" in query:
return ToolResponse(content=[
TextBlock(type="text", text="搜索结果:找到了'Python入门课程'的大纲PDF,地址 a.com/syllabus.pdf")
])
return ToolResponse(content=[TextBlock(type="text", text="未找到相关信息")])
async def extract_text_from_pdf(url: str) -> ToolResponse:
"""从PDF链接中提取文本"""
return ToolResponse(content=[
TextBlock(type="text", text=f"✅ 已从 {url} 提取大纲文本:1. 变量与数据类型... 2. ...")
])
# 用于监控计划变化的钩子函数
plan_snapshots = []
def capture_plan_snapshot(notebook, plan):
"""捕获计划快照"""
if plan:
plan_snapshots.append({
"name": plan.name,
"description": plan.description,
"state": plan.state,
"subtasks": [
{
"name": st.name,
"state": st.state,
"outcome": st.outcome
}
for st in plan.subtasks
]
})
async def main():
print("=" * 60)
print("🤖 Agent自主规划演示")
print("=" * 60)
# 创建PlanNotebook并注册钩子
plan_notebook = PlanNotebook()
plan_notebook.register_plan_change_hook("capture", capture_plan_snapshot)
# 创建工具箱
toolkit = Toolkit()
toolkit.register_tool_function(analyze_competitor_course)
toolkit.register_tool_function(search_industry_demand)
toolkit.register_tool_function(google_search)
toolkit.register_tool_function(extract_text_from_pdf)
# 创建Agent
agent = ReActAgent(
name="CourseResearcherAgent",
sys_prompt=(
"你是课程调研助手。遇到复杂任务时:\n"
"1. 用create_plan创建计划\n"
"2. 逐步执行,用finish_subtask标记完成\n"
"3. 遇到问题灵活调整,例如使用google_search寻找替代方案\n"
"4. 完成后用finish_plan结束"
),
model=DashScopeChatModel(
model_name="qwen-max",
api_key=os.environ.get("DASHSCOPE_API_KEY"),
),
formatter=DashScopeChatFormatter(),
toolkit=toolkit,
plan_notebook=plan_notebook,
)
# 用户请求
print("\n💬 用户: 请帮我完成一门新的 Python 入门课程的前期调研。\n")
print("-" * 60)
await agent(Msg("user", "请帮我完成一门新的 Python 入门课程的前期调研,竞品是 some-site.com 的课程。", "user"))
# 显示结果(从快照中获取最后的完整计划)
print("\n" + "=" * 60)
print("📊 执行结果")
print("=" * 60)
if plan_snapshots:
final_plan = plan_snapshots[-1]
finished = sum(1 for st in final_plan["subtasks"] if st["state"] == "finished")
print(f"\n✅ 计划: {final_plan['name']}")
print(f"📊 进度: {finished}/{len(final_plan['subtasks'])}")
print(f"🎯 状态: {final_plan['state']}\n")
print("子任务详情:")
for i, subtask in enumerate(final_plan["subtasks"], 1):
icon = "✅" if subtask["state"] == "finished" else "⏳"
print(f" {icon} {i}. {subtask['name']}")
await main()
通过这个示例,你可以看到:
- 自主创建计划:Agent 使用
create_plan工具自动规划调研任务。 - 灵活执行:遇到竞品分析工具失效时,Agent 自动调整策略,转而使用
google_search。 - 进度追踪:使用
finish_subtask标记完成的任务。 - 完整闭环:从规划创建到任务完成的全流程。
这正是 PlanNotebook 为 Agent 带来的核心能力:将其从"流程执行者"提升为"问题解决者"。
扩展阅读:生产级框架
像 AgentScope 和 LangChain 这样的开源框架,都提供了实现这种“规划-执行”循环的机制。它们允许你定义一系列工具,然后让大模型作为规划器 (Planner) 来决定在每一步应该调用哪个工具,并将工具返回的结果作为后续思考的输入,从而实现复杂的任务拆解和执行。
4.4 执行 Agent 生成的规划
那么,如何让大模型生成一份机器可以理解和执行的“计划”呢?
最简单的方式,是让它生成自然语言的步骤列表。但这样做,下游的执行程序很难精确解析。你之前在让 Agent 调用工具时学过,可以使用结构化的 JSON 格式 输出工具调用参数。这里,你也可以把“执行计划”看作调用工具。每一个步骤都是一个定义清晰的对象,包含要调用的工具名和对应的参数。
{
"plan": [
{
"step": 1,
"thought": "我首先需要分析行业需求,这是课程定位的关键。",
"tool_name": "search_industry_demand",
"tool_params": {"topic": "Python 基础"}
},
{
"step": 2,
"thought": "接下来,我尝试分析竞品课程的大纲。",
"tool_name": "analyze_competitor_course",
"tool_params": {"url": "some-site.com/python-course"}
}
]
}
这是一种有效的方法,但它的表达能力有限。如果计划中需要包含“如果竞品分析失败,则改用谷歌搜索”这样的条件逻辑,简单的 JSON 列表就难以胜任了。
为了表达更复杂的逻辑,你可以让大模型直接生成代码 (Code as Action) 来表达其计划,再通过调用“代码解释器”这个工具来执行代码。
# Plan generated by LLM
def execute_research_plan():
# Step 1: Analyze industry demand
demand_result = search_industry_demand(topic="Python 基础")
print(demand_result)
# Step 2: Analyze competitor course
competitor_result = analyze_competitor_course(url="some-site.com/python-course")
# Step 3: Handle analysis failure
if not competitor_result.success and "无法解析" in competitor_result.message:
print("竞品分析工具失效,正在寻找备选方案...")
search_results = google_search(query="some-site.com python course syllabus")
# Assume search_results gives a PDF link
pdf_url = extract_pdf_link(search_results)
if pdf_url:
syllabus_text = extract_text_from_pdf(url=pdf_url)
print(syllabus_text)
else:
print(competitor_result)
execute_research_plan()
通过生成代码,大模型可以利用编程语言内置的丰富能力(如变量、条件判断、循环)和强大的第三方库(如 Pandas)来制定和执行极其复杂的计划。这使得 Agent 不仅能应对简单的线性流程,还能处理包含逻辑判断和数据处理的复杂场景。
4.5 进阶:让 Agent 创建新工具
你已经掌握了让大模型通过生成代码来制定计划的强大方法。这种方式赋予了 Agent 运用变量、条件判断和循环等复杂逻辑的能力。
但这里还有一个潜在的瓶颈:Agent 仍然受限于你预先提供给它的工具集。如果它在执行计划时,发现需要一个你并未提供的新工具,比如一个用于计算不同技术关键词在招聘网站上出现频率的函数,它该怎么办?
最直接的办法是让 Agent 停下来,请求你(开发者)为它编写这个新工具。但这中断了任务的自主流程。让我们更进一步思考:既然 Agent 已经能够生成用于规划的代码,它是否也能生成用于创造新能力的代码呢?
这便引出了一种更高级的规划能力:动态创造工具 (Dynamic Tool Creation)。
要实现这一点,你需要在提供具体业务工具(如 analyze_competitor_course)之外,再为 Agent 提供一个核心的“元工具”:代码执行环境 (Code Interpreter)。
当 Agent 识别到现有工具无法满足需求时,它的规划会包含一系列特殊的步骤:
当 Agent 识别到现有工具无法满足需求时,它的规划会包含一系列特殊的步骤:
- 决策:大模型分析任务,识别出需要一个当前不存在的新工具。
- 生成代码:在它的计划中,它会编写一段代码来定义、测试并封装一个新的工具函数。
- 调用新工具:在新工具于代码执行环境中被成功创建后,Agent 可以在后续的计划步骤中直接调用它,就好像这个工具一开始就存在一样。
- 扩展工具库:这个新生成的工具可以被加入到本次任务的临时工具库中,供后续步骤复用。
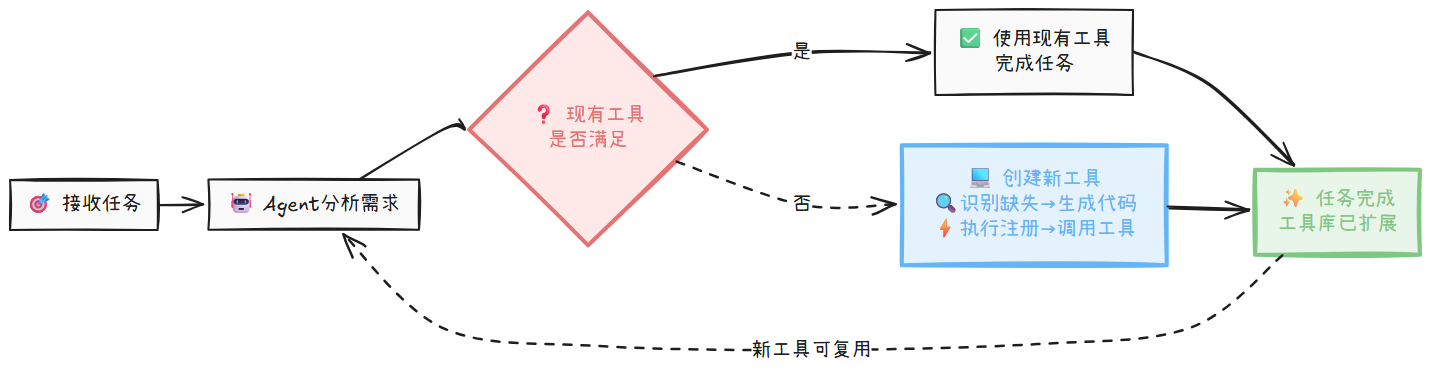
下面是使用 AgentScope 构建的一个简单示例,Agent 可以在规划过程中,基于已有的 add 工具,自主创建并注册一个 factorial(阶乘)工具,并在后续任务中调用它。
"""AgentScope Agent自主创建工具 - 精简版"""
import asyncio
import os
import sys
from io import StringIO
from agentscope.agent import ReActAgent
from agentscope.formatter import DashScopeChatFormatter
from agentscope.memory import InMemoryMemory
from agentscope.message import Msg, TextBlock
from agentscope.model import DashScopeChatModel
from agentscope.tool import Toolkit, ToolResponse
# 全局工具箱
toolkit = None
async def code_exec(code: str) -> ToolResponse:
"""代码解释器 - 用于创建和注册新工具"""
global toolkit
namespace = {
'ToolResponse': ToolResponse,
'TextBlock': TextBlock,
'asyncio': asyncio,
'agent_toolkit': toolkit,
'math': __import__('math'),
}
stdout, sys.stdout = sys.stdout, StringIO()
try:
exec(code, namespace)
output = sys.stdout.getvalue()
sys.stdout = stdout
return ToolResponse(content=[TextBlock(
type="text",
text=output or "✅ 执行成功"
)])
except Exception as e:
sys.stdout = stdout
return ToolResponse(content=[TextBlock(
type="text",
text=f"❌ 错误: {e}"
)])
async def add(a: float, b: float) -> ToolResponse:
"""加法工具"""
return ToolResponse(content=[TextBlock(
type="text",
text=f"{a} + {b} = {a + b}"
)])
async def main():
if "DASHSCOPE_API_KEY" not in os.environ:
print("❌ 请设置 DASHSCOPE_API_KEY")
return
global toolkit
toolkit = Toolkit()
toolkit.register_tool_function(add)
toolkit.register_tool_function(code_exec)
agent = ReActAgent(
name="ToolMaker",
sys_prompt=(
"你可以通过 code_exec 创建新工具。\n"
"模板:\n"
"async def tool_name(param: type) -> ToolResponse:\n"
" '''描述'''\n"
" result = ...\n"
" return ToolResponse(content=[TextBlock(type='text', text=f'{result}')])\n"
"agent_toolkit.register_tool_function(tool_name)\n"
"print('✅ 已注册 tool_name')"
),
model=DashScopeChatModel(
model_name="qwen-plus",
api_key=os.environ.get("DASHSCOPE_API_KEY"),
),
formatter=DashScopeChatFormatter(),
toolkit=toolkit,
memory=InMemoryMemory(),
)
print("=" * 60)
print("🚀 Agent 自主创建工具演示")
print("=" * 60)
# 使用现有工具
print("\n▶️ 场景1: 使用现有工具")
await agent(Msg("user", "计算 30 + 45", "user"))
# 创建新工具
print("\n▶️ 场景2: 创建阶乘工具")
await agent(Msg("user", "创建 factorial 工具计算阶乘", "user"))
# 使用新工具
print("\n▶️ 场景3: 使用新工具")
await agent(Msg("user", "用 factorial 计算 5 的阶乘", "user"))
# 显示工具箱
print("\n📦 最终工具箱:")
for i, s in enumerate(toolkit.get_json_schemas(), 1):
print(f"{i}. {s['function']['name']}")
if __name__ == "__main__":
await main()
通过提供代码解释器,你将 Agent 从一个单纯的工具使用者,提升为了一个工具创造者。它的能力边界不再被你预先定义的工具集所束缚,从而具备了真正的创造性和问题解决的适应性。
4.6 何时选择自主规划?
