前言
前面的课程中,介绍了如何搭建一个答疑机器人,并尝试通过优化提示词和构建RAG、扩展插件等方式提升其能力。不过你可能会发现,你一直在模型外围"打补丁"——这些方法本质上都是通过外部工具增强模型表现,而模型本身的知识边界和推理能力并未发生根本性改变。本节将带你走进大模型的"内功修炼场",通过微调(Fine-tuning)技术直接提升模型的底层能力。
当面对特定领域的深度需求时,比如小学数学题的精准解析,靠提示工程和 RAG 往往力不从心。针对题目中涉及的运算优先级规则、应用题单位换算逻辑等细节,模型需要掌握结构化的知识体系。此时,微调方法展现出独特优势——通过向模型提供小学数学教育专家精心设计的解题范例,模型能够学习专家的教学方法,掌握数学思维范式,并有效提升解题能力。
1. 任务设计
如何解决数学问题一直是大模型发展的一个重要方向,正好你的智能助手也需要具备基础计算能力。为了方便对模型进行微调,你可以选定一个小参数的开源模型qwen2.5-1.5b-instruct作为你的基准模型。
首先,你需要下载模型,并将其加载到内存中:
# 下载模型参数到 ./model 目录下
!mkdir ./model
!modelscope download --model qwen/Qwen2.5-1.5B-Instruct --local_dir './model'
from swift.llm import (
get_model_tokenizer, get_template, ModelType,
get_default_template_type
)
import torch
#你可以根据你的需要修改query(模型输入)
# 获得模型信息
model_type = ModelType.qwen2_5_1_5b_instruct
template_type = get_default_template_type(model_type)
# 设置模型本地位置
model_id_or_path = "./model"
# 初始化模型和输入输出格式化模板
kwargs = {}
llm, tokenizer = get_model_tokenizer(model_type, torch.float32, model_id_or_path=model_id_or_path, model_kwargs={'device_map': 'cpu'}, **kwargs)
llm.generation_config.max_new_tokens = 128
template = get_template(template_type, tokenizer, default_system='')
print("模型初始化完成")
可以直接试一试它在数学题上的效果(答案是:可收萝卜648千克):
from swift.llm import inference
from IPython.display import Latex, display
math_question = "在一块底边长18米,高6米的三角形菜地里种萝卜。如果每平方米收萝卜12千克,这块地可收萝卜多少千克?"
query = math_question
response, _ = inference(llm, template, query)
print(query)
print("正确答案是:可收萝卜648千克")
print('-----------大模型回答-------------')
display(Latex(response))
print('------------回答结束--------------')
可以发现似乎你的模型并不能很好的计算这个简单的数学问题,模型知道三角形的面积公式,但却无法利用知识准确计算出萝卜的重量。
当然使用RAG的效果是一样的,经过前面的学习,你知道RAG更像是开卷考试,但你从来没有见过数学考试开卷能提升成绩,因为提高数学能力的核心在于提高学生的逻辑推理和计算能力而非知识检索。
所以为了直接提升你答疑机器人在简单数学问题上的能力,你必须使用模型微调来提高模型的逻辑推理能力。(计算能力可以通过引入“计算器”插件来增强)
2. 微调原理
2.1 模型如何学习
2.1.1 机器学习 - 通过数据寻找规律
在传统编程工作中,你通常是知道明确的规则,并将这个规则编写成函数的形式,例如:。