你已经了解了“固定工作流”和“自主规划”两种模式,你可能会问:我是不是应该在所有场景下都使用更智能的自主规划,彻底放弃固定工作流?
这样想是不对的。自主性更高的模式不是银弹,自主性更低的模式也有广泛的应用场景。在生产实践中,一种非常有效的最佳实践是采用 “探索-固化”混合模式。
这种模式将任务处理分为两个阶段:
探索阶段:对于新出现的、流程不明确的任务(例如,你需要调研一个全新的、之前从未接触过的小众技术领域),你无法预先定义一个完美的流程。这时,就应该派出自主规划 Agent。它的任务是探索解决问题的不同路径,调用它认为合适的工具,即便过程中会犯错或走到死胡同,最终的目标是找到一条能稳定解决问题的方案。
固化阶段:当自主规划 Agent 经过多次探索,验证并总结出一条稳定、高效的解决方案路径后(例如,它发现“先用A工具从特定网站爬取信息,再用B工具进行数据清洗,最后用C工具生成总结报告”的流程成功率最高),你就可以将这条被验证过的路径抽象并固化下来,封装成一个可靠的“固定工作流”,用于后续大规模、重复性的生产调用。
这样,你就建立了一个持续优化的正向循环。
4.7 案例分析:让 Agent 操作网页
为了让你更具体地理解这种“感知-规划-行动”循环在实际产品中的应用,让我们来看一个高自主性网页操作 Agent 的案例,例如开源项目 Browser Use。
传统的网页自动化(RPA)工具需要为每个网站、每个任务编写固定的操作脚本。一旦网站界面稍有改动,脚本就会失效,维护成本极高。
一个具备规划能力的 Agent 则可以从根本上解决这个问题。它不依赖固定的脚本,而是像人一样理解用户的目标,并感知当前的网页状态,动态地规划出下一步操作。
执行流程拆解: 当用户给出指令 “在亚马逊上搜索关于 AI 的书籍” 时:
- 理解与初步规划:LLM 将模糊的目标分解为一系列高阶步骤:“1. 打开亚马逊网站;2. 找到搜索框;3. 输入’AI书籍’;4. 点击搜索;5. 分析结果。”
- 行动与感知:Agent 执行第一步(打开网站)。然后它“感知”新页面——这不仅是看 HTML 代码,还可能包括分析截图的视觉布局,来理解页面上有哪些元素。
- 决策与再规划:基于感知到的信息,它决策下一步行动:找到那个看起来最像“搜索框”的输入区域。如果页面上有多个输入框,它会根据位置、标签等信息进行推理判断。
- 循环执行:它持续这个“感知-规划-行动”的循环,直到完成所有步骤,并返回搜索到的书籍列表。
- 异常处理:如果在任何一步遇到意外,比如点击搜索后弹出一个验证码,它不会卡住。它会感知到这个新情况,并将“处理验证码”作为一个新的障碍插入到当前计划中,尝试解决它或向用户求助。

这个案例完整地展示了规划型 Agent 的核心优势:它不再是脚本执行器,而是通过持续的“感知-规划-行动”循环,实现了对动态、未知网页环境的真正自适应操作。
4.8 总结
让我们回顾一下你在本节学到的知识:
固定工作流的局限性:面对如“工具失效”等预期外的障碍时,预先设定的固定流程会“卡住”,因为它缺乏适应性。简单地为每个意外增加分支会让流程变得复杂且难以维护。
“规划”是核心解法:模仿人类解决问题的方式,我们让 Agent 从“任务执行者”升级为“解决方案规划师”。它不再被动执行固定步骤,而是围绕用户的最终“目标”,自主地动态生成和调整行动计划。
将计划转化为行动:你可以引导大模型生成结构化的计划(如JSON或代码),让机器精确执行。更高阶的方法是为 Agent 提供代码解释器,使其能在规划中动态创造并使用新工具,突破预设能力的限制。
在稳定与灵活间权衡:“自主规划”适用于探索未知、流程多变的创新任务,而“固定工作流”则保障核心业务的稳定和效率。在生产环境中,你需要结合人机协作、探索-固化等策略,根据具体业务需求,在这两种模式间做出明智的选择。
5 多智能体协作
5.1 像人类团队一样协作
某天,你的同事提议:能不能让机器人参与课程初稿开发?比如,写一篇 Pandas 数据分析的交互式课程初稿。当然,机器人最好能兼顾多种领域的课程,它们可能有不同的工作环节。你会发现,这是一个更加通用性的任务。
你之前学过:
- 对于像写作这样的多环节任务,你不可能让一个 Agent 完成所有任务,这样 Agent 容易丢三落四,工作效果很差。应该将它分解成多个步骤完成,每个专业步骤都用不同的专家 Agent 完成。
- 对于像写作这样的创意性、多样性任务,不同类型的课程写作步骤是不同的,你不可能穷举所有的写作步骤,并把它们固化成一个个工作流。你可以尝试让Agent自己规划写作流程。
于是,现在的问题变成了,如何把多个 Agent 有效组织起来,让它们既能并行的各自规划和执行,也能把最终的工作成果整合起来。
要实现这一点,你可以借鉴一下人类专家团队的工作方式。人类专家有各自擅长的领域,他们通过协作来完成复杂任务,而且可以并行处理任务。因此,你也可以把多个 Agent 组成一个 Agent Team,每个 Agent 都是相关领域的专家,大家各自分工协作,并行处理。
5.2 两种协作模式
在具体实现时,人类专家团队有两种常见模式:一种是像项目经理领衔的分解与执行,另一种是围绕白板的头脑风暴。在多智能体系统中,它们分别对应分层规划模式与共创协作模式。
5.2.1 模式一:分层规划模式 (Hierarchical/Team Leader Pattern)
这是对“项目团队”工作方式最直接的模拟,它的核心特点是一个中心化的星型结构。它引入了两种角色:
- 团队负责人 (Leader Agent):在本例中可以是一个“课程项目主管”Agent。它负责接收和理解顶层任务(如“撰写Pandas数据分析课程”),将其分解为多个具体的子任务(“设计教学大纲”、“提供核心案例与代码”、“撰写课程文稿”等),并将这些子任务分派给合适的团队成员。它还负责跟踪整体进度,并在所有成员完成后,汇总结果,形成最终的课程文稿。
- 团队成员 (Member Agents):各自拥有特定领域的专长(教学设计师、数据科学家、内容编写者),专注于执行分配给自己的子任务,并在完成后向 Leader 汇报。
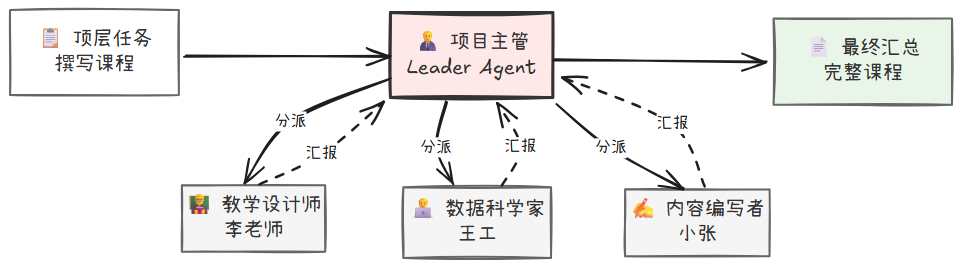
在 AgentScope 中,你可以使用handoff机制实现分层规划模式。此模式下, Leader Agent 将各领域专家视为工具,指派任务和听取汇报通过工具调用的形式实现。AgentScope 还支持异步工具调用和动态扩展工具,意味着你可以并发执行多个专家 Agent,还可以让 Leader Agent 根据需要实时创建专家 Agent。
import os
from typing import Any
from agentscope.agent import ReActAgent
from agentscope.formatter import DashScopeMultiAgentFormatter
from agentscope.message import Msg
from agentscope.model import DashScopeChatModel
from agentscope.tool import ToolResponse, Toolkit
# ---- 1. 定义统一的专家 Agent 角色和提示 -
---
DESIGNER_LI_PROMPT = """
你是李老师,一位经验丰富的教学设计师。你的任务是为“Pandas 数据分析入门”课程设计出清晰、有逻辑的教学大纲。专注于:1. 定义每个模块清晰的学习目标。2. 确保知识点由浅入深,循序渐进。3. 提出互动性的练习和项目来巩固学习效果。
"""
SCIENTIST_WANG_PROMPT = """
你是王工,一位资深数据科学家,也是 Pandas 的实战专家。你的任务是为课程提供准确、实用的技术内容。专注于:1. 提供最核心、最常用的 Pandas 知识点。2. 设计源于真实工作场景的案例和数据集。3. 编写简洁、规范、易于理解的代码示例。
"""
WRITER_ZHANG_PROMPT = """
你是小张,一位充满创意的课程内容编写者。你的任务是把技术内容讲得通俗易懂、但不失严谨性、用词冷静克制的课程文稿。专注于:1. 用通俗易懂的语言和比喻来解释复杂概念。2. 设计真实性高的案例场景和模块标题。3. 确保课程的整体基调是鼓励性和启发性的。
"""
LEADER_PROMPT = """
你是一个课程项目主管,负责协调团队完成“Pandas入门课程”的初稿开发。
你有三名团队成员可以作为工具调用,他们每个人的工作都依赖于前一个人的输出。
你的工作流程必须严格遵循以下顺序:
1. **首先,调用 invoke_designer_li**,让他为课程创建一个初步的大纲和学习目标。
2. **其次,调用 invoke_scientist_wang**。将李老师生成的大纲作为 `context` 参数传递给他,要求他根据这个大纲填充技术要点和代码示例。
3. **接着,调用 invoke_writer_zhang**。将李老师和王工的全部产出合并后作为 `context` 参数传递给她,要求她在此基础上撰写完整的、对学习者友好的课程文稿。
4. **最后**,在收到所有专家的最终结果后,将它们整合成一份格式统一、内容完整的最终课程文档,然后作为你的最终回复。
"""
# ---- 2. 统一模型和 Agent 配置 ----
def get_model_instance() -> DashScopeChatModel:
"""获取一个统一配置的模型实例。"""
return DashScopeChatModel(
model_name="qwen-plus",
api_key=os.environ.get("DASHSCOPE_API_KEY"),
)
def create_member_agent(name: str, sys_prompt: str) -> ReActAgent:
"""根据给定的名称和系统提示创建一个团队成员 Agent。"""
return ReActAgent(
name=name,
sys_prompt=sys_prompt,
model=get_model_instance(),
formatter=DashScopeMultiAgentFormatter(),
)
# ---- 3. 定义作为工具的“团队成员” Agent (Handoffs 模式) ----
async def invoke_designer_li(task_description: str, context: str = "") -> ToolResponse:
"""
当需要设计课程大纲、学习目标或教学活动时,调用教学设计师李老师。
Args:
task_description (str): 清晰地描述你需要李老师完成的设计任务。
context (str): 可选。传递相关的背景信息或先前的工作成果。
"""
print("\n--- 任务分派:正在调用教学设计师李老师 ---")
agent = create_member_agent("DesignerLi", DESIGNER_LI_PROMPT)
content_for_agent = task_description
if context:
content_for_agent = f"背景信息:\n{context}\n\n你的任务:{task_description}"
result_msg = await agent(Msg(name="user", role="user", content=content_for_agent))
return ToolResponse(content=result_msg.get_text_content())
async def invoke_scientist_wang(task_description: str, context: str = "") -> ToolResponse:
"""
当需要提供专业技术知识、代码示例或真实案例时,调用数据科学家王工。
Args:
task_description (str): 清晰地描述你需要王工完成的技术任务。
context (str): 可选。传递课程大纲等先前的工作成果,以便他在此基础上工作。
"""
print("\n--- 任务分派:正在调用数据科学家王工 ---")
agent = create_member_agent("ScientistWang", SCIENTIST_WANG_PROMPT)
content_for_agent = task_description
if context:
content_for_agent = f"请基于以下课程大纲和背景信息来完成你的任务:\n{context}\n\n你的具体任务是:{task_description}"
result_msg = await agent(Msg(name="user", role="user", content=content_for_agent))
return ToolResponse(content=result_msg.get_text_content())
async def invoke_writer_zhang(task_description: str, context: str = "") -> ToolResponse:
"""
当需要将技术内容转化为易于理解的文稿时,调用内容编写者小张。
Args:
task_description (str): 清晰地描述你需要小张完成的写作任务。
context (str): 可选。传递大纲和技术要点等先前的工作成果,作为写作基础。
"""
print("\n--- 任务分派:正在调用内容编写者小张 ---")
agent = create_member_agent("WriterZhang", WRITER_ZHANG_PROMPT)
content_for_agent = task_description
if context:
content_for_agent = f"请基于以下课程的草稿(包含大纲和技术点)来完成你的写作任务:\n{context}\n\n你的具体任务是:{task_description}"
result_msg = await agent(Msg(name="user", role="user", content=content_for_agent))
return ToolResponse(content=result_msg.get_text_content())
# ---- 4. 组织“分层规划”工作流 ----
async def main() -> None:
"""主执行函数,负责编排整个工作流。"""
# 4.1 创建主管的工具包并注册团队成员
leader_toolkit = Toolkit()
leader_toolkit.register_tool_function(invoke_designer_li)
leader_toolkit.register_tool_function(invoke_scientist_wang)
leader_toolkit.register_tool_function(invoke_writer_zhang)
# 4.2 创建主管 Agent
leader_agent = ReActAgent(
name="ProjectLeader",
sys_prompt=LEADER_PROMPT,
model=get_model_instance(),
toolkit=leader_toolkit,
formatter=DashScopeMultiAgentFormatter(),
)
# 4.3 定义顶层任务
top_level_task = (
"请为初学者创建一节关于Pandas 数据分析的简短课程初稿。"
)
print(f"项目主管收到的顶层任务:\n{top_level_task}\n" + "="*50)
# 4.4 将任务交给主管 Agent 执行
final_response_msg = await leader_agent(Msg(name="user", role="user", content=top_level_task))
# 4.5 展示最终成果
print("\n" + "="*50)
print(" 项目主管最终的汇总报告:")
print("="*50 + "\n")
print(final_response_msg.get_text_content())
# ---- 5. 运行主程序 ----
await main()
当一个课程开发项目启动时,项目主管会将需求文档拆解成清晰的任务清单,然后分发给教学设计师、数据科学家和内容编写者。这种模式的优点显而易见:结构清晰,权责分明。每个人都清楚自己的任务和交付期限,项目主管可以轻松地跟踪整体进度,确保项目不会偏离预定轨道。因此,这种模式非常适合目标明确、可以被清晰地分解为多个并行子任务的场景。
但这种模式的局限性也同样源于其结构。教学设计师和数据科学家之间通常不直接沟通,而是通过项目主管传递信息。如果数据科学家在编写代码时,发现某个理论点用一个更简单的例子就能讲明白,他需要先向主管汇报,主管再传达给设计师。这个过程可能存在信息延迟或失真。最终,课程的各个模块虽然都高质量地完成了,但组合起来可能会感觉有些生硬,缺乏浑然一体的流畅感。因为专家之间缺乏直接的、实时的思想碰撞。
5.2.2 模式二:共创协作模式 (Co-creation/Blackboard Pattern)
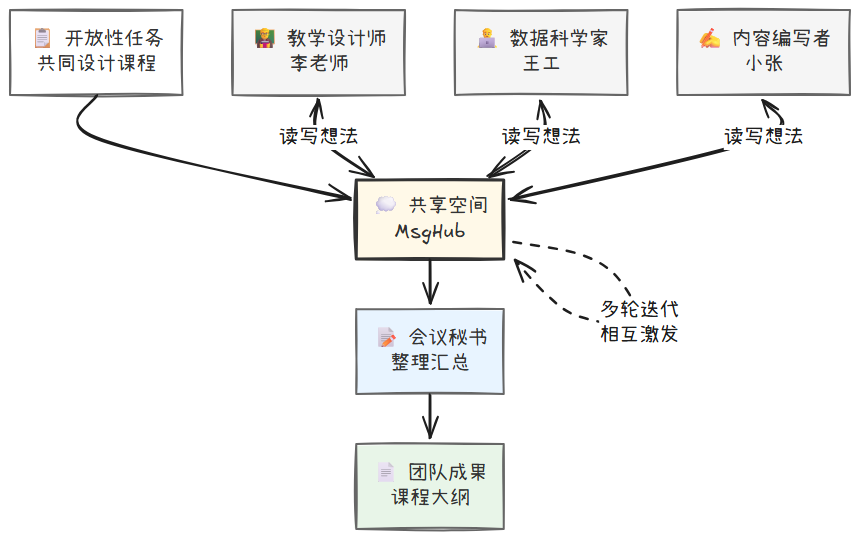
这种模式下,没有一个高层级的协调员,而是一群专家在会议室里,围绕一块白板进行的**“头脑风暴”**。其特点是去中心化。
- 设立共享空间 (Shared Blackboard):创建一个所有 Agent 都能读写的共享空间(例如一个共享文档、数据库记录或消息队列)。
- 并行贡献与迭代:当一个开放性问题(如“为新课程设计一个有趣的项目案例”)被发布到共享空间后,所有专家 Agent(教学设计师、数据科学家、内容编写者)同时开始思考,并将自己的想法、论据或方案草稿写入共享空间。
- 激发与深化:在每一轮迭代中,所有 Agent 都会读取共享空间中来自他人的所有新想法。这些想法会激发它们产生新的灵感,或对自己的方案进行修正、补充、质疑,并将更新后的想法再次写入。例如,数据科学家 Agent 提出用“分析用户电影评分数据”作为案例,教学设计师 Agent 看到后补充“可以引导学生探索不同类型电影的评分趋势”,内容编写者 Agent 则提出“可以把案例包装成一个‘电影推荐系统揭秘’的故事”。
- 达成共识:这个“读取-思考-写入”的循环会持续进行,直到系统中涌现出一个被多数 Agent 认可的最终方案,或者达到预设的迭代次数。
在 AgentScope 中,你可以使用 MsgHub 来实现共创协作模式。在这种模式下,任何 Agent 的回复都能自动被其他参与者“听到”并作为上下文。
import os
from agentscope.agent import ReActAgent
from agentscope.formatter import DashScopeMultiAgentFormatter
from agentscope.message import Msg
from agentscope.model import DashScopeChatModel
from agentscope.pipeline import MsgHub
from textwrap import dedent
# ---- 1. 定义统一的专家 Agent 角色和提示 ----
DESIGNER_LI_PROMPT = """
你是李老师,一位经验丰富的教学设计师。你的任务是为“Pandas 数据分析入门”课程设计出清晰、有逻辑的教学大纲。在讨论中,你专注于:1. 定义每个模块清晰的学习目标。2. 确保知识点由浅入深,循序渐进。3. 提出互动性的练习和项目来巩固学习效果。
"""
SCIENTIST_WANG_PROMPT = """
你是王工,一位资深数据科学家,也是 Pandas 的实战专家。你的任务是为课程提供准确、实用的技术内容。在讨论中,你专注于:1. 提供最核心、最常用的 Pandas 知识点。2. 设计源于真实工作场景的案例和数据集。3. 编写简洁、规范、易于理解的代码示例。
"""
WRITER_ZHANG_PROMPT = """
你是小张,一位充满创意的课程内容编写者。你的任务是把技术内容讲得通俗易懂、但不失严谨性、用词冷静克制的课程文稿。在讨论中,你专注于:1. 用通俗易懂的语言和比喻来解释复杂概念。2. 设计真实性高的案例场景和模块标题。3. 确保课程的整体基调是鼓励性和启发性的。
"""
# ---- 2. 创建专家 Agent 的辅助函数 ----
def create_expert_agent(name: str, sys_prompt: str) -> ReActAgent:
"""根据给定的名称和系统提示创建一个专家 Agent。"""
return ReActAgent(
name=name,
sys_prompt=sys_prompt,
model=DashScopeChatModel(
model_name="qwen-plus",
api_key=os.environ.get("DASHSCOPE_API_KEY"),
),
formatter=DashScopeMultiAgentFormatter(),
)
# ---- 3. 组织协作流程的主函数 ----
async def main() -> None:
"""运行 Pandas 课程开发的共创协作模式,并生成最终成果。"""
print("=== 开始课程开发会议:构思 'Pandas 入门' 课程大纲和案例 ===")
# 创建课程开发团队
designer_li = create_expert_agent("李老师 (教学设计师)", DESIGNER_LI_PROMPT)
scientist_wang = create_expert_agent("王工 (数据科学家)", SCIENTIST_WANG_PROMPT)