其中 a 是已知的确定性值(也称为参数或权重)。这里的函数,就是一个简单的算法模型,它能根据输入来计算(预测)输出。
然而实际情况中,你更有可能事先不知道明确规则(参数),但可能知道一些现象(数据)。
机器学习的目标,就是帮助你通过数据(训练集),来尝试找到(学习)这些参数值,这一过程被称为训练模型。
2.1.2 Loss Function & Cost Function - 量化评估模型表现
要找到最合适的参数,你就需要有办法来度量当前所尝试的参数是否合适。
为了更好理解,可以假设你现在需要评估模型中的参数 a 是否合适。
Loss Function 损失函数

Cost Function 代价函数
为了评估模型在整个训练集上的表现,你可以计算所有样本的损失平均值(即均方误差,Mean Squared Error,MSE)。这种用于评估模型在所有训练样本上的整体表现的函数,被称为 Cost Function(代价函数,或成本函数)。

有了 Cost Function,寻找模型合适的参数的任务,就可以等效为寻找 Cost Function 最小值(即最优解)的任务。找到 Cost Function 的最小值,意味着该位置的参数 a 取值,就是最合适的模型参数取值。
如果将 Cost Function 绘制出来,寻找最优解的任务,其实就是寻找曲线或曲面的最低点。
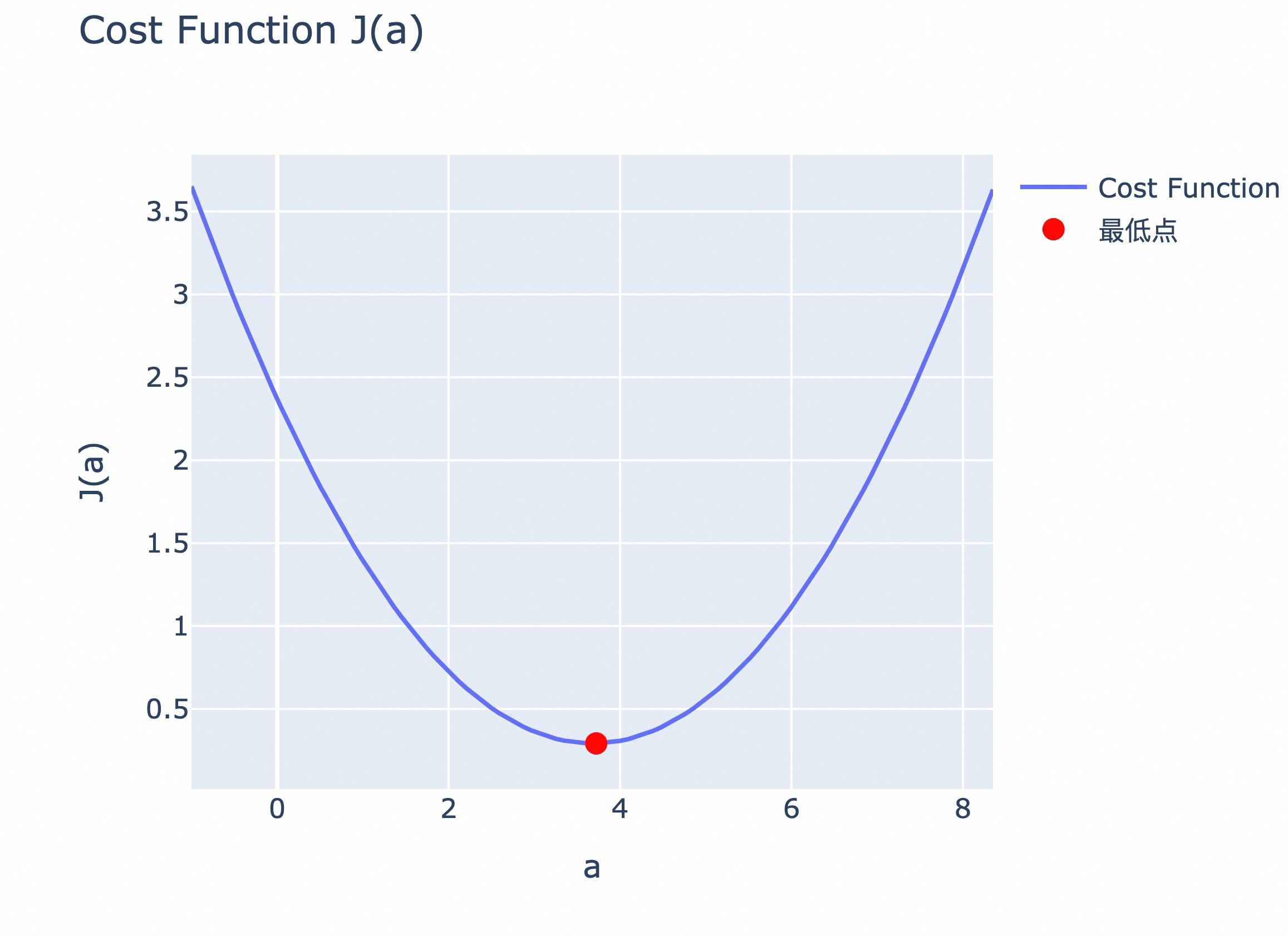
实际项目中,人们经常会将代价函数、损失函数两个概念混用,在后续内容中的代码,我们也会沿用这一工程习惯,将代价函数称为损失函数(loss function)。
2.1.3梯度下降算法 - 自动地寻找最优解
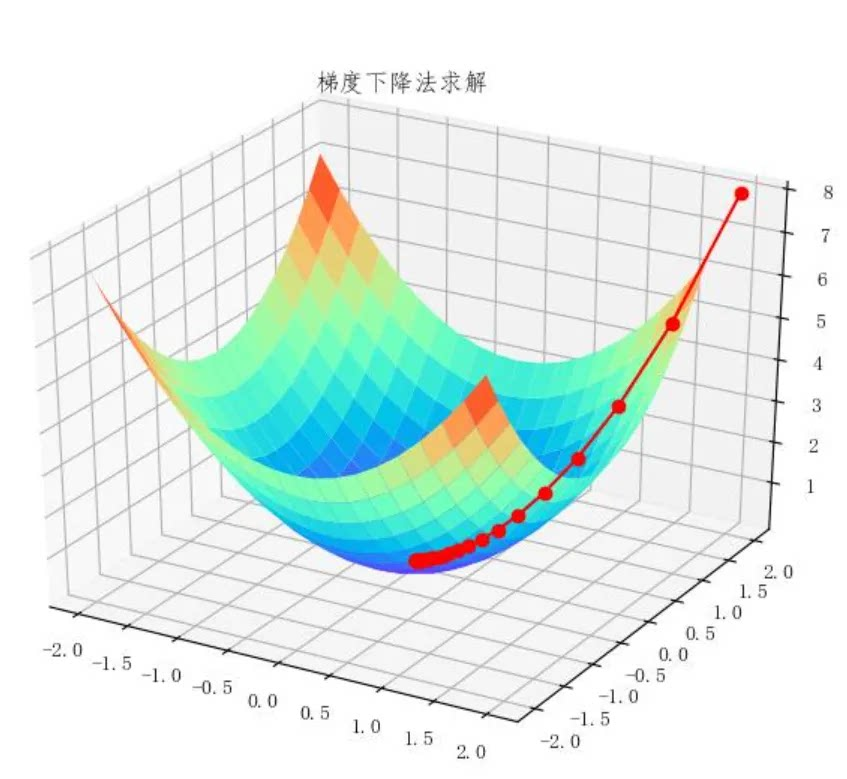
在前面的曲线中,你可以肉眼观察到最低点。但在实际应用中,模型通常参数很多,其 Cost Function 通常是高维空间中的复杂曲面,无法通过直接观察来找到最优解。因此,你需要一种自动化的方法,来寻找最优参数配置。
梯度下降算法是最常见的方法之一。一种常见的梯度下降算法实现是,先在曲面(或曲线)上随机选择一个起点,然后通过不断小幅度调整参数,最终找到最低点(对应最优参数配置)。
训练模型时,你需要训练程序能自动地不断调整参数,最终让 Cost Function 的值逼近最低点。所以梯度下降算法,需要能自动地控制两点:调整参数的方向,以及调整参数的幅度。
调整参数的方向
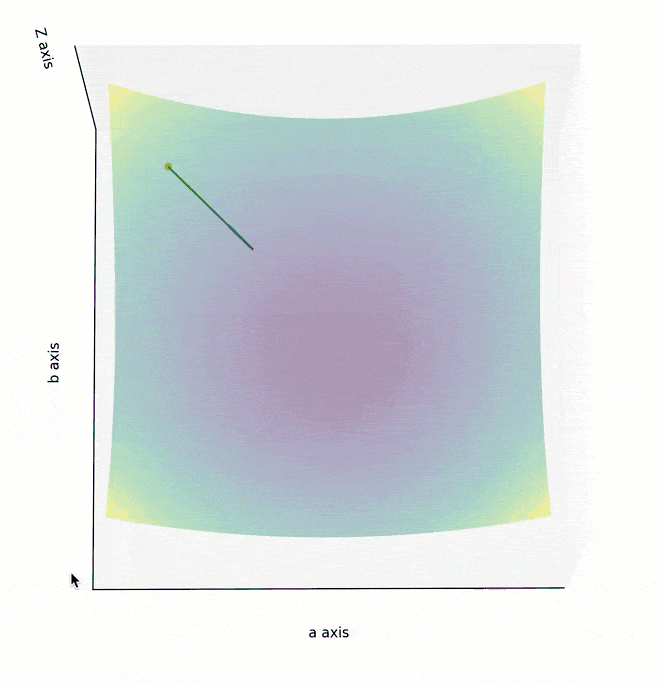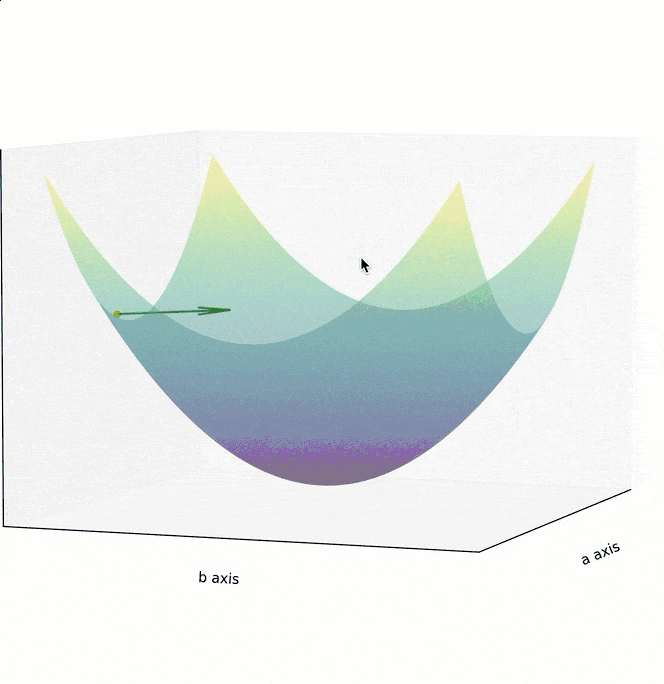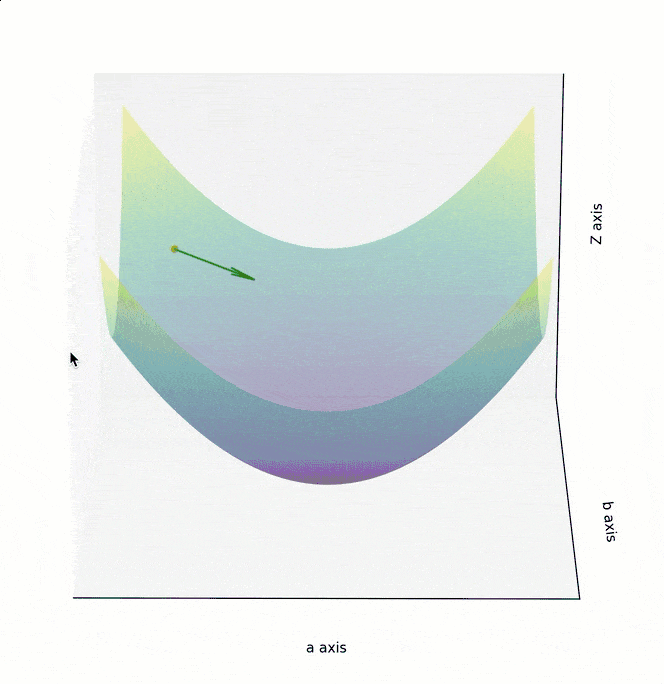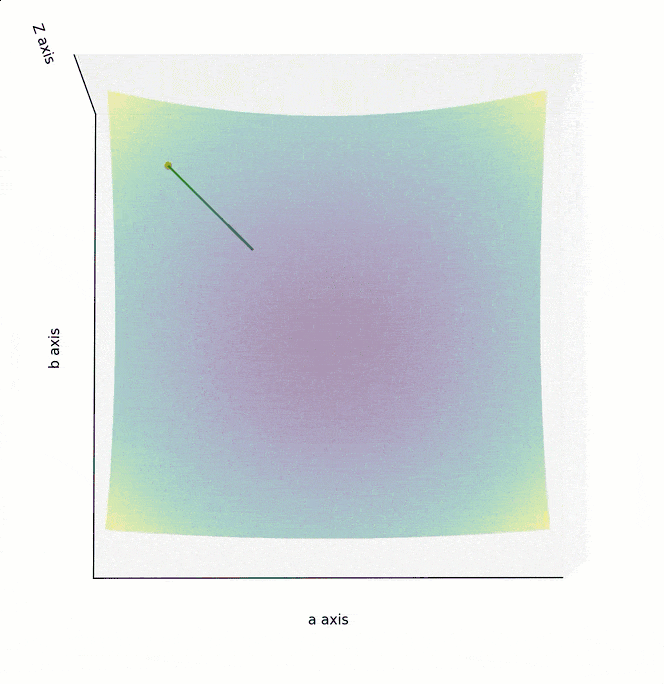
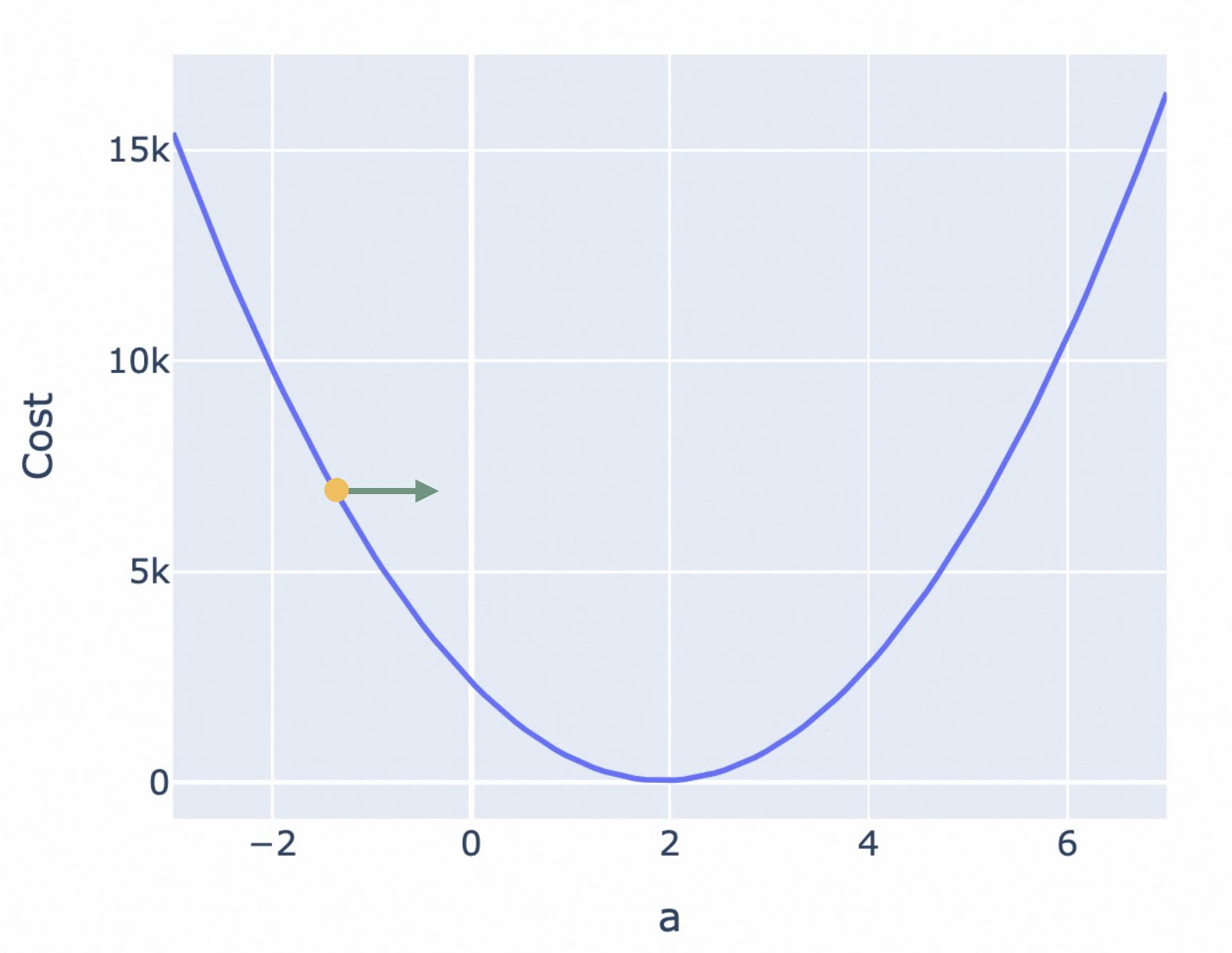
如果 Cost Function 是一条如下图所示的 U 型曲线,可以很直观地看到,最低点位于曲线平坦区的最中心,参数的调整应该是朝曲线斜率绝对值变低的方向,也就是越来越平坦的方向。
如果 Cost Function 是一个如下图所示的,三维坐标系下的曲面,最低点位于曲面“碗底”中心点。为实现最高效的下降,在曲面的任意点上,都不应随意选择下降的方向,而应该找到该点最陡峭的上升方向,并沿着其相反的方向进行参数调整,也就是朝着越来越平坦的“碗底”中心点位置移动。
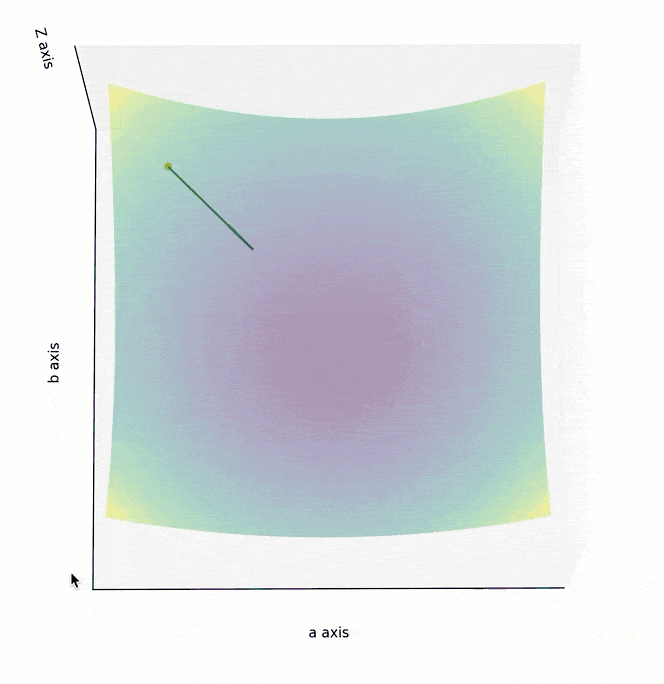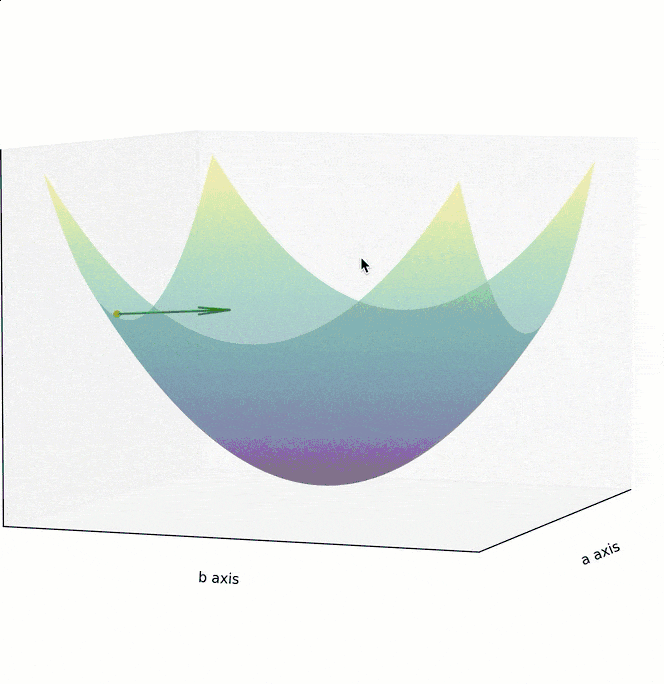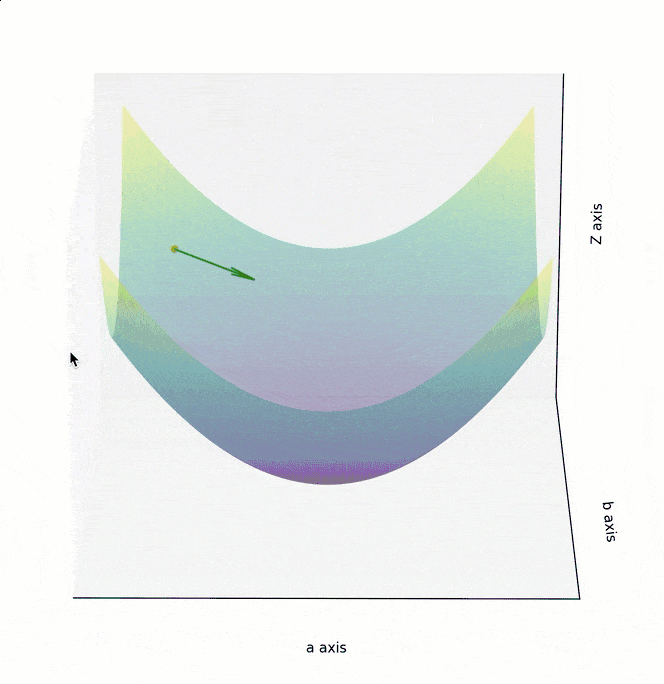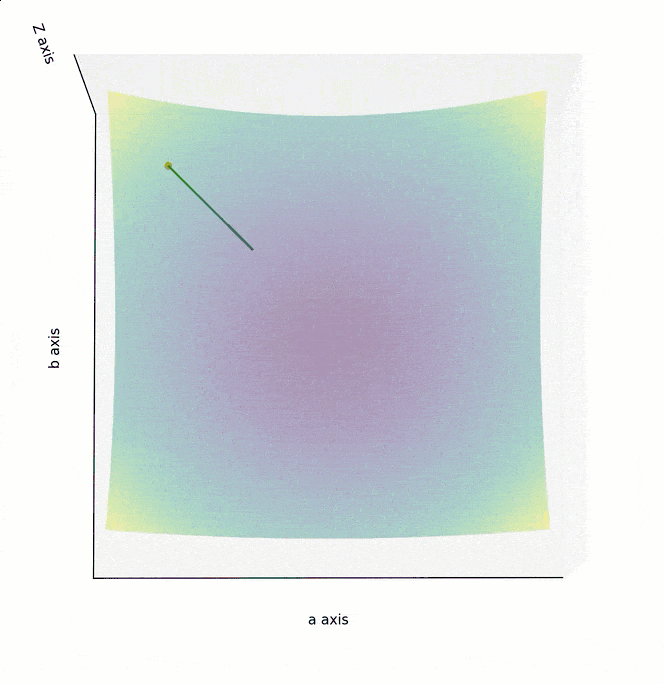
在数学中,梯度指向了以曲面上的某个点为起点,上升最快的方向,其反方向则是下降最快的方向。
为了在最短时间内找到曲面最低点,调整参数的方向,应该朝着梯度的反方向,也就是上面两个图中的绿色箭头方向。
对于二维坐标系的曲线 f(a),某点的梯度就是该点的斜率。
对于三维坐标系里的曲面 f(a,b),某点的梯度是由该点在 a、b 轴方向上的斜率值组成的二维向量。这表明了函数在各个输入变量方向上的变化率,并指向了增长最快的方向。计算曲面上一个点在某一个轴方向上的斜率的过程,也被称为求偏导。
调整参数的幅度