writer_zhang = create_expert_agent("小张 (内容编写者)", WRITER_ZHANG_PROMPT)
# 定义会议开场白
announcement = Msg(
"system",
(
"团队好,我们今天的目标是共同协作,为“Pandas 数据分析入门”课程制定一个完整的、吸引人的**课程大纲和核心案例**。"
"请大家集思广益,从教学设计师李老师开始,提出你的第一轮建议。"
),
"system",
)
# 启动多轮讨论
async with MsgHub(
participants=[designer_li, scientist_wang, writer_zhang],
announcement=announcement,
) as hub:
for i in range(2):
print(f"\n--- 第 {i + 1} 轮协作 ---")
# 按照发言顺序依次调用
await designer_li()
await scientist_wang()
await writer_zhang()
print("\n=== 会议结束 ===")
# ==================== 汇总阶段 ====================
print("\n=== 开始生成最终团队成果(课程大纲初稿) ===")
# 4.1 定义一个“会议秘书” Agent 来整理会议纪要
secretary_prompt = dedent("""
你是一位专业的会议秘书,非常擅长整理会议纪要。
你的任务是阅读下面的团队讨论记录,然后根据讨论内容,以清晰的 Markdown 格式,
生成“Pandas 入门课程”的**课程大纲初稿**。
大纲应包含以下部分:
- **模块标题**:一个吸引人的标题。
- **学习目标**:清晰列出学生学完本模块后能做什么。
- **核心概念**:涵盖的关键技术点。
- **核心案例**:贯穿本模块的实践案例和数据集。
- **代码示例**:需要包含的关键代码演示。
- **课后练习**:一个具体的动手练习任务。
""")
secretary_agent = create_expert_agent("会议秘书", secretary_prompt)
# 4.2 准备完整的讨论记录
full_transcript_msgs = await designer_li.memory.get_memory()
transcript_text = "以下是团队的讨论记录:\n\n"
for msg in full_transcript_msgs:
if msg.role != "system":
transcript_text += f"[{msg.name}]: {msg.content}\n"
# 4.3 指派汇总任务
final_task_prompt = dedent(
f"{transcript_text}\n"
"请根据以上讨论记录,整理出课程大纲初稿。"
)
# 调用秘书 Agent 来完成任务
final_output_msg = await secretary_agent(Msg("user", final_task_prompt, "user"))
# 4.4 展示最终成果
print("\n" + "="*25)
print(" 最终团队成果:课程大纲初稿")
print("="*25 + "\n")
print(final_output_msg.content)
await main()
在这种开放的讨论中,一个人的想法会立刻激发另一个人的灵感,从而产生“1+1>2”的效果。这种去中心化的协作能够最大程度地激发集体智慧,尤其适合解决那些没有唯一正确答案的、需要集思广益的开放性、创造性问题。
当然,这种模式的风险也很明显。一场没有良好引导的头脑风暴,很可能因为讨论发散而迟迟无法收敛,或者陷入僵局。由于没有一个中心化的决策者,团队可能会在一些细节上过度优化,而忽略了整体目标。同时,所有成员都需要不断地同步和处理来自他人的海量信息,这对控制通信的成本也提出了更高的要求。
5.3 选择建议:设计来源于现实
在了解了分层规划和共创协作两种模式后,一个自然的问题是:我应该选择哪一个?或者,还有没有其他的模式?
答案是:没有所谓的“最佳模式”。一个优秀的多智能体(Multi-Agent)系统,其设计往往来源于对现实世界的模仿和提炼。
与其去记忆抽象的模式名称,不如走进你的业务,去观察现实世界中,人类专家团队是如何完成类似任务的。在观察时,你可以重点关注以下三个方面:
- 业务流程:任务本身包含哪些环节?这些环节是上下游依赖还是可以并行?它们之间是如何衔接的?
- 专家角色:这个流程中需要哪些不同能力的专家?他们各自的核心职责是什么?
- 协作方式:专家们是如何沟通的?是通过一个中心化的项目经理传递信息,还是在一个会议室里围绕白板自由讨论?信息是如何在他们之间流转的?
基于这些观察,你可以遵循一个清晰的设计路径:
- ① 观察现实:深入理解人类团队的工作方式。
- ② 还原流程:将现实中的角色和协作流程,映射为你的 Agent 角色和协作机制。
- ③ 迭代改进:在还原的基础上,利用 AI 的优势进行优化和增强。
例如,在我们的课程开发案例中,“项目主管”模式就是对有明确交付成果(Deliverable)的项目的模拟;而“头脑风暴”模式则是对早期创意构思会议的模拟。现实中,一个完整的项目甚至可能两者兼有:先通过“头脑风暴”确定核心创意,再切换到“项目主管”模式来分工执行。这种混合模式,既保留了整体结构的可控性,又在关键节点引入了创造性。
最终,记住这个核心思想:
与其记忆 Multi-Agent 有哪些模式,不如走进业务,去看看现实世界中,人类专家们是怎么协作的。
5.4 总结
让我们回顾一下你在本节学到的知识:
- 单体 Agent 的局限性:追求“全能”的单个 Agent 在处理需跨多个专业领域的复杂任务(如课程开发)时,往往会因知识边界和认知负荷而表现不佳。
- 多智能体的核心思路:从僵化的“流水线”模式的失败中,你受到现实世界高效团队的启发,认识到“专业分工、并行处理、沟通整合”是解决复杂问题的关键。
- 多智能体协作模式:你掌握了两种主流的协作模式。分层规划模式通过模拟“项目主管-专家”的结构,高效处理可清晰拆解的任务;共创协作模式则通过模拟“头脑风暴”,在开放式问题上激发集体智慧。
- 成本与价值的权衡:虽然多智能体系统会增加调用成本和延迟,但它通过提高最终产出的“可用性”,避免了因低质量输出而导致的重复尝试和隐性成本,是一种对高质量结果的有效投资。
6 为 Agent 赋予记忆
在本节课程中,你将学习如何为你的 Agent 赋予记忆能力,解决大语言模型固有的“健忘”问题。你将从一个最朴素的方法开始,逐步发现其局限性,并最终掌握业界主流的短期和长期记忆构建策略。
本质还是和多轮对话一样, 把之前的信息给大模型
6.1 建立短期记忆
在之前的课程中,你正在构建一个能帮你写作课程的 Agent 团队。内容编写 Agent 刚刚完成了一份出色的初稿。你很满意,并对它说:“很好,现在请根据我们上次讨论的教学风格,把第二部分写得更生动一些。”
然而,Agent 的回应却让你失望:“好的,请问我们上次讨论了什么样的教学风格?”,它忘记了过去的任务细节。这是因为你的Agent 是无状态的。每次开启新的对话,它就会忘记过去对话的所有内容。
扩展阅读:大语言模型的核心特性——无状态 (Stateless)
你可以将大模型想象成一个记忆力只有几秒钟的专家。在每一次独立的 API 调用中,它能理解你给它的所有信息并给出精彩的回答。但一旦这次调用结束,它会彻底忘记一切。它不会记得你是谁,你们之前聊过什么,你的任何偏好和要求。Agent 的每一次
reply本质上都是一次独立的 API 调用,因此它天然地继承了这种无状态性。
那我们该如何解决呢?一个最直接的想法,就是每次和它说话时,都把之前的聊天记录“复习”一遍。
在编程实现中,这意味着你需要创建一个列表,用来存放所有的对话历史。每次向 Agent 提问时,你都把这个包含完整历史的列表一起发给它。AgentScope 中的 InMemoryMemory 就是这种朴素方案的实现。
让我们通过代码来验证一下。
# 创建一个课程编写 Agent
writing_agent = create_agent(
name="Writer",
sys_prompt="你是一个课程内容编写员。你的任务是编写一篇 Pandas 数据分析课程。"
)
async def run_stateless_test():
# 第一次对话:设定教学风格
msg1 = Msg("user", "我们的教学风格要严谨克制,请记住这一点。", "user")
print(f"[{msg1.name}]: {msg1.content}")
# Agent 会将这次对话存入它的 InMemoryMemory
reply1 = await writing_agent(msg1)
print(f"[{reply1.name}]: {reply1.content}")
print("\n" + "="*20 + "\n")
# 第二次对话:基于之前的设定提出新要求
# 在调用时,writing_agent 会自动将 InMemoryMemory 中的历史记录和新消息一起发给模型
msg2 = Msg("user", "很好,现在请把第二部分写得更专业一些。", "user")
print(f"[{msg2.name}]: {msg2.content}")
reply2 = await writing_agent(msg2)
print(f"[{reply2.name}]: {reply2.content}")
print("\n" + "="*20 + "\n")
print("Agent 的短期记忆内容:")
# 打印 Agent 的记忆,可以看到包含了全部两轮对话
for m in await writing_agent.memory.get_memory():
print(f"- [{m.role}] {m.name}: {m.content}")
await run_stateless_test()
这个方案立竿见影,Agent 立刻拥有了短期内的对话记忆。
6.2 信息精炼
但当你把这个 Agent 投入真实场景,连续使用十几轮、几十轮对话后,两个严重的问题会浮现出来:
- 上下文窗口限制。每个大模型都有一个能处理的最大文本长度,我们称之为“上下文窗口”。随着对话轮次增加,对话历史会像滚雪球一样越来越大,最终超出模型的窗口限制,程序会直接报错。
- 急剧上升的成本。大模型的 API 调用是按量计费的,你发送的文本(输入)和它生成的文本(输出)中的每一个 Token 都要花钱。经过多轮对话后,每次 API 调用都需要重新发送全部历史记录,产生重复的 token 成本。
这种朴素的“记忆”方案,只是一种寅吃卯粮的短期策略。它很快就会导致程序异常或成本超支。
这引出了一个核心问题:如何在不牺牲关键信息的前提下,有效管理上下文的长度与成本?