确定了调整参数的方向后,需要确定调整参数的幅度。
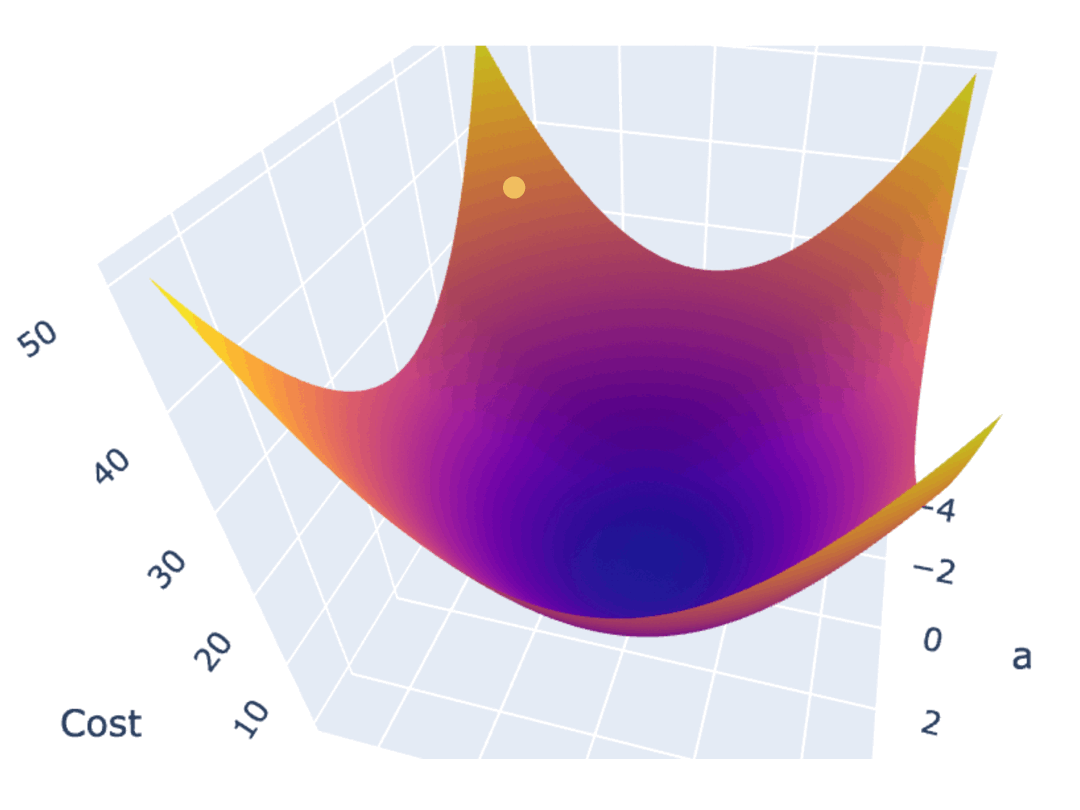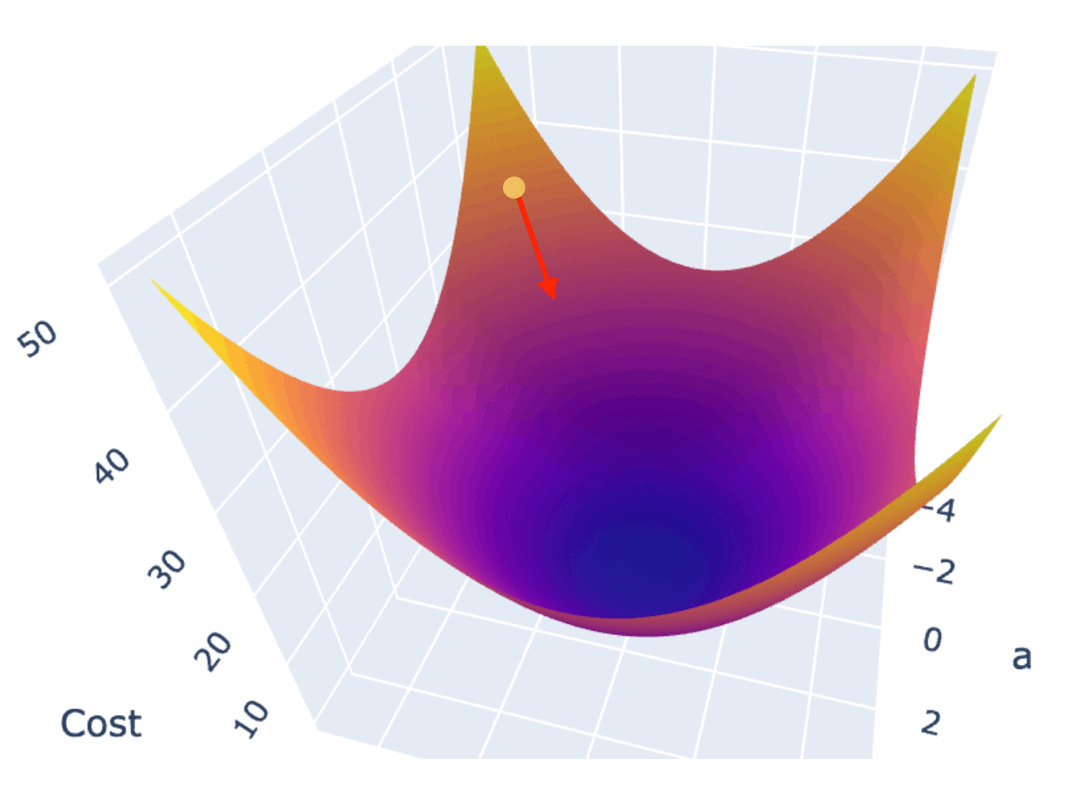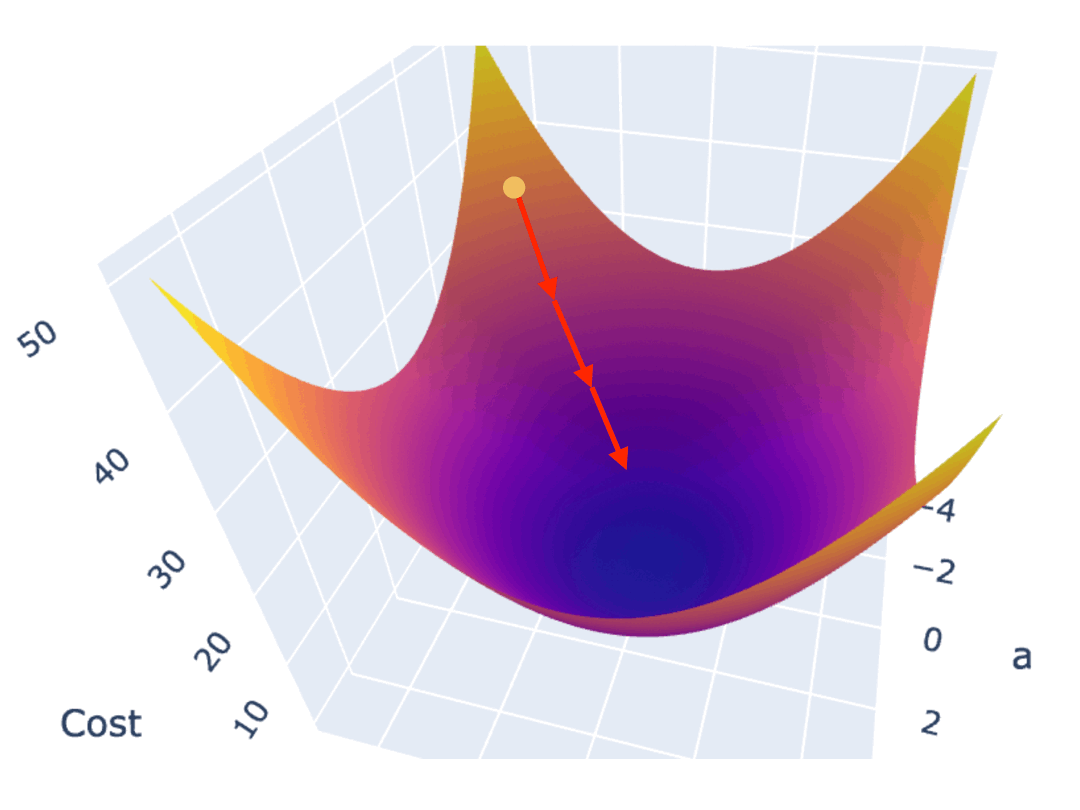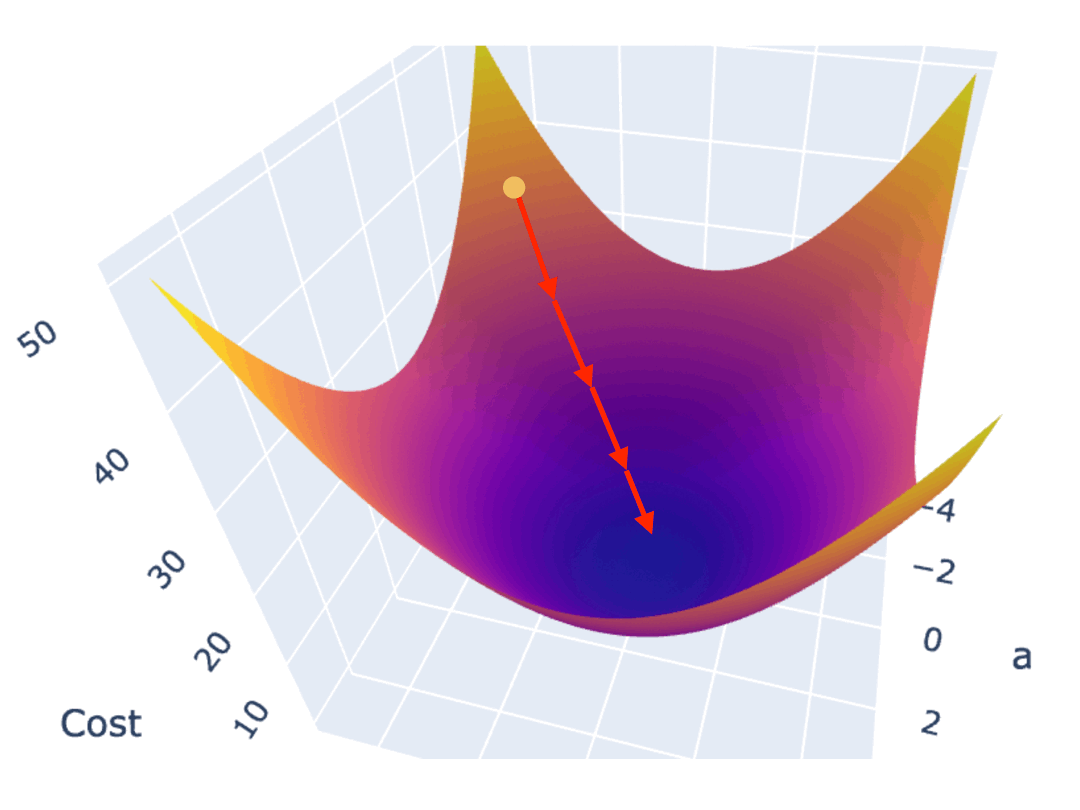
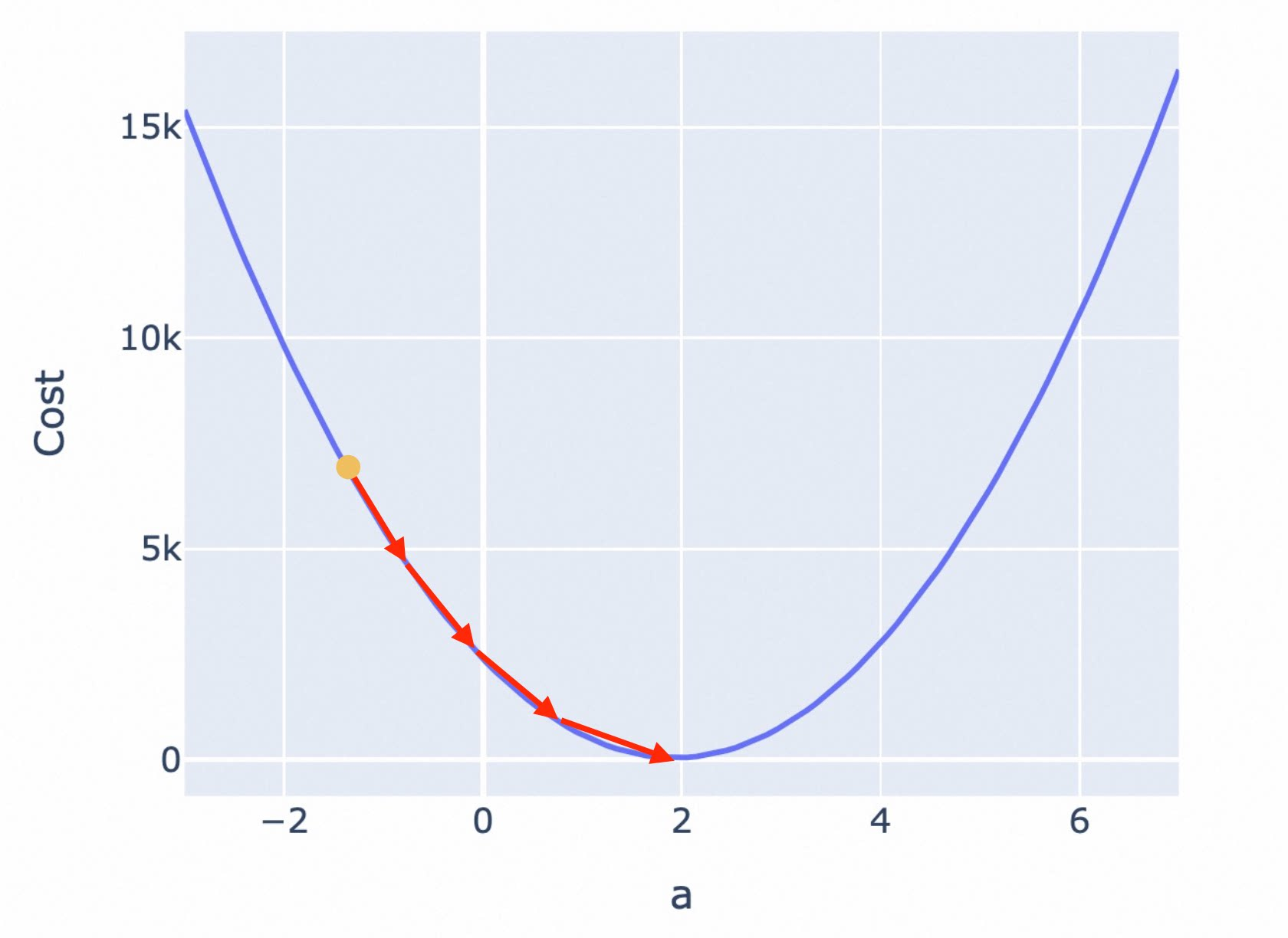
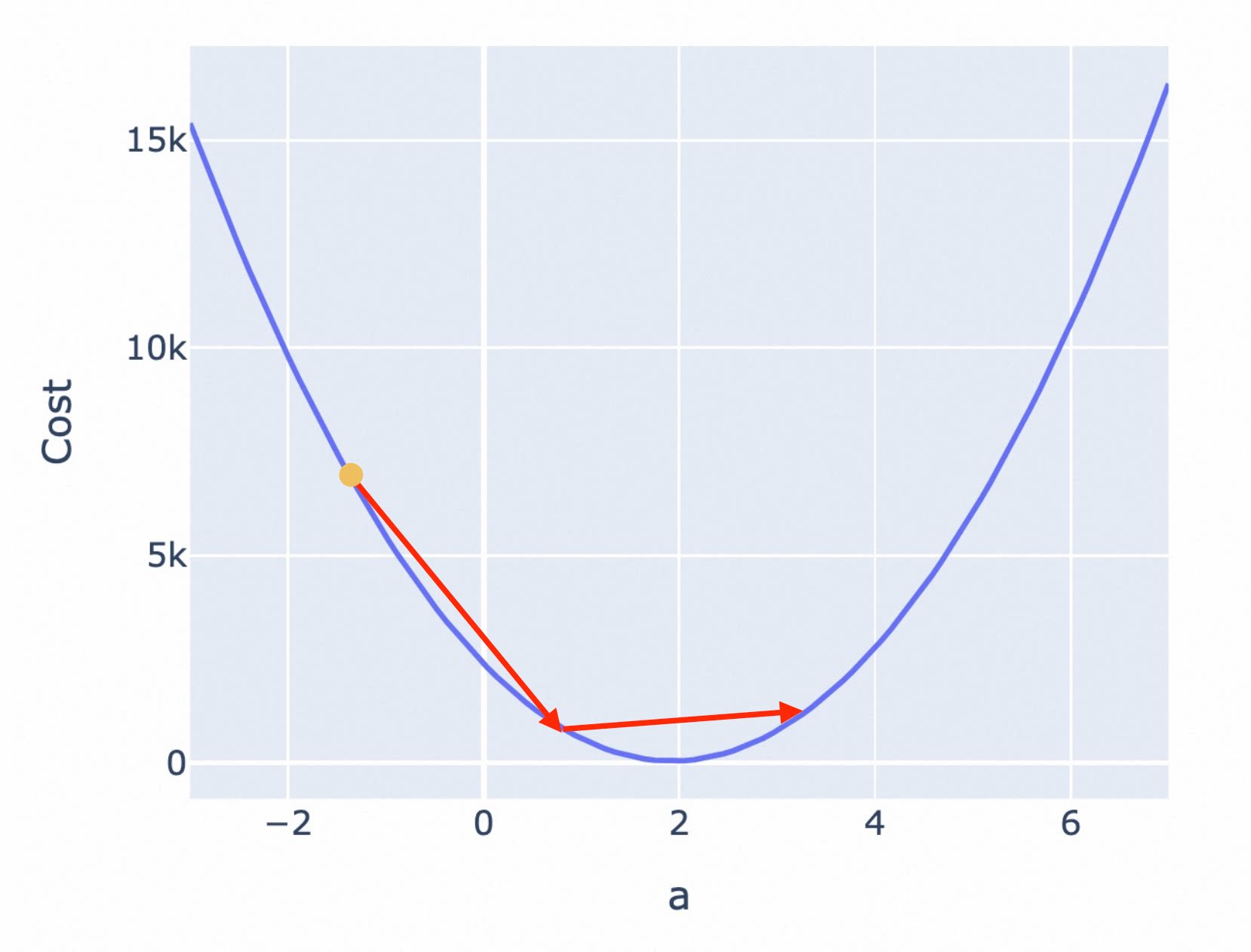
按照固定步长调整参数,是最容易想到的办法,但这可能会导致你始终无法找到最低点,而是在最低附近震荡。
比如下图,你按照固定步长为 1.5 来调整参数,就会出现在最低值附近反复震荡,无法进一步逼近最低点的情况。
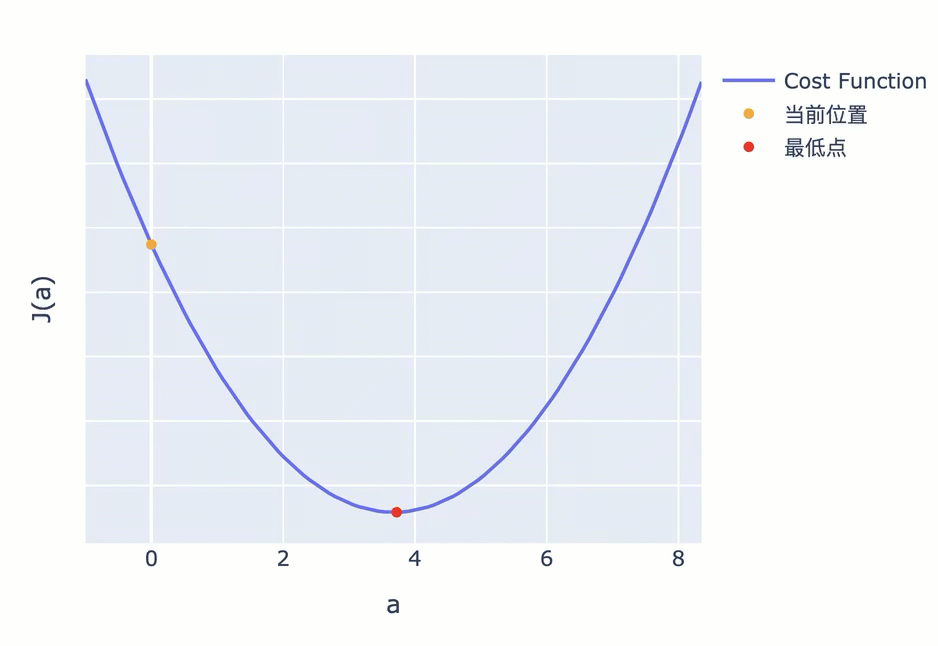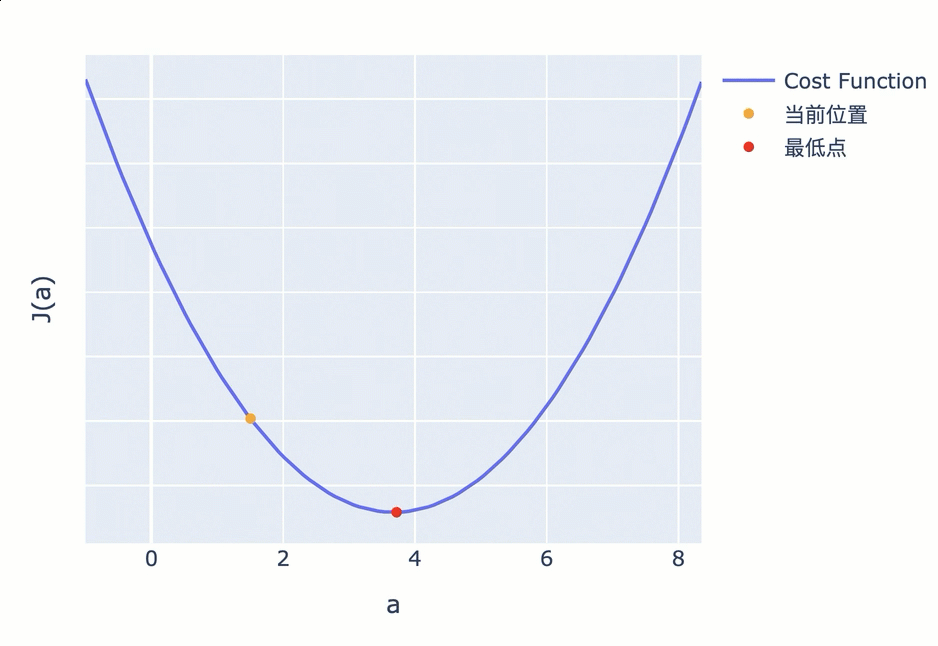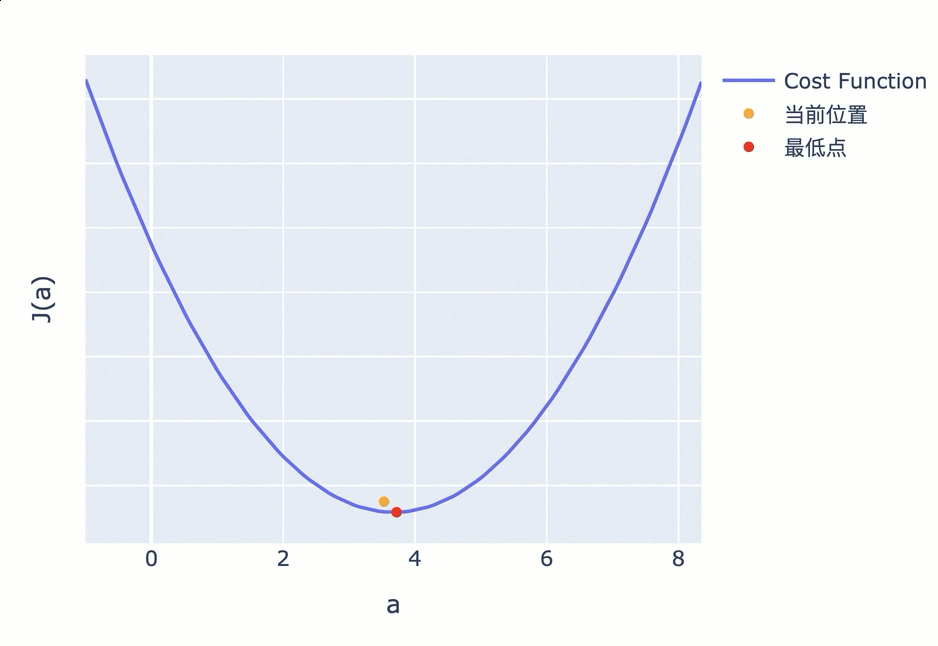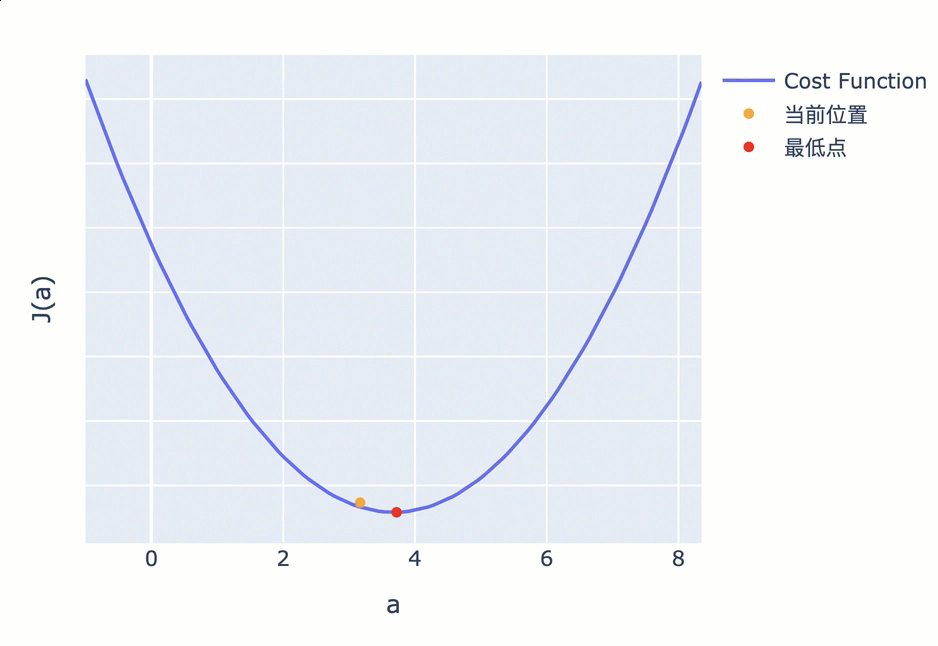
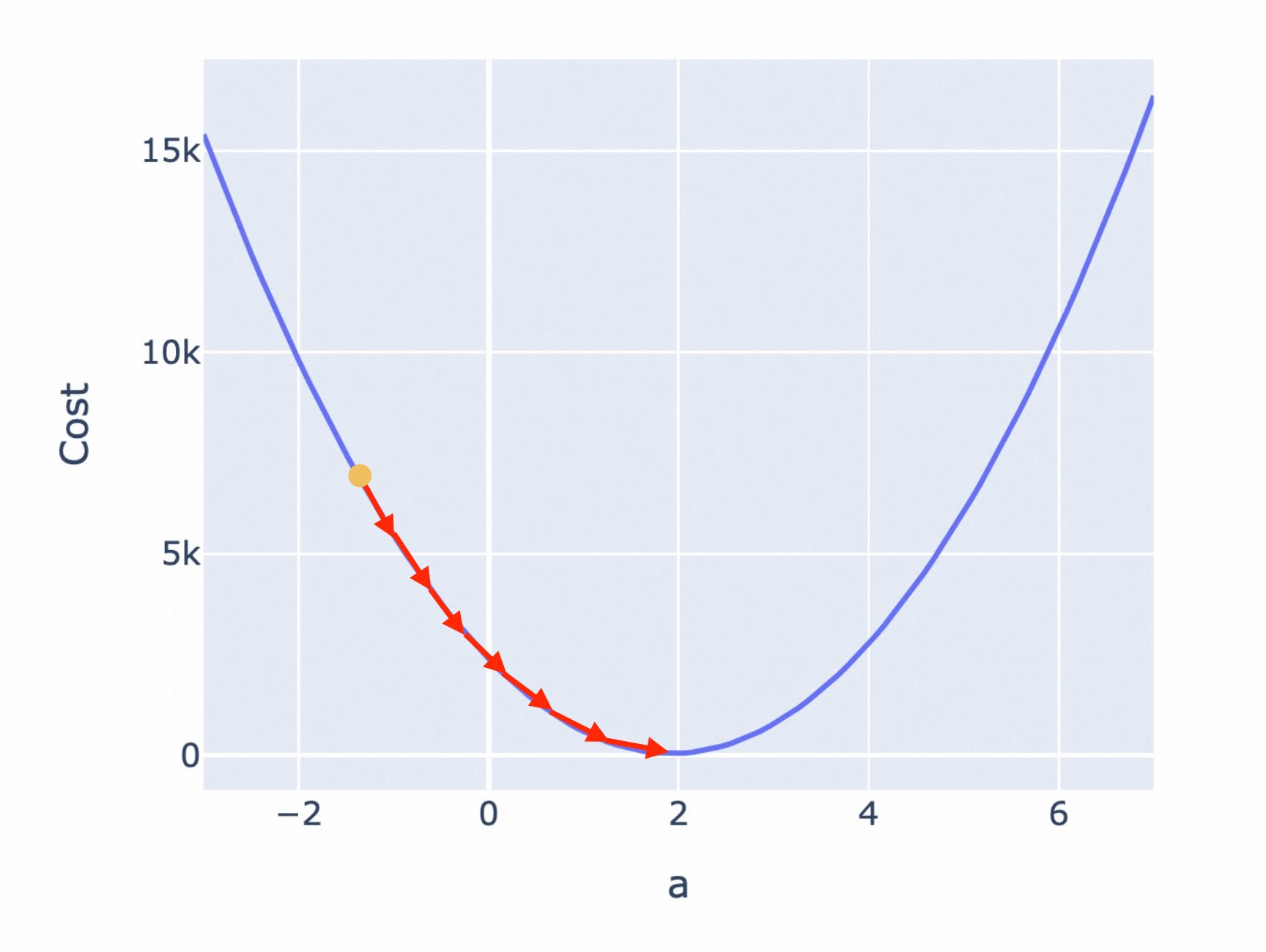
为了避免这一问题,接近最低点时,应该调低调整幅度。越接近最低点,斜率会越小,因此你可以不再使用固定步长,而是使用当前位置的斜率作为调整幅度。
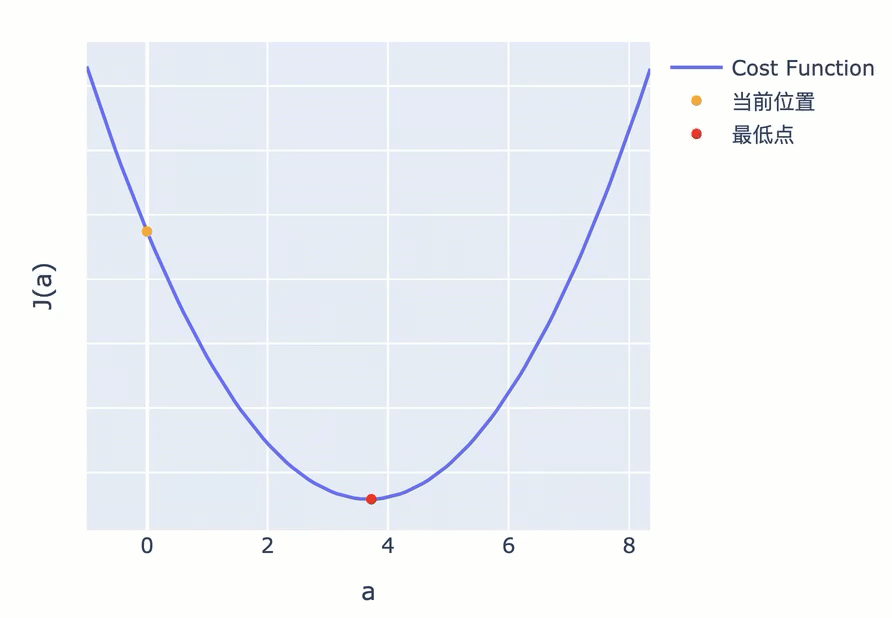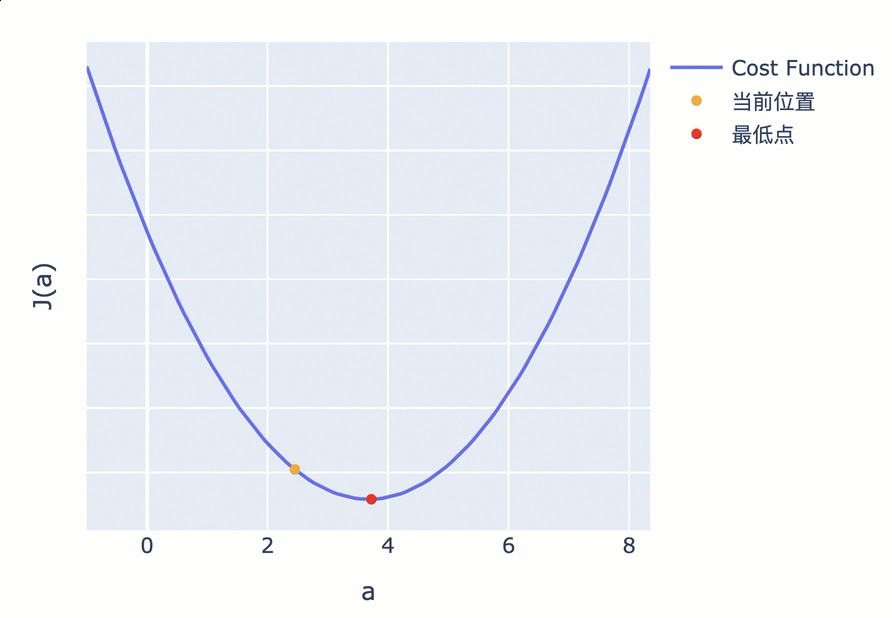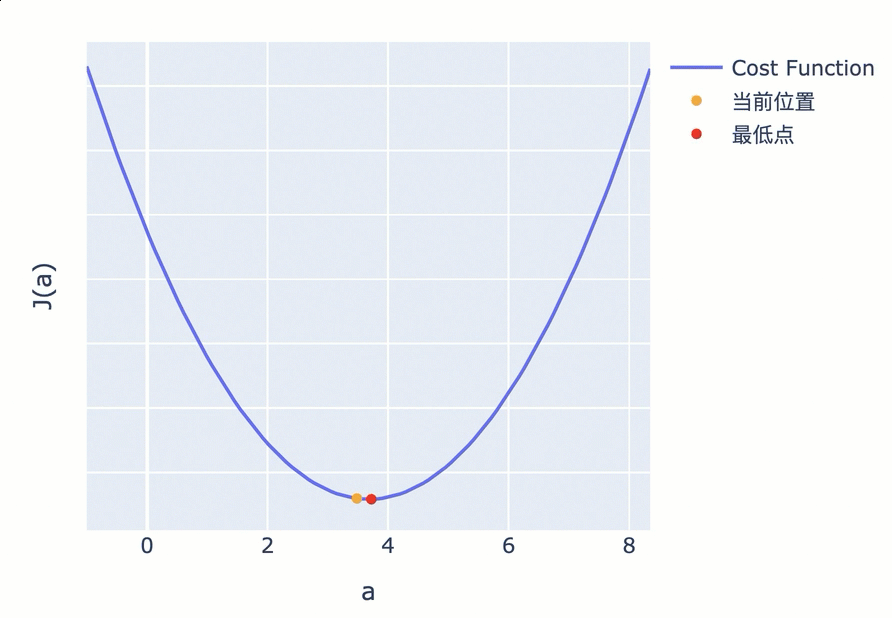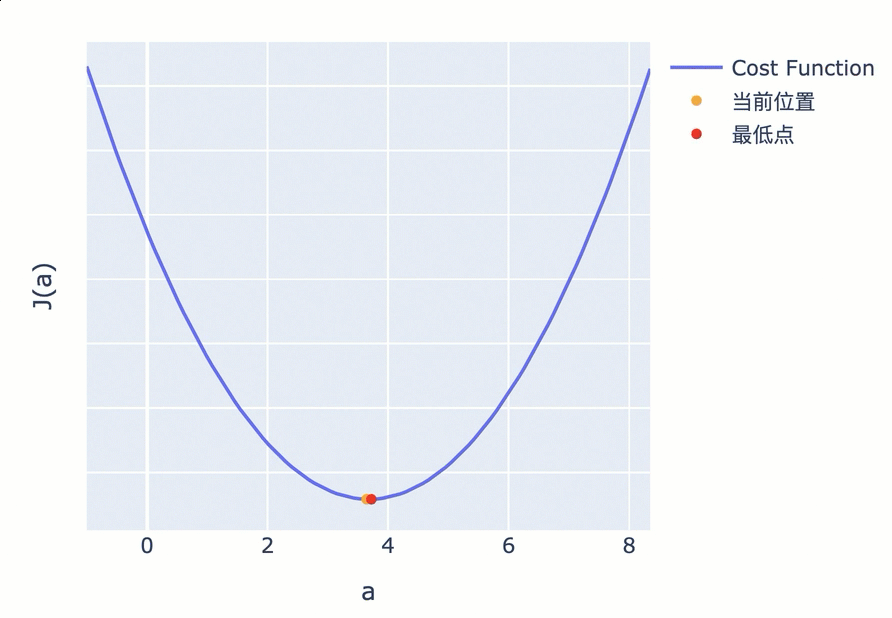
但也有些 Cost Function 曲线非常陡峭,直接使用斜率也可能导致你跨过最低点反复震荡。为此,你可以使用斜率的同时,对斜率乘以一个系数,来调节步长。这个系数,被称为 Learning Rate(学习率)。
Learning Rate 的选择,对于训练效果和效率尤为重要:
较小的学习率,虽然会让你耗费很多计算资源和时间,但其实有助于你更加逼近最低点。实际的模型训练工程中,也会尝试动态地调整学习率。比如百炼的模型微调功能中,提供了学习率调整策略 ,它允许你配置学习率线性递减、或者按照曲线来递减。阿里云的 PAI 还提供了 AutoML 工具,它可以帮助你自动找到更合适的 Learning Rate。
2.1.4 更多模型训练工程中会用到的参数
batch size
在寻找 Cost Function 最低点的过程中,每一次计算梯度(各方向上的斜率),然后根据该梯度更新模型参数,准备进行下一次计算和更新的过程,被称为一个训练步骤(training step)。
前文的介绍中,每个训练步骤是计算某一个点的梯度,然后进行参数更新。你也可以将 batch size 设置为 n ,基于 n 个样本(mini-batch)平均梯度,进行参数更新。
较大的 batch size 能加速训练过程,但对资源消耗也会更大,同时过大的 batch size 也可能导致模型泛化性能下降等问题。
选择合适的 batch size 是一个权衡的过程,它取决于可用的硬件资源、训练时间和期望的模型性能等因素。实践中,通常也需要通过实验来确定最适合特定任务的 batch size。
eval steps
因为训练集通常数量很大,人们通常不会在对训练集进行完整的迭代后,再使用验证集做评估(evaluation),而是会选择每间隔多少个训练步骤,就用验证集进行一次评估。这个间隔步骤数,通常是通过 eval_steps 参数来控制。
epoch
对训练集进行一次完整的迭代,被称为一个 epoch。实际训练过程中,你并不能保证在一个 epoch 内就一定能找到 Cost Function 的最优解(最低点),所以很多训练框架会支持配置训练轮次,如训练框架 swift 中提供的 num_train_epochs 参数。
过小的 epoch 值可能会导致训练结束时,还没有找到最优模型参数。过大的 epoch 值会导致训练时间过长以及资源浪费。
寻找合适的 epoch 的常见方法是早停法(Early Stopping):在训练启动前,并不预设一个 epoch 值(或者设置一个较大值),然后在训练过程中,定期使用验证集评估模型表现。当模型在验证集表现不再提升(或者开始下降)时,自动停止训练。