这个问题的本质,是如何对信息进行高效的压缩和筛选。就像你在准备开卷考试时,不会把整本教科书都抄到小抄上,而是会提炼出最重要的公式、定义和关键论点。
6.3 记忆管理策略
让我们借鉴人类准备考试的思路,探索管理 Agent 记忆的策略。
6.3.1 策略一:简单"遗忘"——固定窗口截断 (Context Truncation)
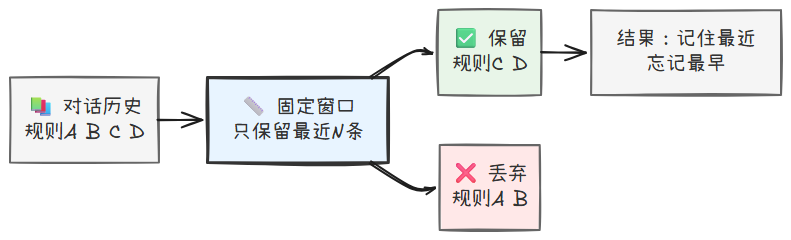
最简单粗暴的方法,就是只记最近发生的事,这叫作固定窗口截断。
- 思路:你设定一个固定的窗口大小,比如只保留最近的 N 轮对话,或者更精确地,只保留最近的 N 个 Token。当对话历史超过这个大小时,就把最老的那一轮对话丢掉,确保上下文总长度基本保持不变。
- 相对优势:实现极其简单,计算开销小,能有效保证上下文长度永远在可控范围内,避免了报错和成本无限增长的问题。
- 适用场景:适用于那些信息价值随时间快速衰减的场景,例如闲聊机器人或者简单的客服问答。
- 边界条件:这是一种“一刀切”的失忆方案。如果对话早期的关键信息(例如用户在第一轮对话中设定的核心目标)被截断,Agent 就会再次“失忆”,导致对话逻辑断裂。
在 AgentScope 中,这个功能由 Formatter 组件实现。你可以在初始化 Formatter 时传入 max_tokens 参数来限制上下文长度。
6.3.2 策略二:提炼重点——滚动摘要 (Rolling Summary)
简单截断会直接丢弃信息,显然不够理想。一个更聪明的做法是,在遗忘细节之前,先把重点提炼出来。这就是滚动摘要策略。
- 思路:随着对话进行,当历史记录快要“塞满”窗口时,你调用一次大模型,将最早的一部分对话内容(比如前 50%)提炼成一段简短的摘要。然后,在后续的请求中,用这段凝练的“记忆摘要”替换掉冗长的原始对话记录。
- 相对优势:在压缩长度的同时,最大程度地保留了历史对话的核心信息,能更好地维持对话的长期连贯性。
- 适用场景:适用于需要长期保持目标一致性的任务,比如项目规划、长篇内容创作等。
- 边界条件:它引入了额外的 API 调用成本(用于生成摘要),并且摘要的质量直接影响后续对话。

目前 AgentScope 尚未内置此功能,但你可以很容易地通过自定义 Memory 类来实现这个逻辑。下面是一个概念性的实现思路:
# 这是一个伪代码示例,用于演示滚动摘要的核心逻辑
# 它不能直接运行,需要你继承 agentscope.memory.MemoryBase 并实现完整逻辑
class SummaryMemory: # (MemoryBase)
def __init__(self, buffer_size=10, summary_ratio=0.5):
self.history = []
self.buffer_size = buffer_size
self.summary_ratio = summary_ratio
def add(self, message):
self.history.append(message)
self.try_summarize()
def try_summarize(self):
if len(self.history) > self.buffer_size:
# 1. 确定要摘要的部分
num_to_summarize = int(len(self.history) * self.summary_ratio)
messages_to_summarize = self.history[:num_to_summarize]
# 2. 调用大模型生成摘要 (伪代码)
# summary_text = llm.call("请将以下对话总结为一段话:", messages_to_summarize)
summary_text = "用户设定了教学风格为风趣幽默,并要求内容生动。"
summary_message = Msg("system", f"【历史摘要】{summary_text}", "system")
# 3. 用摘要替换原始对话
self.history = [summary_message] + self.history[num_to_summarize:]
print(f"--- 记忆已压缩,当前长度 {len(self.history)} ---")
def get_memory(self):
return self.history
# 使用示例
# summary_mem = SummaryMemory()
# summary_mem.add(Msg("user", "我们的教学风格要风趣幽默。", "user"))
# ... 经过多轮对话后 ...
# summary_mem.add(Msg("user", "再增加一个关于成本的案例。", "user")) # 此时可能会触发摘要
6.3.3 策略三:构建知识库——向量化召回 (Vector-based Retrieval)
前面的策略依然在用一种线性的、无差别的方式处理所有对话历史。但这并不符合我们人类的记忆模式。你的记忆不是一条按时间顺序播放的磁带,而是一个巨大的、相互关联的知识网络。
这种“按需检索”的模式,正是构建高级记忆系统的核心。该策略彻底改变了游戏规则:你不再试图把所有历史都塞进上下文,而是将每一轮对话都变成可独立检索的“记忆碎片”,存入一个专门的“长期记忆库”。
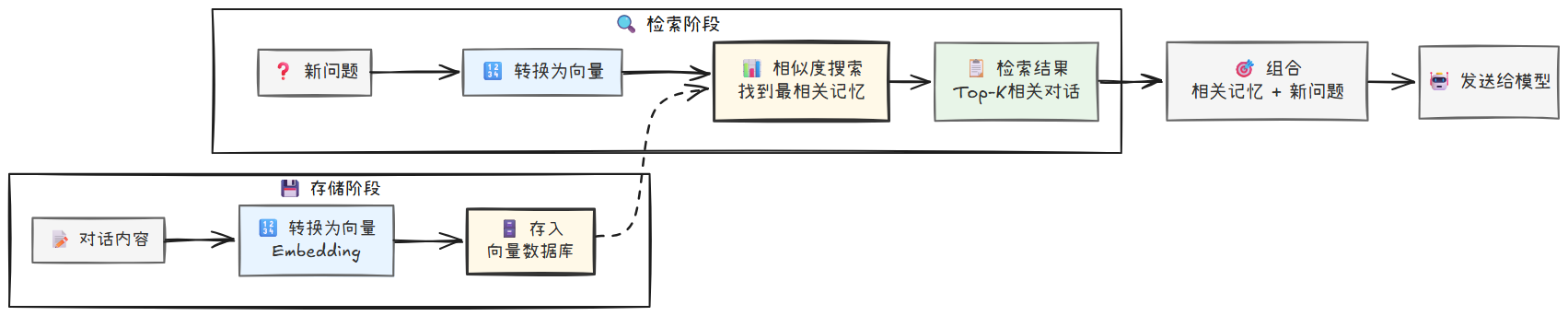
思路:
- 存储 (Ingestion):每轮对话结束后,你将对话内容转换成一个数学向量(Embedding),然后连同原文一起存入一个向量数据库 (Vector Database)。
- 检索 (Retrieval):当用户提出新问题时,你先将这个问题也转换成向量,然后去数据库中进行相似度搜索,找出与当前问题最相关的几条历史对话记录。
- 组合 (Composition):最后,你将检索到的“相关记忆”和用户的“最新问题”组合成一个精简而高效的上下文,再发送给大模型。
相对优势:从根本上摆脱了上下文窗口的长度束缚,能根据当前意图,从海量信息中精准地“回忆”起最相关的内容,极大地节约了成本。
适用场景:这是构建真正智能、可长期交互的 Agent 的基石。适用于个性化助手、企业知识库、智能学习伴侣等所有复杂场景。
边界条件:系统复杂度最高。它引入了 Embedding 模型和向量数据库等新的技术栈。
AgentScope 通过 Mem0LongTermMemory 模块优雅地实现了这一功能。它支持两种工作模式:
static_control:在每次 Agent 回复前后,自动地、被动地保存和检索记忆。agent_control:赋予 Agent 主动管理记忆的工具(record_to_memory,retrieve_from_memory),让 Agent 自行决定何时记忆、何时回忆。
让我们先看看更简单的 static_control 模式。
# 1. 初始化长期记忆模块
# 它需要一个语言模型(用于内部处理)和一个嵌入模型
from mem0.vector_stores.configs import VectorStoreConfig
# 为 Qdrant 本地向量库指定与 DashScope Embedding 一致的维度(2048)
vector_store = VectorStoreConfig(
config={
"on_disk": False,
"embedding_model_dims": 2048,
}
)
long_term_memory = Mem0LongTermMemory(
agent_name="Writer",
user_name="user",
model=DashScopeChatModel(
model_name="qwen-plus",
api_key=os.environ.get("DASHSCOPE_API_KEY"),
stream=False,
),
embedding_model=DashScopeTextEmbedding(
model_name="text-embedding-v4",
api_key=os.environ.get("DASHSCOPE_API_KEY"),
dimensions=2048
),
vector_store_config=vector_store,
)
# 2. 创建一个装备了长期记忆的 Agent
ltm_agent_static = create_agent(
name="LTM_Writer_Static",
sys_prompt="你是一个拥有长期记忆的课程编写员。",
long_term_memory=long_term_memory,
long_term_memory_mode="static_control", # 关键参数:设置为静态控制模式
)
async def run_ltm_static_test():
# 对话一:存入一个关键信息
msg1 = Msg("user", "记住,我们正在写一篇 Pandas 数据分析课程,目前已经写完初稿。", "user")
print(f"[{msg1.name}]: {msg1.content}")
reply1 = await ltm_agent_static(msg1)
print(f"[{reply1.name}]: {reply1.content}")
# 在这一步之后,对话内容会被自动存入长期记忆
print("\n" + "="*20 + " 模拟新的一次会话 " + "="*20 + "\n")
# 清空 Agent 的短期记忆,模拟一次全新的会话
await ltm_agent_static.memory.clear()
print("Agent 的短期记忆已被清空。")
# 对话二:提出一个相关问题
# Agent 在回复前,会用问题“这门课适合谁?”去长期记忆中检索
msg2 = Msg("user", "我们上次的工作进度到哪儿了?", "user")
print(f"[{msg2.name}]: {msg2.content}")
reply2 = await ltm_agent_static(msg2)
print(f"[{reply2.name}]: {reply2.content}")
print("\n注意: 即使短期记忆被清空,Agent 依然能回答正确,因为它从长期记忆中检索到了相关信息。")
await run_ltm_static_test()
6.3.4 进阶:从被动上下文到主动记忆管理