当然,早停法并不是唯一的解法,业界还有很多其他方法,来确定合适的 epoch 值,如动态调整学习率,根据验证集损失的变化来决定学习率的增减,从而间接影响训练的 epoch 数。
当空间中出现多个极小值时, 就需要很多次的迭代才能找到最优解
2.1.5 神经网络–万能复杂函数逼近器
机器学习面临的问题:
在文本生成任务中,输入X和输出Y一般都有非常多的维度,你无法直接看出他们之间的规律,该怎么办?
聪明的数学家们找到了一个万能函数逼近器——神经网络(多层),它也成为了当前复杂机器学习任务的基础。
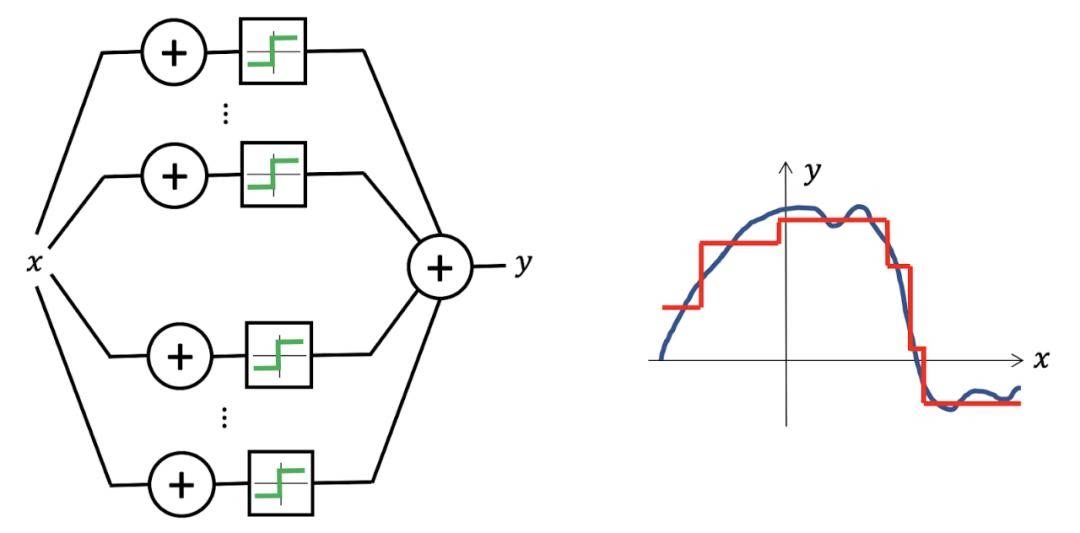

现在你已经有了王牌组合:
能够逼近任意复杂函数的工具——神经网络 + 能够拟合数据规律、学习函数参数的方法 ——梯度下降法
2.2 高效微调技术
2.2.1 预训练与微调
通过前面的学习,你已经了解了模型训练的本质,是寻找最合适的参数组合。
你在最开始下载好的模型,就是预训练好的参数组合。
微调则是在此基础上,进一步训练调整参数,以适应你的目标任务(比如这里的解数学题)。
在实际的模型训练过程中,还面临一个挑战:标注数据的获取成本高昂,尤其是对于特定任务(如医学图像分析或小众语言处理)。你可以尝试对模型进行“预训练”和“微调”分步训练,其中:
预训练:在一个大规模通用数据集上训练模型,使其能够学习到广泛的基础知识或特征表示。这些知识通常是通用的,不针对任何具体任务。预训练不针对特定任务,而是为各种下游任务提供一个强大的初始模型。典型的预训练模型:Qwen2.5-Max、DeepSeek-V3、GPT-4等。
微调:在预训练模型的基础上,使用特定任务的小规模数据集对模型进行进一步训练。其目的是让模型适应具体的下游任务(如医疗、法务等专业领域需求)。
下表展示了预训练与微调的主要区别:
| 特性 | 预训练 | 微调 |
|---|---|---|
| 目标 | 学习通用特征 | 适应特定任务 |
| 数据 | 大规模通用数据 | 小规模任务相关数据 |