至此,你已经掌握了为 Agent 构建记忆系统的强大策略。但一个真正智能的 Agent,不应只是被动地接收你处理好的上下文,它应该能主动地管理自己的记忆。
通过将 long_term_memory_mode 设置为 agent_control,ReActAgent 会自动获得 record_to_memory 和 retrieve_from_memory 两个工具。你需要在系统提示词中引导它使用这些工具。
# 复用之前创建的 long_term_memory 实例
# 重新创建一个 Agent,这次使用 agent_control 模式
from textwrap import dedent
ltm_agent_active = create_agent(
name="LTM_Writer_Active",
sys_prompt=dedent(
"你是一个拥有主动记忆管理能力的课程编写员。\n"
"你可以使用以下工具来管理你的长期记忆:\n"
"- `record_to_memory(data: str)`: 将一段重要的信息记录到长期记忆中。\n"
"- `retrieve_from_memory(query: str) -> str`: 根据查询从长期记忆中检索相关信息。\n"
"在回答问题前,先思考是否需要检索记忆。在对话结束后,思考是否有关键信息需要记录。"
),
long_term_memory=long_term_memory,
long_term_memory_mode="agent_control", # 关键参数:设置为 Agent 控制模式
)
async def run_ltm_active_test():
# 对话一:Agent 自主决定记录信息
msg1 = Msg("user", "课程的写作风格必须非常严谨和学术化,这是一个核心要求。", "user")
print(f"[{msg1.name}]: {msg1.content}")
reply1 = await ltm_agent_active(msg1)
# Agent 在这里的思考过程中,会判断“核心要求”是重要信息,并调用 record_to_memory 工具
print(f"[{reply1.name}]: {reply1.content}")
print("\n" + "="*20 + " 模拟一次新的会话 " + "="*20 + "\n")
await ltm_agent_active.memory.clear()
# 对话二:Agent 自主决定检索信息
msg2 = Msg("user", "我忘了,我们课程的写作风格是什么来着?", "user")
print(f"[{msg2.name}]: {msg2.content}")
reply2 = await ltm_agent_active(msg2)
# Agent 在这里的思考过程中,会先调用 retrieve_from_memory(query="写作风格"),再根据检索结果生成回答
print(f"[{reply2.name}]: {reply2.content}")
await run_ltm_active_test()
通过这种方式,记忆不再是你从外部“喂”给 Agent 的数据,而是它自己主动获取、存储和维护的内在知识。这使得 Agent 从一个简单的“工具”向真正的“伙伴”进化。
扩展阅读:成本效益分析
你可能会认为,向量化召回和主动记忆管理引入了 Embedding 模型调用、向量数据库查询以及额外的 LLM 推理(用于决定是否调用工具),这会增加成本和时延。
然而,我们不能简单地将“一次高质量输出”的成本与“一次低质量输出”的成本进行比较。因为如果单次调用无法有效解决问题(比如忘记了关键要求),那么它的成本无论多低,都是一种浪费。
一个更公平的比较是:为获得一个“可用”的答案,两种路径的总成本是多少?
- 路径A(无长期记忆):一次调用,得到错误答案(问题未解决)。你不得不手动提醒,再调用一次,才能解决问题。
- 路径B(有长期记忆):一次调用(包含检索),直接得到正确答案(问题解决)。
从这个角度看,为记忆系统增加的投入,是确保产出质量、避免重复无效尝试的必要投资。
6.3.5 构建短期与长期记忆系统
通过上述策略的组合,你已经为 Agent 构建了一个完整的记忆系统,它可以清晰地划分为两个部分:
- 短期记忆 (Short-term Memory):基于对话缓冲区,通过截断或摘要策略进行管理。它的核心职责是维持当前会话的连贯性。例如,记住你刚刚提出的,关于“第二章内容需要增加一个案例”的具体要求。
- 长期记忆 (Long-term Memory):基于向量数据库和工具化调用。它的核心职责是持久化存储关键信息,并支持跨会话的智能检索。例如,记住整个课程项目的核心目标是“为初学者设计,风格需风趣幽默”。
拥有记忆的 Agent,不再是一个冰冷的、一次性的问答机器。它能够从经验中学习,记住你的偏好,理解长期的语境,最终从一个简单的“工具”进化为真正的“伙伴”。
落地实践与使用建议
一、 快速引入记忆能力
你可以借助成熟的开源框架或平台,快速为你的 Agent 添加记忆能力。
- AgentScope: 如本课程所示,
AgentScope提供了InMemoryMemory作为基础短期记忆,以及集成了Mem0的Mem0LongTermMemory作为开箱即用的长期记忆解决方案。- Mem0: 一个专为 AI 应用设计的开源智能记忆层,它将向量化召回、记忆冲突处理等复杂逻辑封装起来,提供了强大的底层支持。
- LangChain Memory: 强大的 Agent 开发框架 LangChain 提供了丰富的内置 Memory 模块,包括
ConversationBufferMemory(缓冲区)、ConversationSummaryMemory(摘要)和VectorStoreRetrieverMemory(向量召回)等,允许你根据需求灵活组合。二、 记忆使用建议
- 有选择地记忆:记忆并非越多越好。积累大量低价值或噪声信息会干扰后续检索效果。你应该建立记忆写入的准入机制,例如仅在用户显式要求(“请记住…”)或信息重要性高于某个阈值时才写入。
agent_control模式就是实现这一点的好方法。- 持续治理:记忆是一类动态的数据资产,需要建立持续治理机制,包括定期清理过时信息、合并重复条目、校验事实准确性,并为用户提供主动管理自己记忆的接口(查看、修改、删除)。
- 场景化应用:不同业务场景对记忆的需求不同。例如,在要求风格一致的课程文档工作流中,不应记录个性化的偏好;但对于产品的事实信息(如 API 参数、功能限制),则可以记录并定期审查其有效性,确保 Agent 生成内容的准确性。
6.4 总结
让我们回顾一下你在本节学到的知识:
- 问题的根源:无状态性:大语言模型本身没有记忆,每次调用都是独立的。朴素地传递完整历史会导致上下文超长和成本失控。
- 短期记忆 vs 长期记忆:你可以通过“截断”与“摘要”策略管理短期记忆,维持当前会话连贯性;通过“向量化召回”构建长期记忆,实现跨会话的知识存取。
- 主动记忆管理:通过为 Agent 提供
save,recall,update等记忆工具,你可以让它从被动接收上下文,转变为能主动管理和运用自身记忆的智能体,实现真正的学习与成长。 - 记忆的最佳实践:一个强大的记忆系统需要被有效治理。你应该有选择地写入、持续地清理和更新记忆,并根据具体业务场景(如课程写作)决定应该记忆什么、不记忆什么。
7 评测驱动开发
7.1 为什么"感觉还行"靠不住
你刚刚部署了你的“课程写作 Agent”第一个版本。在本地用几个例子测试时,它表现得似乎“还不错”。但上线后,用户的反馈却不尽人意。有人抱怨技术概念的解释不准确,有人觉得响应的文字太啰嗦,还有人遇到了代码示例无法运行的格式错误。
你立刻尝试修复,比如调整提示词让 Agent 的解释“更准确一些”。改完后,你再次输入“介绍 Python 的 for 循环”这个主题,快速浏览生成的内容,感觉“这次写得还行,语言挺流畅的”。但当你将其部署到线上,新的问题又出现了。你陷入了困境:问题到底出在哪里?刚刚的修改是优化了还是损害了整体性能?
例如,你发现 Agent 在解释机器学习的“过拟合”时,举的例子过于学术,不够通俗。于是你给 Agent 一个指令:
...在解释复杂概念时,请使用日常生活的比喻...运行后,它确实用“为考试而背答案,而不是真正理解知识”来比喻过拟合,效果不错。但你很快发现,在生成“Pandas 数据筛选”的课程时,它也生硬地加入了一个不恰当的比喻,反而让简单的操作变得复杂难懂。
7.2 无法度量,就无从改进
你遇到的根本问题,在于缺少一个客观、可量化的标尺。一个最直接的想法,就是你目前正在做的:手动测试几个案例,凭主观感觉判断。但这种“感觉不错”的方式很快就会暴露其内在缺陷:
- 难以量化:“感觉更好”无法作为工程决策的依据。你无法知道这次改进比上次好了 10% 还是 20%。
- 缺乏标准:你今天认为“例子太复杂”,明天换一个心情,可能又觉得“内容有深度”。不同的测试者、不同的时间点,评测标准都可能发生偏移。
- 无法复现:你无法系统性地回归测试,确保新的改动没有破坏原有的良好表现。当你修复了“比喻不当”的问题后,无法保证之前一个“解释清晰”的优点没有被意外破坏。
为什么会这样?这要从 Agent 的工作方式说起。大模型的生成过程是概率性的,并且它本身缺乏一个“自检”机制。你对提示词的微小调整,可能会在复杂的系统中引发难以预测的“蝴蝶效应”。
既然凭感觉调试行不通,那你自然会想到另一种思路:建立一套系统性的评测框架,用数据而非感觉来驱动开发。这就像你在准备考试时,不能只靠“感觉学会了”,而是需要通过做模拟试卷来客观地检验自己的掌握程度。
这便是评测驱动开发 (Evaluation-Driven Development)。它将评测 (Evaluation) 从开发流程的末端,提升到了决定方向的核心位置。
这一理念基于三个环环相扣的原则:
- 评测,或者说你对“好坏”的品味,决定了产品能力的上限。
- 能够被度量的,才能被有效改进。
- 度量反馈越快、越准,改进的效率和效果就越高。
7.3 两种评测方法:从宏观到微观
为了构建有效的评测体系,你需要从两个维度来审视你的 Agent:端到端评测 (End-to-End Evaluation) 和 白盒化评测 (White-box Evaluation)。
7.3.1 评测方法一:端到端评测
端到端评测关注的是系统的最终输出。它回答了一个最重要的问题:“这个 Agent 生成的课程,对用户来说,好用吗?”
7.3.1.1 迭代式确立评估标准
对于复杂的 Agent 系统,你不可能在项目开始前就预设所有完美的评测指标。正确的做法是拥抱迭代,评测很重要,但更重要的是尽快开始:
- 快速构建:先搭建一个最小可用版本(MVP)。
- 观察问题:在真实场景中运行它,观察它在哪些地方会犯错。
- 总结关键:从这些错误中,归纳出当前阶段最需要优先评测的关键点,并将其转化为评测指标。
比如,你的课程写作 Agent 生成的第一版内容中,你发现代码示例经常缺少必要的
import语句,导致无法直接运行。这是一个明显的、高优先级的错误。于是,你便确立了第一个评测指标:"代码可运行性"——所有代码块必须是自包含且语法正确的。接着,你又发现 Agent 为了让语言更生动,滥用比喻,反而让核心概念变得模糊。于是,你增加了第二个评测指标:"解释清晰度",并明确要求避免不当比喻。
这个循环不断重复,你的评测体系会随着 Agent 的进化而愈发完善和精准。下图展示了这一完整的闭环流程:
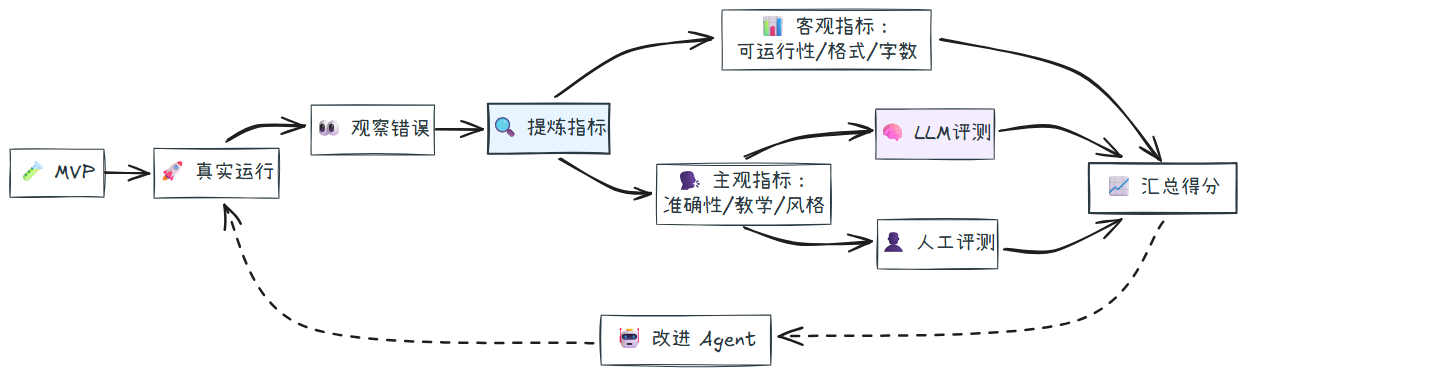
7.3.1.2 设计评估指标:客观与主观
一个全面的评测体系,需要同时包含客观指标和主观指标。
| 类型 | 描述 | “课程写作 Agent”案例 |
|---|---|---|
| 客观指标 | 可以通过代码规则直接判断,结果确定。 | • 代码可执行性:生成的代码片段能否用 Python 解释器成功运行? • 格式检查:是否包含了“痛点案例”、“解决方案”、“总结”等所有必需的章节? • 字数限制:每章节的篇幅是否在 300-500 字之间? |
| 主观指标 | 涉及语义、逻辑和质量,通常需要更强的智能来评判。 | • 内容准确性:对技术概念的解释是否存在事实错误? • 教学有效性:引入的案例是否能激发学习兴趣?解释是否由浅入深? • 语言风格:是否符合“严谨、精确、冷静”的课程设定? |
但这里的核心问题是:谁来定义这些指标?特别是主观指标,比如"教学有效性"和"语言风格",到底意味着什么?
关键在于,评测指标必须由你团队中最资深的业务专家来主导制定。 对于你的"课程写作 Agent"而言,这些人就是顶尖的课程设计师和资深讲师。但这里有一个常见的误区需要避免:
很多团队的做法是,技术人员先搭建好 Agent 的初版,发现效果不理想后,再去找业务专家"提取知识"——问他们"你觉得好的课程是什么样的?“然后技术团队回去尝试将这些模糊的描述翻译成评测规则。这种模式往往效率低下,因为:
- 专家缺乏参与动力:他们被定位为"知识提供者”,而非项目的共同建设者。没有看到与自身业务目标的直接关联,参与积极性不高。
- 知识转译损耗:技术人员很难完整理解专家的隐性知识,翻译过程中容易曲解或遗漏关键要素。
- 反馈周期长:等到技术团队实现后再回来验证,往往已经走了弯路,需要大量返工。
正确的做法是,从项目启动的第一天起,就让业务专家成为评测体系的设计者(owner),而技术团队扮演促进者(facilitator)的角色。具体来说:
用业务目标动员参与:不要说"我们需要你帮忙定义评测指标",而是说"这个 Agent 要帮助我们实现【具体业务目标,如’将课程制作周期从2周缩短到3天,同时保持90%以上的用户满意度’】,你作为课程质量的把关人,需要定义什么是’可接受的质量底线’"。当专家看到这直接关系到他们关心的业务成果时,参与意愿会大大提升。
提供结构化工具降低参与门槛:技术团队的价值在于提供脚手架,而非代劳。例如:
- 评测指标工作坊:组织专家进行结构化对话,用"如果你只能看三个指标就判断课程好坏,你会选哪三个?“这样的问题引导;
- 评分量表模板:提供"1-5分,每个分数对应的具体特征是什么"的填空模板,让专家填写而非从零开始描述;
- 案例标注工具:让专家直接在真实的 Agent 输出上标注"哪里好、哪里不好”,再反向提炼规则。
比如,当专家在一份教案上标注‘感觉太平淡’时,技术促进者需要追问:‘平淡’是指缺少了能引发共鸣的痛点案例吗?这样就能提炼出‘开篇案例相关度’这一指标。
当专家说‘学生会听不懂’时,继续深挖:是不是概念跳跃太快,比如没解释‘变量’就直接讲‘列表’?这又可以转化为‘理论递进逻辑性’的指标。
通过这种对话,你就能将专家的‘品味’编码成机器可以检查的评测项。
- 建立持续协作机制:评测标准不是一次性制定的文档,而是随着 Agent 能力和业务需求演进的活文档。每周回顾会上,专家看数据、技术团队调系统,双方共同决策下一步优化方向。
通过这种方式,专家不再是"被提取知识"的对象,而是评测体系的真正拥有者。他们的"教学直觉"(即"隐性知识",Tacit Knowledge)得以在结构化工具的辅助下,系统地转化为可执行、可迭代的评测规则。
7.3.1.3 提升主观评估的稳定性
定义好指标后,下一步就是如何执行评测。你有两种选择:人工评测和借助大模型自动评测 (LLM-as-a-Judge)。
人工评测:由人类专家根据评测标准打分。这是最可靠的“黄金标准”,尤其在项目初期,能为你校准“好”与“坏”的定义。但它的缺点是成本高、速度慢,难以大规模、高频率地进行。
大模型自动评测:训练或引导另一个大模型,让它扮演“评测专家”的角色,根据你定义的指标和评分细则,自动为“课程写作 Agent”的输出打分。
为了让大模型评测更稳定,你需要将一个模糊的评测目标(如“内容质量好”)拆解为一系列具体的、可检查的细则。然后,让大模型逐项判断,最后再根据规则汇总成分数。
例如,评测“课程写作 Agent”生成的“内容质量”,可以拆解为:
- 痛点引入:是否以一个日常、具体的痛点作为开篇?(是/否)
- 理论升华:是否清晰地指出了初步解法的局限,并引出了核心理论?(是/否)
- 代码示例相关性:提供的代码示例是否与讲解的理论紧密相关,且足够简化?(是/否)
但你必须警惕,大模型评测本身可能存在偏见。
扩展阅读:LLM 评测员的“思维定势”
使用大模型作为评测员,就像聘请了一位博学但带有个人偏好的专家。它自身的训练数据决定了它的"品味"。
- 风格偏见:它可能偏爱某种代码风格(如推崇链式调用),从而给其他同样正确但风格不同的代码打了低分。
- 长度偏见:它可能倾向于认为更长的、更详细的解释就是"更完整"的,从而不公平地惩罚了那些"简洁但切中要害"的答案。
- “好好先生"偏见:一些模型倾向于给出正面评价,避免冲突,导致难以发现真正的问题。
- 位置偏见:一些研究表明,模型在处理列表或对比多个选项时,可能会倾向于选择开头或结尾的选项。在设计评测 Prompt 时,可以考虑随机打乱被评测内容的顺序,以减轻这种偏见的影响。
因此,最佳实践是:在初期使用人类专家评测,建立一套高质量的"黄金测试集”。然后,用这个测试集来"校准"你的大模型评测员,检查它的打分与人类专家的一致性。在后续的开发中,定期用人工抽检的方式,确保自动评测系统没有"跑偏"。
7.3.2 评测方法二:白盒化评测
当你的 Agent 流程变得复杂,端到端评测的弊端就会显现。比如,你的“课程写作 Agent”可能包含一个“概念解释”组件和一个“代码生成”组件。如果最终课程的得分不高,你很难判断是概念解释得不好,还是代码示例太烂。
白盒化评测 (White-box Evaluation) 就是为了解决这个问题。它主张深入系统内部,为关键组件单独设计一套评测体系。
白盒化评测的核心优势在于:
- 清晰信号:提供无干扰的改进信号,让你能聚焦于真正的瓶颈。
- 快速迭代:只需测试单个组件,无需运行整个复杂流程,大大缩短了验证周期。
- 精准优化:无论是调整超参数还是更换外部服务,其效果都能被精准度量,让决策有据可依。
这样一来,你就可以:
- 单独评测“概念解释”组件:构建一个测试集,包含一系列技术术语(如“列表推导式”、“装饰器”),然后只评测该组件生成的文本解释是否清晰、准确。
- 单独评测“代码生成”组件:构建一个测试集,包含一系列任务描述(如“生成一个合并两个字典的函数”),然后只评测生成的代码是否能正确运行、是否遵循最佳实践。
这种方法的优势在于提供了无干扰的改进信号,让你能聚焦于真正的瓶颈,实现快速、精准的优化。
在实践中,你不必追求一开始就实现全自动、覆盖所有维度的复杂评测系统。比如,在处理代码正确性时,你可以从最简单的方法开始:手动复制几次代码运行一下。然后逐步升级到编写一个能自动执行代码并捕捉错误的脚本。最终,你可以构建一个包含多种指标(风格、效率、正确性)的完整评测流水线。最终的选择取决于你的具体需求、预算和可接受的错误率。
7.4 评测框架
你可以基于代码编写规则、结合 LLM,自行构建一套符合业务需求的评测工作流。当然,也可以借助社区成熟的评测框架来加速这一进程。除了 AgentScope 外,在 RAG 效果评测章节中提到的评测框架 RAGAS,同样也提供了 Agent 的端到端和组件级别的评测能力。此外,你也可以选择 DeepEval 作为大模型评测框架。
7.4.1 实践:AgentScope 评测框架演示