| 训练方法 | 自监督/无监督 | 有监督 |
| 参数更新 | 所有参数可训练 | 部分或全部参数可训练 |
| 应用场景 | 基础模型构建 | 特定任务优化 |
值得一提的是,预训练一般通过自监督/无监督方式学习 ,学习的数据来自互联网上的海量文本(如维基百科、书籍、网页),让模型自己从数据中找规律或“猜答案。” 这种学习方式因为其数据无需人工标注,省去了大量人力成本,天然适用于海量数据的学习。
而微调通过有监督学习 ,需要针对特定任务的小规模标注数据(如情感分类的标注评论、医疗文本的标注数据),并用标注数据直接教模型完成任务。这种学习方式由于人工标注成本高,难以扩展为海量数据,因此更适合有明确场景目标的模型训练,所需要的样本数量通常只有几千或几万条。
因此,你可以通过如下方式 快速、低成本 地构建自己的大模型应用:
第一步:直接选择预训练模型(如Qwen、DeepSeek、GPT),这样可以节省从零训练一个模型的综合成本。
第二步:根据自己的实际场景,微调模型,通常只需要构建几千条适用于实际场景的标注数据,因为训练数据总 Tokens 数大大降低,使得训练时间有效缩减,从而进一步降低训练成本。
通过微调可以缩短训练时间,但是微调模型对显存的需求是否也能降低呢?
模型参数量是影响显存需求的主要原因,从调整参数量的大小这个角度,可以把微调分为全参微调与高效微调。
全参微调(Full Fine Tuning) 是在预训练模型的基础上进行全量参数微调的模型优化方法,也就是在上边的模型结构中,只要有参数,就会被调整。该方法避免消耗重新开始训练模型所有参数所需的大量计算资源,又能避免部分参数未被微调导致模型性能下降。但是,大模型训练成本高昂,需要庞大的计算资源和大量的数据,即使是全参数微调,往往也需要较高的训练成本。
高效微调技术(PEFT) 通过调整少量参数,显著降低大模型微调的计算成本,同时保持性能接近全参训练。典型方法包括Adapter Tuning、Prompt Tuning 和 LoRA。其中,LoRA 因仅需训练适配的小参数矩阵(即低秩矩阵,仅需原模型0.1%-1%的参数),成为资源受限场景下的首选方案。以下重点解析 LoRA 如何以极低参数量实现高效微调。