为了用最小代码跑通“评测驱动开发”的端到端示例,你需要了解以下模块:
- agentscope.evaluate:
Task(任务定义),MetricBase/MetricResult/MetricType(自定义指标),SolutionOutput(解的统一表示)。 - pydantic:用于定义结构化输出的模型,提升评测稳定性(让模型输出可解析的数值)。
- agentscope.init(可选):用于开启追踪(Tracing),将运行轨迹发送到 Studio 或 OTLP 兼容后端。
说明:面向教学的“最小可运行”版本不依赖
GeneralEvaluator/RayEvaluator等更完整的评测器;我们直接用Task + Metric组成一个紧凑的循环即可。如果你要跑大规模基准或分布式评测,再引入评测器与存储模块即可。
下面的示例演示“撰写 pandas 数据分析课程的课节草稿”,并对草稿进行可编程的客观打分。要点:
- 结构化输出(
title/learning_objectives/code_example/quiz),提升评测稳定性。 - 细粒度主观评分(LLM-as-Judge):按照 1-5 分评测五个维度——语言表达清晰度/歧义性、是否有事实错误、前后表达一致性、表达冗余度(冗余越少分越高)、易读性;使用结构化输出稳定评分。 Tracing(可选):设置
AGENTSCOPE_STUDIO_URL(连接 AgentScope Studio)或OTEL_TRACING_URL(连接任意 OTLP 兼容后端)即可自动开启追踪;未设置时示例照常运行。
最终,从依赖主观感觉,到建立“端到端”与“白盒化”相结合的评测体系,是构建高水平 Agent 的必由之路。这个过程,本质上是将模糊的“好坏”标准,转化为清晰、可执行的工程问题。评测并非开发的终点,而是优化的起点。一个强大的评测系统,将成为你探索 Agent 能力边界时,最可靠的指南针。
7.5 总结
让我们回顾一下你在本节学到的知识:
- 超越主观感觉:Agent 的优化应摆脱“感觉不错”的模式,转向基于客观数据的评测驱动开发,这是实现严谨、可控优化的前提。
- 专家定义标准:评测指标,特别是主观指标,应由资深业务专家主导制定,将他们难以言传的“隐性知识”转化为清晰、可衡量的规则。
- 警惕模型偏见:使用大模型进行自动评测时,必须警惕其固有的风格、长度等偏见,并通过人类专家的“黄金测试集”进行定期校准。
- 端到端与白盒化结合:通过端到端评测把握 Agent 整体的用户价值,同时利用白盒化评测深入关键组件,精确定位并解决性能瓶颈。
- 迭代完善:一个强大的评测系统是逐步演进的,而不是一蹴而就的。从最关键、最容易实现的部分做起,持续迭代。
8 总结
至此,你已经学完了本章节的全部内容。让我们一起回顾,并从一个更宏观的视角,为你刚刚构建起的 Agent 知识体系进行梳理。
8.1 一切始于“用户意图”
你从一个常见的痛点出发:单一的 LLM 调用,虽然能处理语言任务,但面对需要多步骤、与外部世界交互的复杂任务时,往往力不从心。
要解决这个问题,你的目标是构建一个能够稳定、可靠地理解并完成用户真实意图的系统。这正是 Agent 的价值所在。如果说 LLM 是一个聪明但被束缚在“黑盒”里的“大脑”,那么你这章所学的,就是如何围绕这个“大脑”,构建起一套完整的“工程系统”,让它能完成真实世界的复杂任务。
8.2 核心方法论:上下文工程 (Context Engineering)
在探索如何构建 Agent 的过程中,你学习了多种工程技术。现在,让我们从一个核心的工程思想上来审视这些技术:上下文工程 (Context Engineering)。
你最开始接触大模型时,学习的是提示词工程 (Prompt Engineering),它的核心是在单次交互中,通过精心设计的指令,让模型给出最佳输出。
而你现在面对的,是跨越多轮交互、涉及多个外部信息源的复杂任务。此时,你的工作重心就从“写好一段 Prompt”,升级为系统性地为模型的每一步决策,都提供最充分、最精准的“上下文”。这就是上下文工程。
从这个视角看,你作为 Agent 的设计者,就不再仅仅是一个“提问者”,而是一个“信息架构师”。你的核心任务,是通过设计流程、调用工具,为最终负责决策的 LLM 节点,构建出一个完美的“信息茧房”,其中包含了解决问题所需的一切信息,不多也不少。上下文的质量,直接决定了 Agent 的能力上限。
在“上下文工程”这一工程路线下,你在本章前半部分学到的这些能力,都有了清晰的定位:它们都是“上下文注入”这门学问中的具体手段:
- 工具使用 (Tool Use):向上下文中注入来自外部世界的实时、确定性信息。
- 反思能力 (Reflection):将上一步输出的“评估结果”作为新的反馈,修订下一步的上下文,以指导下一步的行动。
- 工作流 (Workflow):设计一条相对固定的任务流水线,规定在什么时机、由哪个节点向模型中注入什么样的上下文,就像一条专门“操作上下文”的流水线,驱动后续所有步骤稳定运行。
- 记忆系统 (Memory):从海量的历史信息中检索最相关的部分,注入当前上下文,为后续的决策提供参考。
这些能力并非孤立存在,而是共同服务于“优化上下文”这一核心目标,让 Agent 更高效、更可靠地完成任务。
8.3 质量保障:评测驱动的开发
既然上下文是核心,那么你如何确保自己构建的上下文是“高质量”的?答案是:评测。
没有测量,就没有优化。将 Agent 的开发过程从“凭感觉调试”变为“数据驱动”,是其能否在生产环境中落地的关键。为此,你学习了三个互补的评测维度:
- 端到端评测:它回答了最重要的问题:“Agent 是否最终完成了用户的意图?” 这是从业务视角出发的宏观评估。
- 白盒化评测:它能帮助你精准定位问题所在:“是工具调用失败了,还是记忆检索不准?” 这是深入系统内部,对每一个“上下文注入”节点的微观诊断。
- 持续迭代:将评测融入开发的每一个环节,形成一个由数据驱动、持续优化的闭环。这确保了 Agent 的能力能够随着业务发展和数据积累而不断进化。
通过建立起这样一套“宏观+微观+迭代”的评测体系,你就拥有了一个驱动 Agent 不断迭代优化的飞轮。更重要的是,这套体系并不局限于上下文工程,而是作为整个 Agent 系统的“反馈神经系统”,贯穿于后续的自主规划和多智能体协作。
8.4 展望:更强大的自主性
到目前为止,我们讨论的“上下文工程”,核心是围绕一个任务,构建一个“单兵能力”极强、行为边界清晰可控的 Agent。你已经掌握了让它使用各种工具、拥有记忆、学会反思的基础范式。这条以固定工作流为中心的工程化路线,已经非常强大,并且是当前业界最主流、最务实的落地范式。
但单个 Agent 的进化并未止步于此。其发展的下一个阶段,是赋予它更高的“自主性”:
- 自主规划 (Planning):Agent 不再严格执行你预设的静态工作流,而是能像一个项目经理,根据最终目标自主规划、拆解和执行任务。这意味着 Agent 拥有了动态适应问题、并自主生成解决方案的能力。
- 多智能体协作 (Multi-Agent Systems):在自主规划的基础上,更进一步的是让多个具备自主决策能力的 Agent 组成团队,让它们围绕共同目标自行分工、发起协作、交换信息和整合中间成果,而不是由你逐条写死协作流程。此时,系统的“自主性”不再局限于单个 Agent 的规划能力,而是通过多智能体之间的互动,被放大为一种更接近真实团队的群体智能。
这代表了 Agent 系统从以工程可控为主的模式,迈向更开放的自主性和涌现行为的一次跃迁。虽然你学到的结构化工作流是当前工程实践中最可靠的基石,但探索自主规划、多智能体协作等高级能力,将是解锁 Agent 下一阶段潜力的关键。
最终,你需要与时俱进。先将你学到的上下文工程和评测体系运用到实践中,构建出一个以固定工作流为骨架、行为可控且高度可靠的 Agent 工程系统。在此基础上,在同一套评测与反馈机制的护航下,逐步引入自主规划和多智能体协作,让系统在保证可控性的前提下,向更开放的自主性和涌现智能迈进。
最终总结
一个优秀的 Agent 系统,并非某种单一的先进技术,而是两条互补路线的结合:
- 工程化的可控自治路线:深入理解业务场景,将现实世界高效的流程与评价原则,转化为 Agent 的工作流与评测体系,并通过上下文工程精细控制每一个环节,在明确边界内发挥模型的“单兵能力”,构建起一个可靠、可控的 Agent 工程系统。这是战略与战术层面的“工程基座”。
- 开放式的自主进化路线:在这个工程基座之上,在同一套评测与反馈机制的约束和指引下,引入自主规划和多智能体协作,让 Agent 不再只是被动执行预设流程,而是能够围绕目标自行规划、分工协作并产生涌现行为,在保证可控性的前提下,逐步提升系统的整体智能上限。这是面向未来的“智能进化”。
掌握了这两条路线,你就具备了构建强大、可靠、且能够持续进化的智能系统的基础。现在,是时候用它们去实现你的创意,打造属于你的 AI 应用、系统和服务了。